TD-Pipe: Temporally-Disaggregated Pipeline Parallelism Architecture for High-Throughput LLM Inference
Abstract: As the model size continuously increases, pipeline parallelism shows great promise in throughput-oriented LLM inference due to its low demand on communications. However, imbalanced pipeline workloads and complex data dependencies in the prefill and decode phases result in massive pipeline bubbles and further severe performance reduction. To better exploit the pipeline parallelism for high-throughput LLM inference, we propose TD-Pipe, with the key idea lies in the temporally-disaggregated pipeline parallelism architecture. Specifically, this architecture disaggregates the prefill and decode phases in the temporal dimension, so as to eliminate pipeline bubbles caused by the phase switching. TD-Pipe identifies potential issues of exploiting the novel architecture and provides solutions. First, a hierarchy-controller structure is used to better coordinate devices in pipeline parallelism by decoupling the scheduling from execution. Second, the AI-based greedy prefill approach aggressively performs more prefills by predicting the output length and simulating the memory usage. Third, the inter-batch work stealing approach dynamically balances decode phase workloads between different batches to reduce bubbles. Forth, the spatial-temporal intensity comparison approach determines the optimal switch from decode to prefill by comparing the performance drop from reduced computational intensity with that from phase switching bubbles. Extensive experiments show that TD-Pipe effectively increases the throughput of LLM inference by up to 1.91x over the existing tensor parallel approach and 2.73x over the existing pipeline parallel approach on GPU nodes with only PCIe interconnection.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces TD-Pipe, a new way to run LLMs faster on multiple GPUs when you care about processing lots of text (high throughput) instead of fast replies to single users (low latency). The main idea is to organize the work so GPUs spend less time waiting and more time doing useful work.
What problem are they solving?
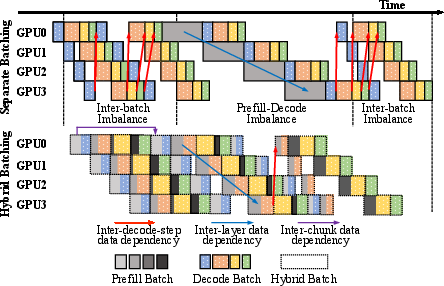
LLMs are huge and need a lot of memory. Running them on one GPU often isn’t enough, so people spread the work across several GPUs. A popular strategy called “pipeline parallelism” splits the model into stages (like stations on a conveyor belt). But in practice, these pipelines often have “bubbles”—idle gaps where some GPUs wait for others—wasting time and reducing speed.
The authors ask: How can we keep GPUs busy and avoid these bubbles, especially on regular hardware that doesn’t have fancy, fast GPU cables?
Key questions, in simple terms
The paper is trying to answer:
- How can we organize LLM work across multiple GPUs so there’s less waiting and more doing?
- When should we switch from “prefill” (processing the input prompt) to “decode” (generating tokens one by one)?
- How do we balance work across different batches so no GPU gets stuck with too much or too little?
- Can we safely predict how long outputs might be to avoid running out of memory?
- How can we coordinate many devices without making them block and wait for each other?
How does TD-Pipe work?
Think of the LLM as an assembly line:
- Prefill is like prepping lots of parts at once (it’s heavy, fast, and very parallel).
- Decode is like finishing items one by one (slower and more memory-focused).
- Bubbles are the times when a station waits because the previous station hasn’t delivered anything yet.
TD-Pipe introduces a “temporally disaggregated” pipeline: instead of constantly mixing prefill and decode, it runs lots of prefills together, then lots of decodes together, switching phases less often. This reduces the stop-and-go behavior that creates bubbles.
To make this work smoothly, the paper adds four simple ideas that help the assembly line:
- A hierarchy-controller structure: Like a coach (central controller) and players (GPU workers). The coach decides the plan and the players execute it without blocking each other. This separates scheduling (deciding what to do) from execution (doing it), so communication is smoother.
- AI-based greedy prefill: Before switching to decode, TD-Pipe tries to perform as many prefills as possible. It uses a small predictor to guess how long each output will be (based on the input), then simulates future memory use to avoid overflowing GPU memory. This lets it pack more work into the pipeline safely.
- Inter-batch work stealing: During decode, some requests finish earlier than others, so some batches shrink and others stay big. TD-Pipe moves extra requests from heavier batches to lighter ones, keeping the workload balanced across GPUs and reducing idle time.
- Spatial-temporal intensity comparison: When deciding whether to switch from decode back to prefill, TD-Pipe compares two “scores.” One score says how efficient decode is right now (spatial intensity). The other score estimates how much idle time switching would cause (temporal intensity). It switches only when that trade-off is good.
What did they find?
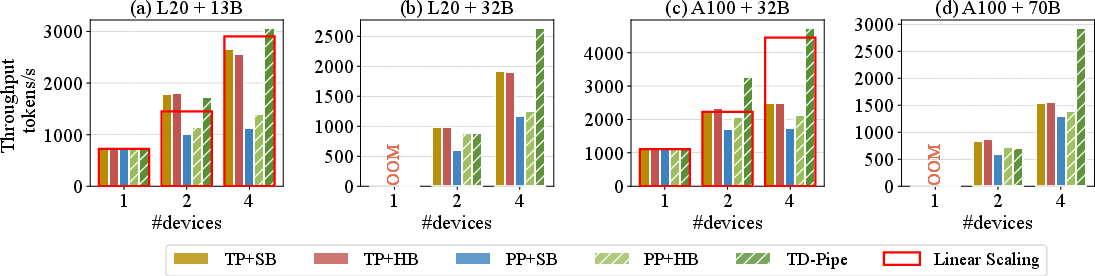
The authors tested TD-Pipe on two GPU servers and several LLMs (like Llama 2 and Qwen). Key results:
- TD-Pipe achieved up to 1.91× higher throughput than a common “tensor parallel” method.
- It also beat standard pipeline parallel methods by up to 2.73×.
- As they added more GPUs, TD-Pipe sometimes scaled better than expected (super-linear speedup), because more memory allowed bigger, more efficient decode batches.
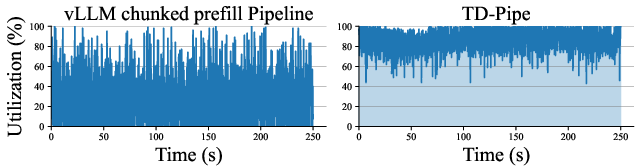
- GPU usage was much higher—less waiting, more computing.
- The output-length predictor was fast and accurate enough to be useful, and added very little overhead.
Why does this matter?
For tasks where you want to process lots of text quickly—like training with human feedback (RLHF rollouts), batch APIs, or creating large datasets—TD-Pipe helps you do more with the GPUs you already have, even if they’re on standard machines without high-speed GPU links (like NVLINK). That can:
- Reduce costs by using commodity hardware efficiently.
- Save time by increasing throughput.
- Make large-scale LLM inference more practical for research labs, startups, and companies.
In short, TD-Pipe shows that reorganizing the flow of work—doing big chunks of prefill, then big chunks of decode, and switching smartly—can significantly speed up LLM inference without expensive hardware.
Collections
Sign up for free to add this paper to one or more collections.