- The paper introduces a hybrid CNN architecture combining Inception-style multi-branch design with a bottleneck Mamba module for enhanced spatial and global modeling.
- It employs orthogonal large-kernel band convolutions within a ConvMixer module to efficiently capture local spatial features.
- Experimental results on ImageNet, COCO, and ADE20K confirm state-of-the-art performance with reduced computational costs.
InceptionMamba: An Efficient Hybrid Network
The paper introduces InceptionMamba (2506.08735), a novel CNN architecture that combines the strengths of InceptionNeXt and Mamba to achieve state-of-the-art performance with improved parameter and computational efficiency. The key innovation lies in replacing traditional one-dimensional strip convolutions with orthogonal band convolutions for cohesive spatial modeling and incorporating a bottleneck Mamba module to facilitate inter-channel information fusion and enlarged receptive field. This hybrid approach aims to leverage the efficient parallel structure of Inception-style networks while enhancing global contextual modeling capabilities through the Mamba architecture.
Architectural Overview
The InceptionMamba architecture, illustrated in (Figure 1), maintains a four-stage hierarchical structure inspired by ConvNeXt and InceptionNeXt.

Figure 1: InceptionMamba employs a hierarchical architecture of four consecutive stages, each consisting of a patch embedding layer or a downsampling module, combined with Ni InceptionMamba blocks.
Each stage comprises a patch embedding layer or a downsampling module, followed by a series of InceptionMamba blocks. The input tensor undergoes processing through a ConvMixer module for local spatial information encoding and a Global Mixer module for global context modeling and capturing long-range dependencies. Normalization and MLP modules are then applied to refine the aggregated features. The core InceptionMamba block, the cornerstone of the architecture, incorporates carefully designed orthogonal band convolutions within the ConvMixer and a bottleneck Mamba module within the GlobalMixer.
Key Components and Implementation Details
ConvMixer with Large-Kernel Band Convolutions
The ConvMixer module addresses the limitations of one-way large kernels by employing a multi-branch structure inspired by SLaK and InceptionNeXt. This parallel structure enables the acceleration of large-kernel depthwise convolutions for efficient local spatial modeling. The key innovation here is the replacement of one-dimensional strip convolutions, used in InceptionNeXt, with orthogonal large-kernel band convolutions. Band convolutions can focus on larger areas to improve local modeling.
The input features, X, are divided into three groups along the channel dimension: Xsquare, Xband, and Xidentity. These groups are then processed in parallel through different branches: a 3×3 depthwise convolution for Xsquare, a combination of 3×11 and 11×3 depthwise convolutions for Xband, and an identity mapping for Xidentity. The outputs of these branches are then concatenated to form the output feature map.
GlobalMixer with Bottleneck Mamba
To enhance effective cross-channel interaction and reduce channel redundancy, a Bottleneck Mamba structure is introduced. This structure incorporates a 1×1 convolution to compress and expand feature channels, facilitating efficient cross-channel fusion in a low-dimensional space while retaining key information. A state-space module (SS2D) is integrated within the bottleneck architecture to strengthen global modeling capacities while optimizing computational efficiency through channel compression. The GlobalMixer module formulates the input X′ as follows:
X′′=Conv1×1C→C/r(X′)) X′′=SS2D(X′′) X′′=Conv1×1C/r→C(X′′) Y=X+X′
where r is a channel compression ratio.
Block Comparisons
(Figure 2) compares the building blocks of ConvNeXt, InceptionNeXt, and InceptionMamba.
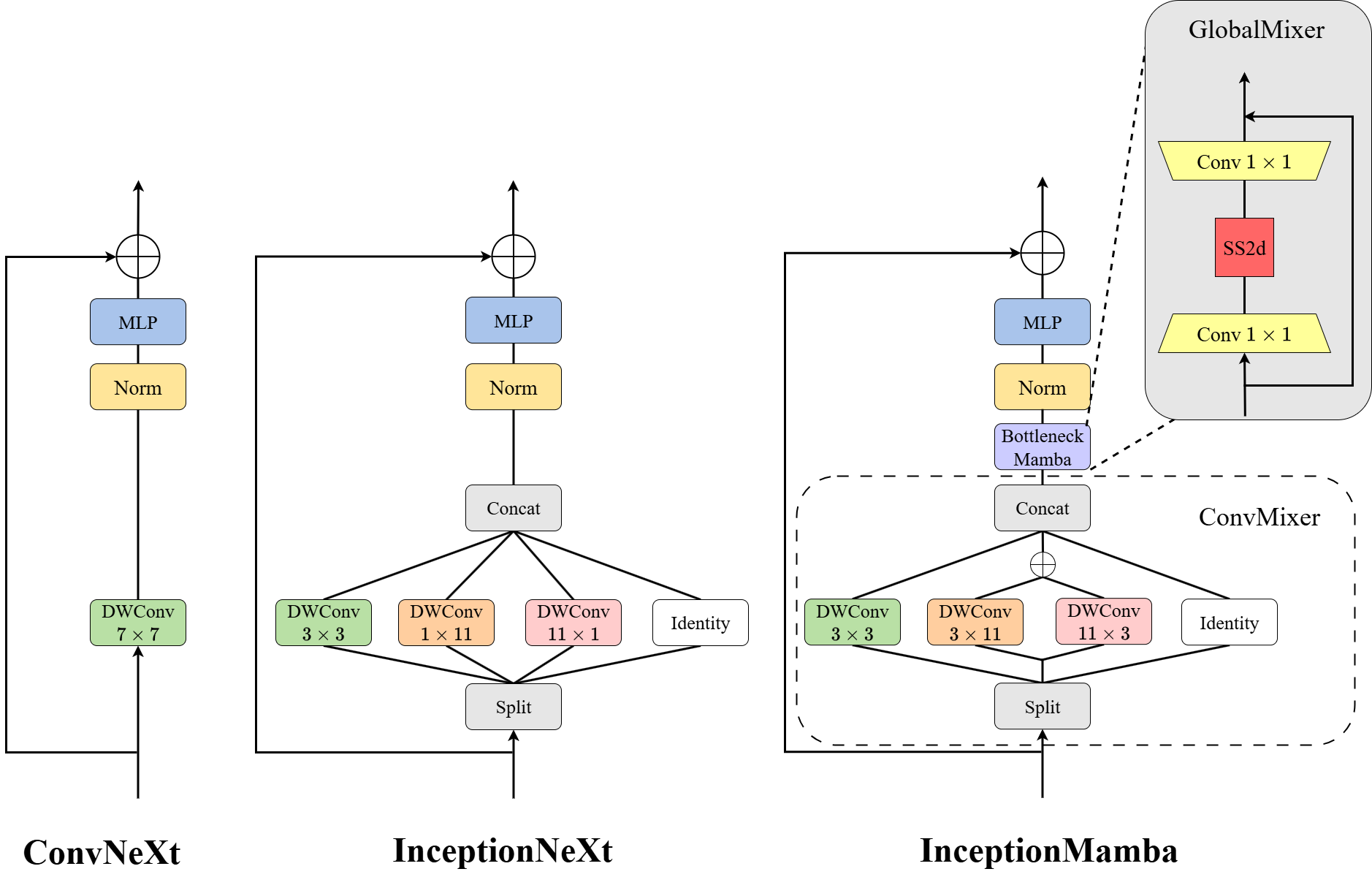
Figure 2: Comparison of ConvNeXt, InceptionNeXt, and InceptionMamba blocks, highlighting the orthogonal band convolutions and bottleneck Mamba structure for improved spatial and global modeling.
The InceptionMamba block allows efficient computation of large-kernel depthwise convolutions via a parallel multi-branch structure inherited from InceptionNeXt. InceptionMamba features orthogonal band convolutions and a GlobalMixer module with a bottleneck Mamba structure to capture long-range dependencies through cross-channel interaction. ConvNeXt and InceptionNeXt exhibit limited global modeling capacity due to the absence of a GlobalMixer-like component for sufficient information fusion.
Experimental Results
The effectiveness of InceptionMamba was validated through extensive experiments on image classification, object detection, and semantic segmentation tasks using benchmark datasets such as ImageNet-1K, MS-COCO, and ADE20K.
Image Classification on ImageNet
On ImageNet-1K, InceptionMamba-B achieved 84.7\% top-1 accuracy with 83M parameters and 14.3G FLOPs, surpassing existing state-of-the-art models, including InceptionNeXt and Mamba-like frameworks such as MambaVision and VMamba. InceptionMamba-T attained 83.1\% Top-1 accuracy with 25.4M parameters and 4.0G FLOPs, outperforming both Mamba and CNN models like VMamba-T (82.2\%) and InceptionNeXt-T (82.3\%).
Object Detection and Instance Segmentation on COCO
For object detection and instance segmentation on MS-COCO, InceptionMamba consistently outperformed competing architectures, including ConvNeXt, Swin-Transformer, and Mamba-based networks. Specifically, InceptionMamba-T achieved 46.0\% APb and 41.8\% APm with 43M parameters and 233G FLOPs, surpassing MambaOut-T and ConvNeXt-T by significant margins. The larger InceptionMamba-B model reported the highest 48.1\% APb and 43.1\% APm, outperforming MambaOut-B and ConvNeXt-B while reducing computational costs.
Semantic Segmentation on ADE20K
On the ADE20K dataset, InceptionMamba-B achieved 50.1\% mIoU with 110M parameters and 1145G FLOPs, outperforming competing networks in both accuracy and efficiency. These results highlight the potential of the hybrid architecture in combining local-aware encoding and global context modeling.
Ablation Studies
Ablation studies were conducted to evaluate the impact of different components and configurations within InceptionMamba. These studies examined the effects of branch ratio within ConvMixer, the benefits of the bottleneck structure within GlobalMixer, and the contribution of different modules involving the bottleneck. The results demonstrated that the proposed ConvMixer design, the bottleneck structure in GlobalMixer, and the integration of SS2D contribute to the overall performance and efficiency of the InceptionMamba architecture. (Figure 3) shows substantial redundancies in channel information.
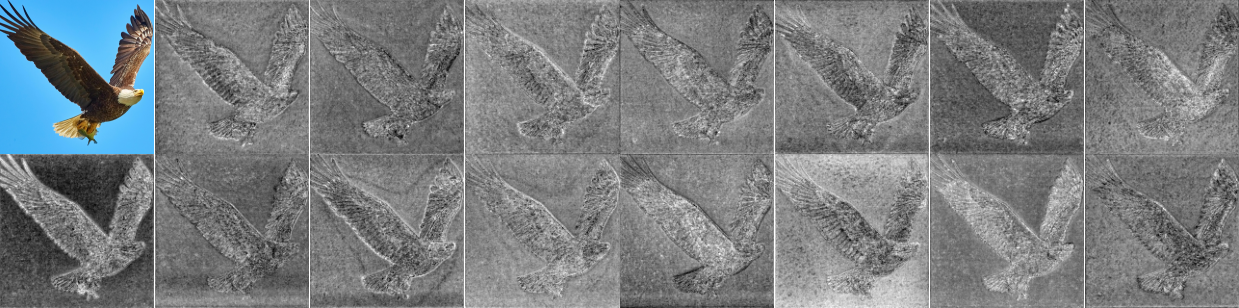
Figure 3: Visualized feature maps along consecutive channels in an intermediate layer of a pretrained VMamba model illustrating substantial redundancies in channel information.
Qualitative comparisons using CAMs, shown in (Figure 4), further demonstrated the advantages of InceptionMamba in capturing object-aware regions more comprehensively and accurately compared to ConvNeXt and InceptionNeXt.

Figure 4: Comparison of CAMs generated from different mainstream architectures, demonstrating InceptionMamba's ability to characterize key semantic-aware regions.
Conclusion
The InceptionMamba architecture effectively combines the strengths of InceptionNeXt and Mamba, achieving state-of-the-art performance with improved efficiency across various vision tasks. The orthogonal band convolutions and bottleneck Mamba module contribute to enhanced spatial modeling and long-range dependency capture. The extensive experiments and ablation studies validate the effectiveness of the proposed hybrid architecture, offering a promising direction for designing lightweight yet powerful vision backbones.