- The paper introduces a novel framework that refines RAG by transforming noisy documents into structured knowledge graphs for robust error detection.
- It implements Dense Direct Preference Optimization (DDPO) that applies token-level importance weighting to prioritize correcting knowledge discrepancies.
- The study employs an LLM-powered contrastive data generation pipeline, demonstrating improved EM metrics and stable reward-accuracy trade-offs.
KARE-RAG: Knowledge-Aware Refinement and Enhancement for RAG
The paper "KARE-RAG: Knowledge-Aware Refinement and Enhancement for RAG" focuses on improving the Retrieval-Augmented Generation (RAG) framework by addressing the challenges posed by noise in retrieved documents. The KARE-RAG framework enhances the traditional RAG pipeline by implementing structured knowledge representations, Dense Direct Preference Optimization (DDPO), and a contrastive data generation pipeline to improve the processing of noisy retrieved content.
Methodology
The KARE-RAG methodology introduces three key innovations:
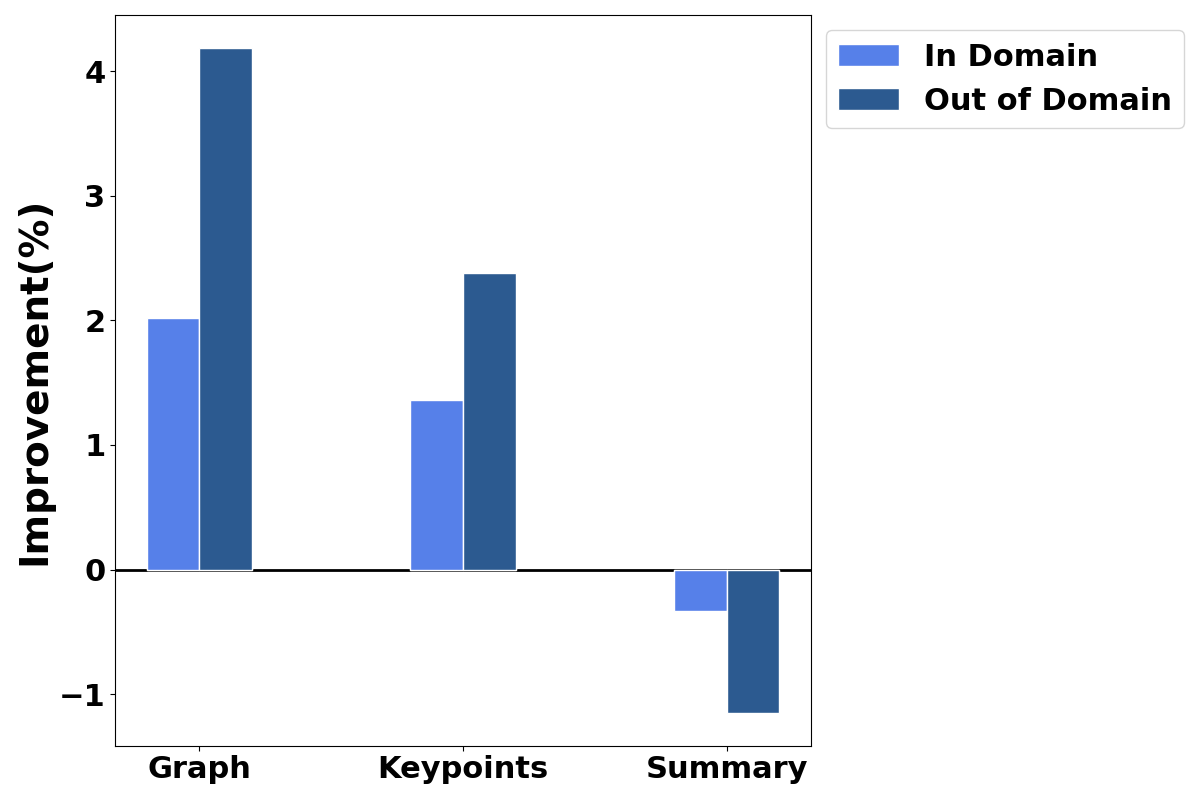
- Structured Knowledge Representations: This approach transforms noisy documents into structured knowledge graphs during training, facilitating error detection and creating explicit learning objectives (Figure 1). The structured format enables models to learn noise-resistant information processing patterns, offering a robust foundation for subsequent processing stages.
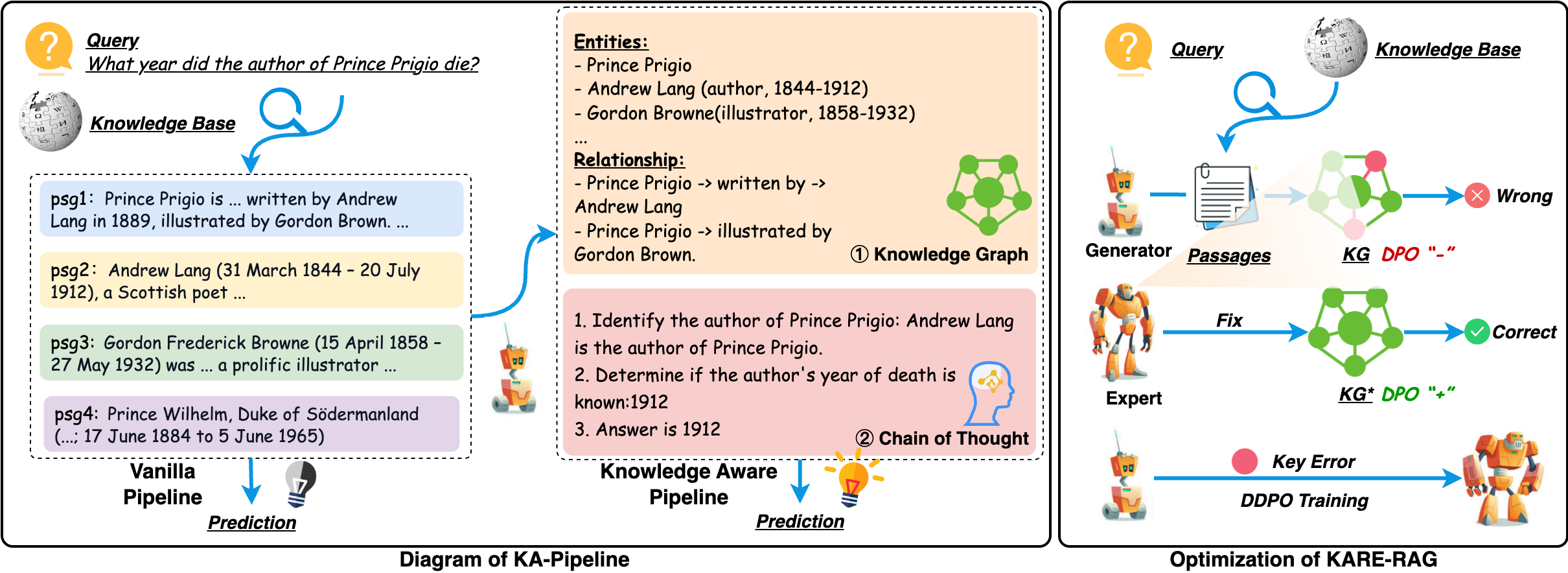
Figure 1: Illustration of our KARE-RAG Method. The left side of the image illustrates the differences between our method and Vanilla RAG, while the right side outlines the general workflow of our data construction process.
- Dense Direct Preference Optimization (DDPO): DDPO enhances the standard Direct Preference Optimization by introducing token-level importance weighting, prioritizing the correction of critical knowledge discrepancies. This approach improves information filtering strategies that generalize to standard RAG pipelines.
- Contrastive Data Generation Pipeline: An LLM-powered pipeline generates high-quality training pairs through a three-stage self-verification: error localization, targeted correction, and validation filtering. This automated pipeline reduces reliance on human annotation and addresses the scarcity of positive samples, ensuring substantive knowledge discrimination.
Experimental Evaluation
Extensive experiments demonstrate the effectiveness of the KARE-RAG method across different datasets and model scales. The framework provides statistically significant improvements in both in-domain and out-of-domain benchmarks, highlighting its robustness in knowledge utilization and generalization capabilities.
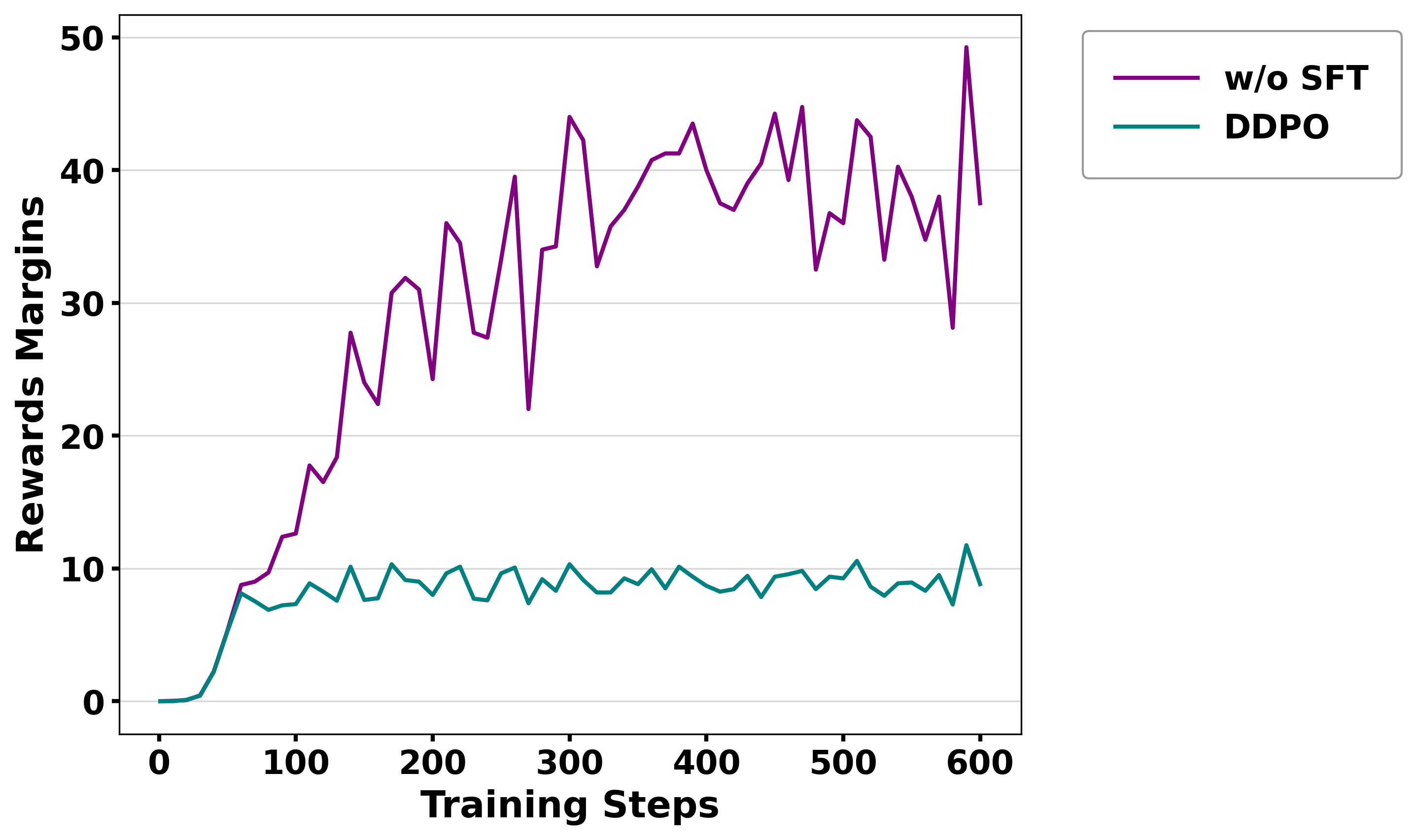
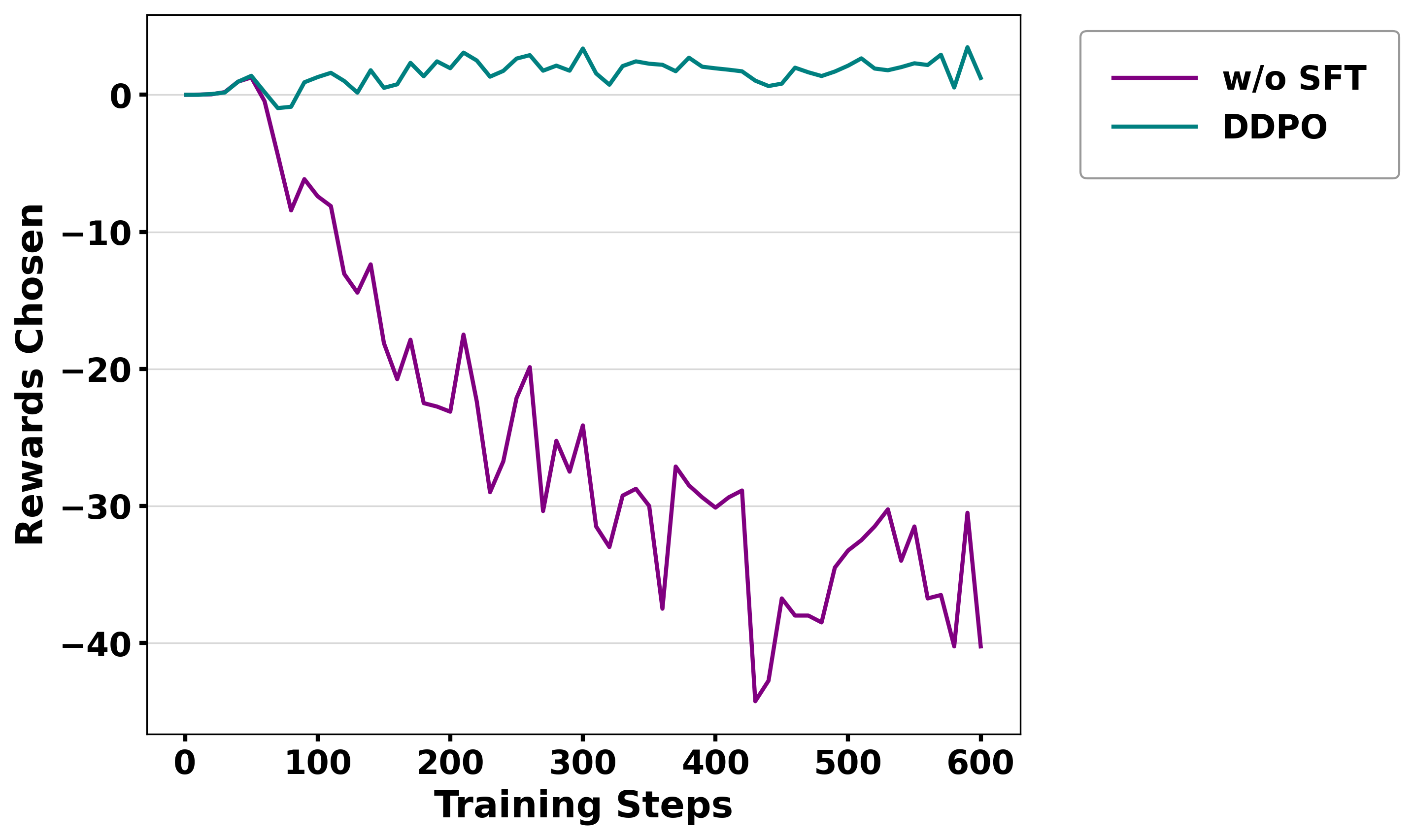
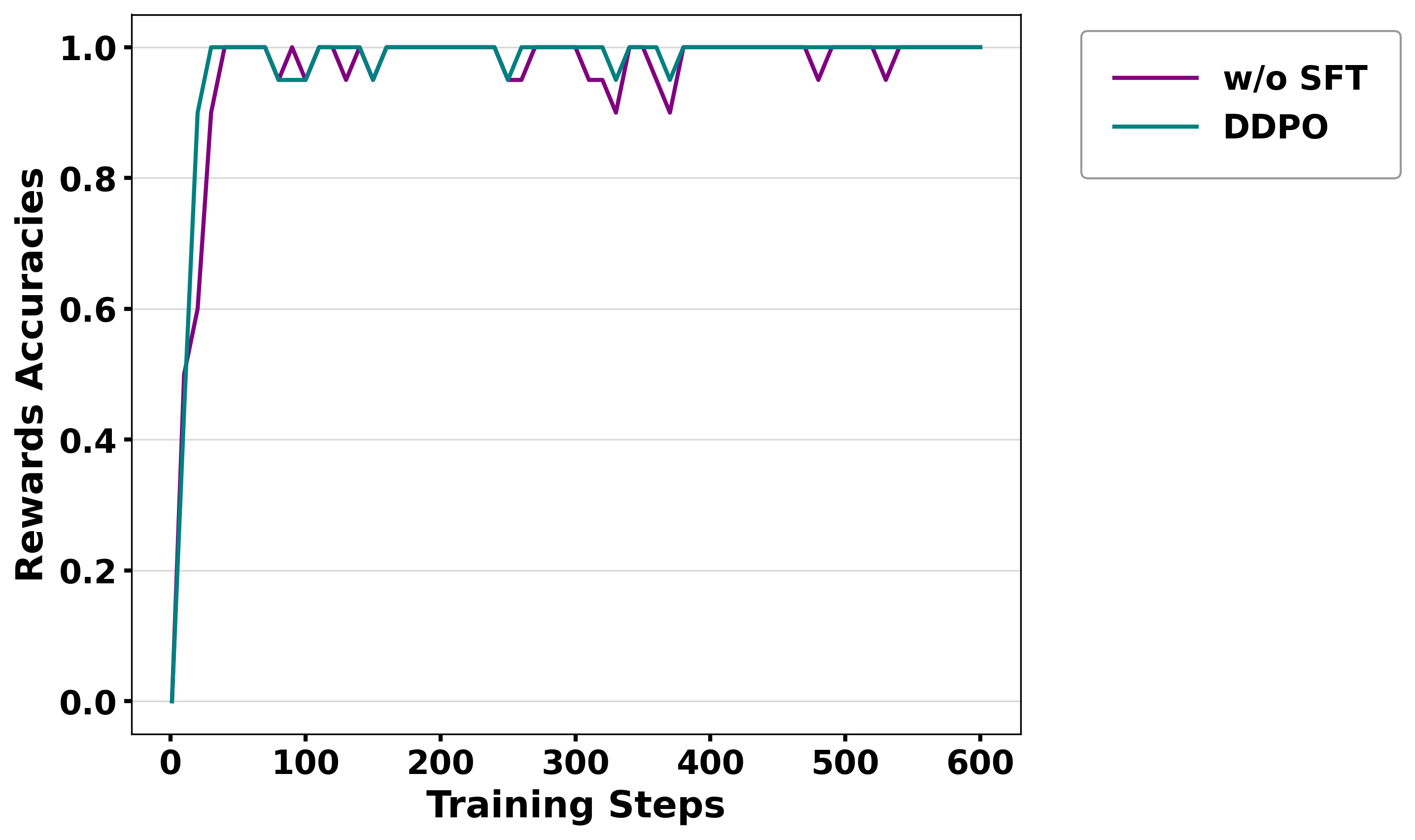
Figure 3: Reward/accuracy
Implementation Considerations
Computational Efficiency
The KARE-RAG framework is computationally efficient, employing parameter-efficient LoRA adapters and DeepSpeed-Zero3 optimization for training on a single A100-40G GPU. The data generation process extends the capabilities of existing models with minimal computational overhead.
Deployment Strategies
KARE-RAG maintains full compatibility with standard RAG pipelines, requiring no architectural changes during deployment. This compatibility ensures seamless integration with existing systems, facilitating adoption in real-world applications.
Trade-offs
While KARE-RAG enhances performance, the specific choice of structured representations (e.g., knowledge graphs) may need tailoring to particular domains or tasks. Future work could explore alternative structured formats, such as hierarchical trees or temporal sequences, to further generalize the method's applicability.
Conclusion
KARE-RAG presents a novel approach to enhancing Retrieval-Augmented Generation by refining how models process retrieved content. By integrating structured knowledge representations, DDPO, and contrastive data generation, KARE-RAG achieves significant performance gains across diverse scenarios. This framework establishes a foundation for future exploration in optimizing knowledge-intensive tasks, with potential applications extending to complex reasoning and decision-making domains.