- The paper introduces the MoDoMoDo framework that utilizes a quadratic surrogate model to optimize multi-domain data mixtures for balanced multimodal learning.
- It employs reinforcement learning with verifiable rewards to fine-tune models using diverse datasets, enhancing reasoning across vision-language tasks.
- Experimental results demonstrate that smart data mixing strategies significantly outperform naive approaches on both in-domain and out-of-domain benchmarks.
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
The paper "MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning" introduces an advanced framework called MoDoMoDo designed to enhance the post-training of Multimodal LLMs (MLLMs) through Reinforcement Learning with Verifiable Rewards (RLVR). This approach addresses the complexities involved in multimodal tasks, such as conflicting objectives and heterogeneous task domains, by optimizing data mixtures across multiple datasets.
Introduction to MoDoMoDo Framework
The MoDoMoDo framework is developed to leverage RLVR for training MLLMs using a diverse mixture of datasets. The core idea is to optimize the combination of datasets to improve generalization and reasoning across various Vision-Language (VL) tasks. This is achieved by systematically mixing data from different domains to balance the diverse capabilities required by MLLMs.
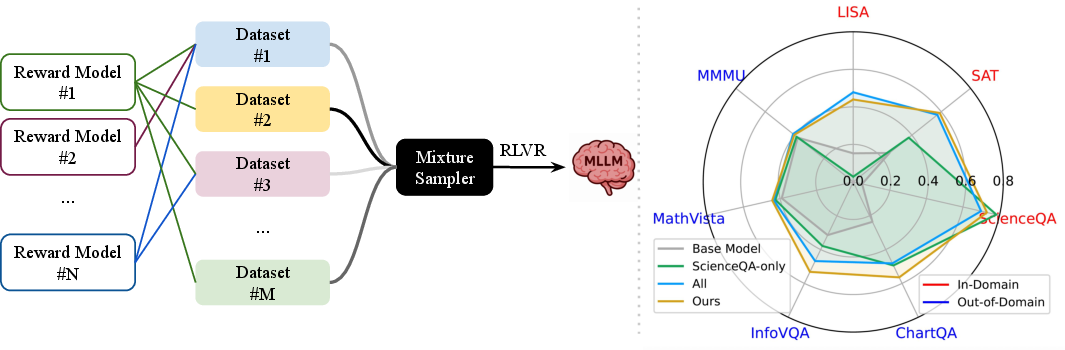
Figure 1: MoDoMoDo is a framework that combines Multi-Domain Data Mixtures with Multimodal LLM Reinforcement Learning, enabling generalizable performance gain across diverse VL tasks. Models trained with our estimated optimal mixtures can outperform those trained with naive mixtures on in-domain and out-of-domain benchmarks.
Multimodal RLVR with Data Mixtures
The problem is framed as a bi-level optimization where the goal is to determine the optimal data mixture distribution that maximizes the performance on unseen testing distributions. The RL algorithm is tasked with fine-tuning models based on training data subject to a distribution determined by the mixture weights. A critical aspect of RLVR is defining verifiable reward functions that assess model outputs across different multimodal domains.
Data Mixture Strategy
The proposed strategy involves predicting the RL fine-tuning outcome from different mixture distributions using a quadratic surrogate model. This model approximates the complex mappings from mixture distributions to model performance, allowing for efficient prediction and optimization of dataset combinations.
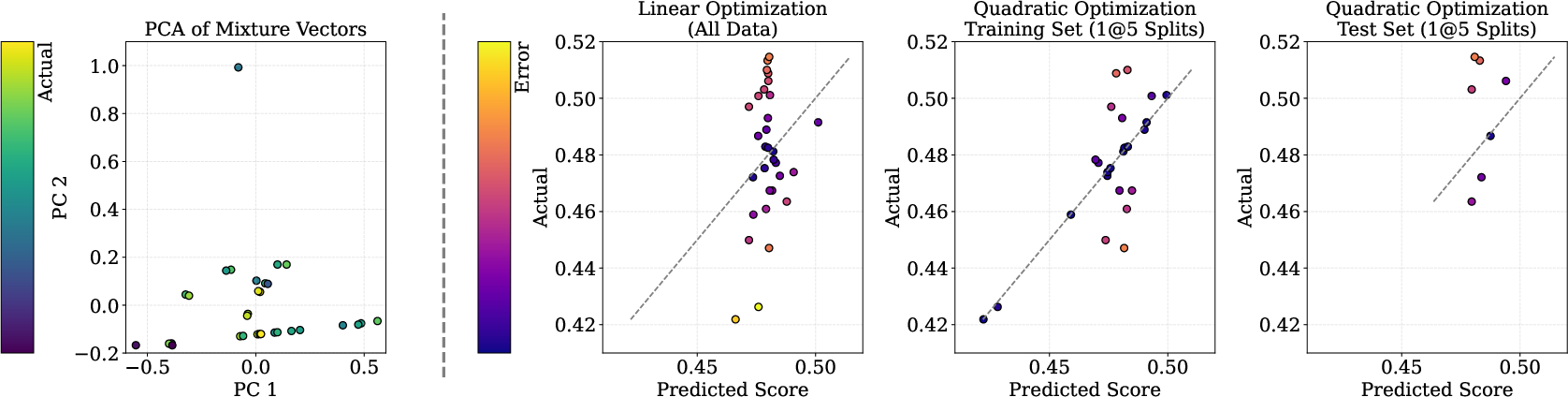
Figure 2: Model-based mixture optimization. Left: PCA on mixture vectors reveals lack of linear separability, motivating nonlinear modeling. Middle-left: Linear regression fails to fit Out-Score accurately, even with all data. Right: Quadratic regression fitted on training folds could generalize better to held-out folds, capturing nonlinear interactions critical for mixture prediction.
Experiments and Results
Experimental Setup
The experimental phase involves selecting appropriate datasets for training and evaluating MoDoMoDo's effectiveness. Diverse datasets are curated to expose the model to various VL competencies, ensuring wide generalization and capability coverage.
Data Mixture Implementation
Multiple data mixture strategies are tested, including seed mixtures, heuristic-based approaches, and model-based strategies using the quadratic surface optimization technique. The results indicate that sophisticated data mixing strategies can substantially enhance both specialized and general model performance.

Figure 3: Comparison of Grounding Question-Answer Pairs \colorbox{lightgreen}{With} and \colorbox{lightblue}{Without} Reasoning.
The paper situates MoDoMoDo within the broader context of multimodal LLM training and data mixture strategies. It highlights the precedence of reward-based RL in text-based LLMs and extends these methods to multimodal settings, emphasizing the challenges and opportunities in combining datasets for optimal learning.
Conclusion
MoDoMoDo demonstrates significant improvements in multimodal reasoning capabilities through optimized dataset mixtures. The study confirms that thoughtful mixtures leveraging quadratic models can outperform naive approaches, suggesting potential extensions to other modalities and more complex multimodal reasoning tasks.
The framework opens avenues for further research into extending MoDoMoDo to audio, video, and other data-rich tasks, alongside theoretical developments to support its empirical findings. Future work may explore more advanced surrogate models incorporating dataset similarity and curriculum learning to further refine the process of optimizing RL training mixtures.