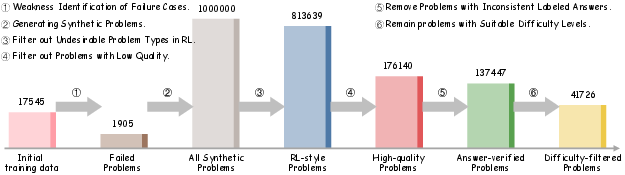
- The paper introduces a novel framework that identifies LLM weaknesses and synthesizes targeted training problems using reinforcement learning.
- It demonstrates significant performance gains, achieving up to a 10% improvement on a 7B model and enhanced results on competition benchmarks.
- The study explores self-evolving paradigms and weak-to-strong generalization, revealing potential for broader applications in efficient model training.
SwS: Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning for LLM Reasoning
Introduction to SwS
The paper introduces a framework called Self-aware Weakness-driven Problem Synthesis (SwS) to address the limitations in the reasoning capabilities of LLMs trained via Reinforcement Learning with Verifiable Rewards (RLVR). SwS aims to systematically identify areas where the model consistently fails and leverage these failures to synthesize new training problems that specifically target these weaknesses. This approach enhances the model's generalization capabilities and reasoning power without reliance on external knowledge distillation.
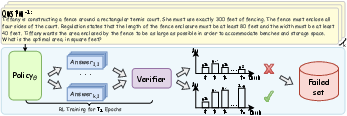
Figure 1: Illustration of the self-aware weakness identification during a preliminary RL training.
Framework Overview
The SwS framework is divided into several key stages:
- Self-aware Weakness Identification: During initial RL training, the framework records problems that the model consistently fails to solve. Weaknesses are identified based on two criteria: problems where the model never achieves a response accuracy greater than 50% and problems showing a negative performance trend over time. Identified weaknesses serve as a foundation for targeted data synthesis.
- Targeted Problem Synthesis: Extract underlying concepts from failure cases, categorize them, and recombine these concepts to generate new questions targeting the same capabilities. The synthesis process uses co-occurrence probabilities and semantic embedding similarities to ensure coherence and relevance among the generated problems.
- Augmented Training with Synthetic Problems: Once synthesized, the problems are integrated into the training set, creating an enriched environment that focuses on the model's weaknesses, thus enhancing learning efficiency and robustness.
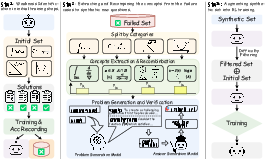
Figure 2: An overview of our proposed weakness-driven problem synthesis framework that targets at mitigating the model's reasoning limitations within the RLVR paradigm.
Experimental Results
The framework demonstrates its effectiveness across model sizes from 3 billion to 32 billion parameters, achieving substantial average performance improvements of 10% for the 7B model and 7.7% for the 32B model across eight benchmarks. This proves SwS's capacity to refine the model's reasoning abilities beyond traditional datasets created for Supervised Fine-Tuning (SFT). Additionally, the framework enhances the model's performance on competition-level benchmarks, highlighting the effectiveness of synthetic problems tailored to the model's specific weaknesses.
Weakness Mitigation Insights
Analyzing failure rates across different domains in the initial training set, it is observed that continued training with augmented problems results in a noticeable reduction of consistently failed problems. This highlights the efficiency of the SwS strategy in tackling the model's weakest areas, effectively transforming these into strengths through focused reinforcement learning.
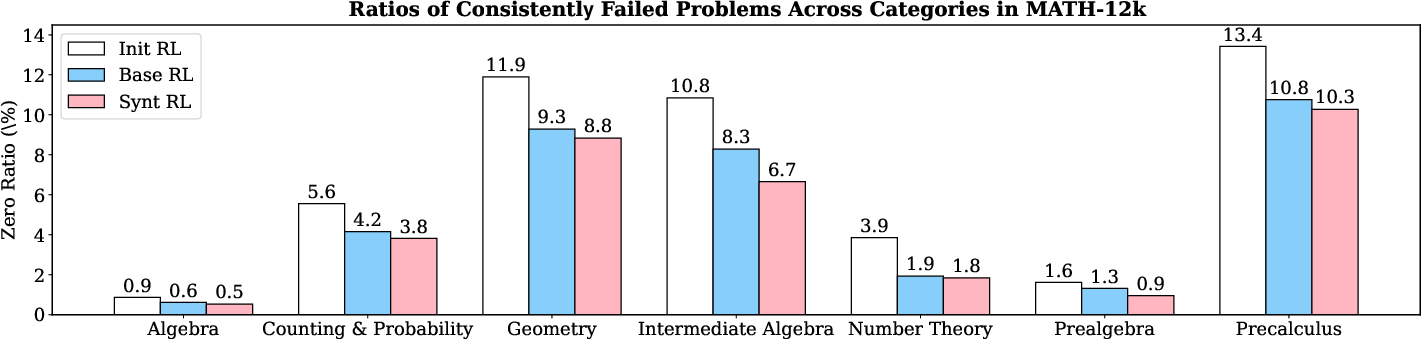
Figure 3: The ratios of consistently failed problems from different categories in the MATH-12k training set under different training configurations. (Base model: Qwen2.5-7B).
Extensions and Variations
The paper explores several extensions to the SwS framework:
Conclusion
SwS provides a robust mechanism for enhancing LLM reasoning through targeted problem synthesis, driven by the model's self-identified weaknesses. By focusing on consistently failed cases, SwS achieves marked improvements in reasoning benchmarks and introduces novel strategies for efficient RL training. Future directions include further exploration of synthetic problem difficulty enhancement and application across broader task domains.
Discussion and Future Directions
Despite SwS's efficacy, computational demands for strong answer-labeling reasoning models persist. The framework primarily emphasizes RL settings for reasoning improvement, challenging the integration with SFT or distillation techniques. Additionally, enhancing complexity in synthetic problems remains crucial for eliciting deeper reasoning capabilities, indicating opportunities for leveraging advanced instruction models or methodologies like Evolve-Instruct to refine problem synthesis.
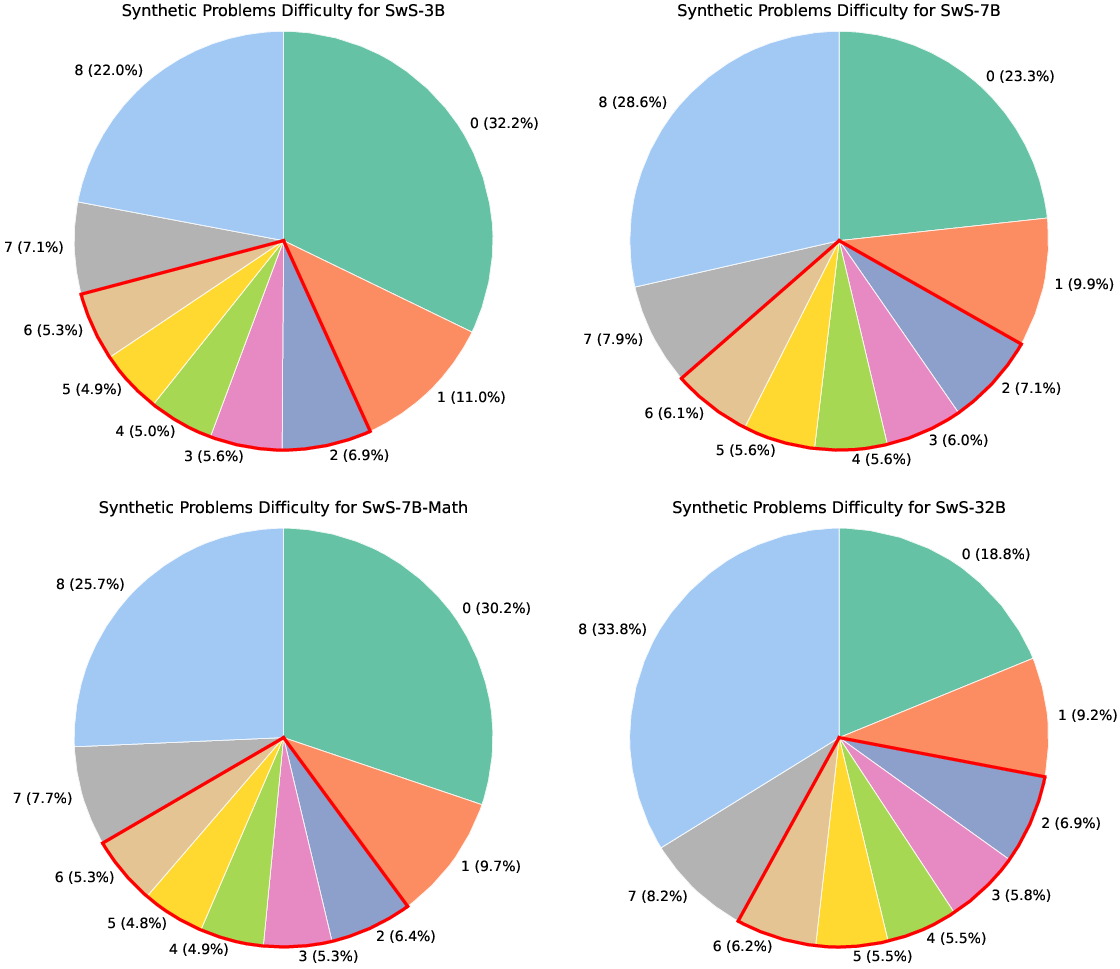
Figure 5: Difficulty distributions of synthetic problems for models from 3B to 32B in our work.