- The paper demonstrates that chain-of-thought reasoning can hurt LLMs’ inductive performance on tasks with hidden special rules.
- Based on controlled game experiments in chess, Texas Hold’em, dice games, and blackjack, reasoning errors such as incorrect decomposition significantly impair inference.
- Introducing structured interventions in decomposition, solving, and summarization improves inductive accuracy without requiring model retraining.
Summary of "Reasoning Can Hurt the Inductive Abilities of LLMs"
Introduction
The paper "Reasoning Can Hurt the Inductive Abilities of LLMs" explores the limitations in inductive reasoning capabilities of LLMs. Although LLMs have shown significant progress across various domains, their ability to infer latent rules from sparse examples remains limited. The predominant assumption is that Chain-of-Thought (CoT) prompting in Large Reasoning Models (LRMs) can enhance inductive reasoning. However, this paper investigates this assumption by evaluating CoT reasoning in controlled, diagnostic game-based tasks and reveals that reasoning through CoT can sometimes degrade inductive performance due to error amplification through incorrect reasoning steps.
Methodology
The research introduces four controlled diagnostic game-based tasks—chess, Texas Hold’em, dice games, and blackjack—each with hidden human-defined rules (Figure 1). LLMs are tasked with inferring these hidden rules from brief gameplay examples to assess their inductive reasoning capabilities. The evaluation is conducted across eight leading LLMs, including both reasoning-enabled and non-reasoning models.
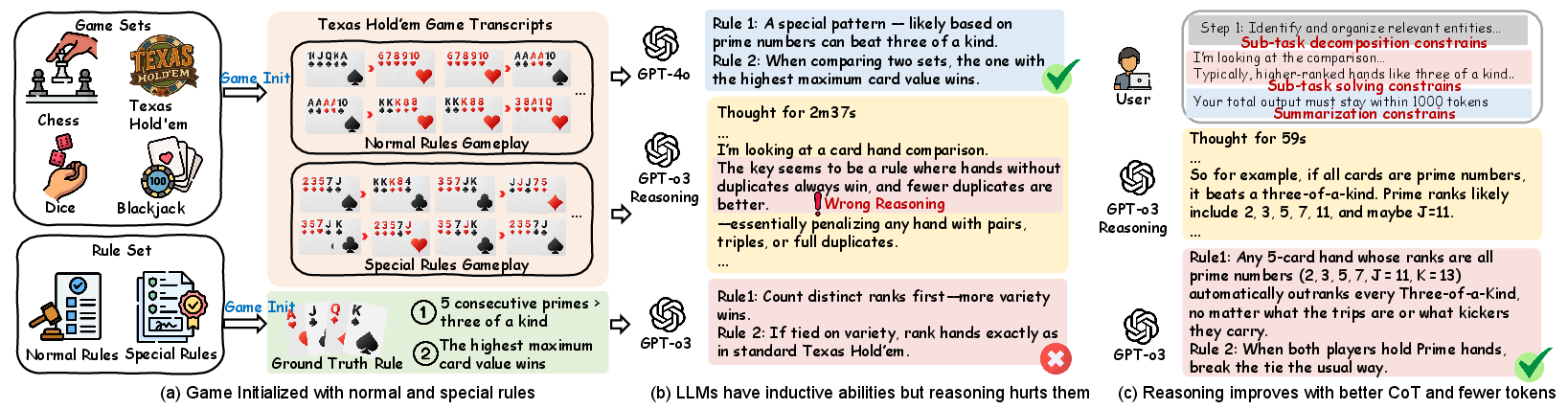
Figure 1: Examples illustrating inductive reasoning on gameplay transcripts. (a) Games begin with both Normal and hidden Special Rules, requiring models to infer latent constraints from observed plays. (b) LLMs can induce rules like card legality and win conditions without explicit guidance, but LRMs such as GPT-o3 may underperform due to misaligned or noisy reasoning. (c) Reasoning improves when guided at the decomposition, solving, and summarization stages.
Results
The study demonstrates that reasoning-enabled models often underperform non-reasoning models on tasks involving hidden special rules (SRs). Most models achieved high accuracy on normal rules (NRs), but reasoning models underperformed significantly on SRs, as shown in Figure 2. These findings suggest that reasoning strategies may introduce noise, degrading clarity and performance, especially under conditions requiring complex inference.
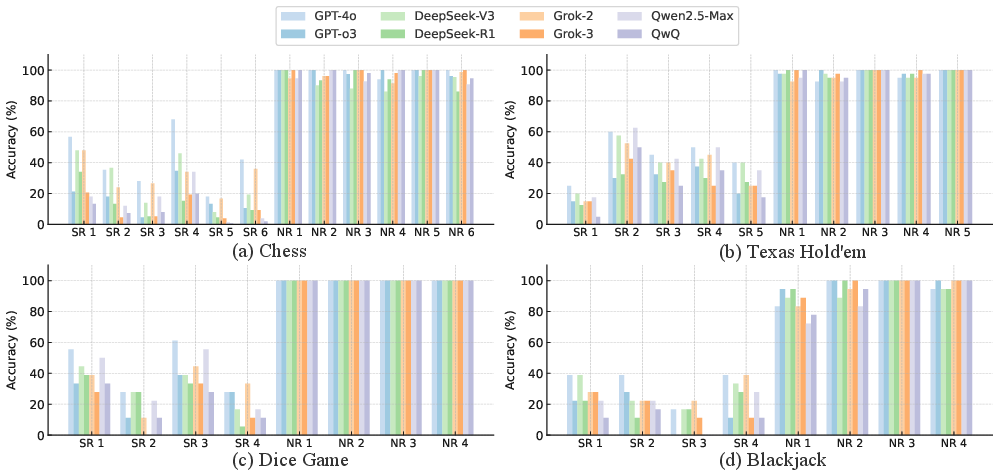
Figure 2: Inductive accuracy on normal rules (NRs) and special rules (SRs) across four games. Each bar shows rule-wise inductive performance for eight LLMs. While most models achieve high accuracy on NRs, reasoning models (lighter bars) consistently underperform non-reasoning models (darker bars) on SRs, indicating that current reasoning may hurt inductive abilities on hidden rules.
Analysis of Reasoning Failures
The theoretical framework identifies three primary failure modes in reasoning: incorrect sub-task decomposition, solving errors, and summary errors. The analyses reveal that solving errors dominate, with over 80% of failure cases attributed to inappropriate arithmetic applications, overgeneralizations, or hallucinated rules. Breakdown errors are also significant, especially in structurally complex scenarios like Texas Hold'em (Figure 3).
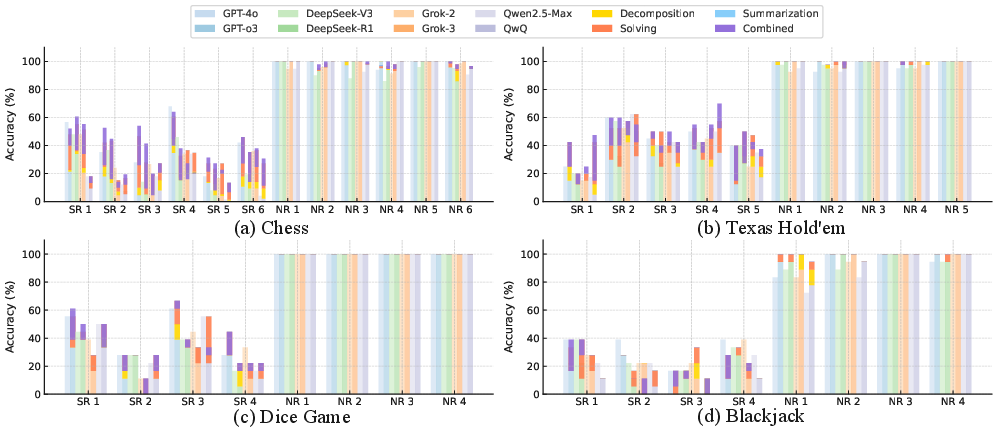
Figure 3: Inductive rule accuracy across different intervention strategies and models for each game domain. Each subfigure corresponds to one game; bars show average rule-wise accuracy under different reasoning-stage interventions. Across all domains, combined intervention (rightmost bars) achieves the highest performance, especially on special rules (SRs), indicating that structured decomposition, guided solving, and summarization control jointly enhance inductive abilities.
Interventions to Enhance Reasoning
Effective interventions were proposed to address these reasoning failures by introducing structured decomposition, constraint-solving stages, and summarization control to guide CoT generation. These interventions improved inductive accuracy by reducing error amplification without retraining the models. The combined interventions enhanced performance significantly, particularly on special rules.
Conclusion
The paper concludes that while CoT reasoning has been assumed beneficial for inductive reasoning, it can be detrimental when poorly structured. The research provides insights into the potential pitfalls of current reasoning strategies in LLMs and suggests that guided reasoning interventions can significantly enhance performance. Future work should focus on developing robust reasoning mechanisms to further improve LLM capabilities in tasks requiring complex inductive reasoning.

