- The paper introduces RoleRAG, a framework that employs graph-guided retrieval to enhance role-playing in LLMs by ensuring structured and accurate character portrayal.
- The paper evaluates RoleRAG on datasets featuring literary and historical characters, demonstrating significant improvements in knowledge alignment and hallucination reduction.
- The paper emphasizes the strategic importance of entity normalization and a boundary-aware retrieval module to maintain consistency in character-specific responses.
Enhancing Role-Playing Capabilities of LLMs
Introduction
In recent advancements within the domain of conversational AI, LLMs have achieved notable success in understanding and generating human-like text, particularly in contexts requiring character imitation. A significant challenge arises, however, when these models attempt to embody specific characters, particularly when the aim is to maintain both consistency with the character's known traits and accuracy in knowledge representation. The paper "RoleRAG: Enhancing LLM Role-Playing via Graph Guided Retrieval" addresses these challenges by introducing a framework called RoleRAG.
Role-playing LLMs are anticipated to maintain coherence with a character's persona and knowledge base. However, existing models often fall short due to issues like entity ambiguity and a lack of defined cognitive boundaries for characters. This paper proposes a retrieval-based framework that utilizes knowledge graphs to augment the role-playing capabilities of LLMs, thereby facilitating more accurate and informed conversations with reduced hallucination.
The RoleRAG Framework
Entity Disambiguation and Knowledge Graphs
A central aspect of the RoleRAG framework is its approach to resolving entity ambiguity. Characters from complex narratives often possess multiple aliases or names. The paper proposes an efficient semantic entity normalization algorithm to unify these aliases into a canonical form. This process mitigates the risk of retrieving inconsistent or incomplete knowledge about a character.
Once entities are normalized, the framework constructs a knowledge graph where nodes represent entities (characters, locations, objects), and edges denote semantic relationships between them. By indexing character-specific knowledge into this structured format, RoleRAG enables LLMs to better align their generated responses with the factual intricacies of that character's universe.
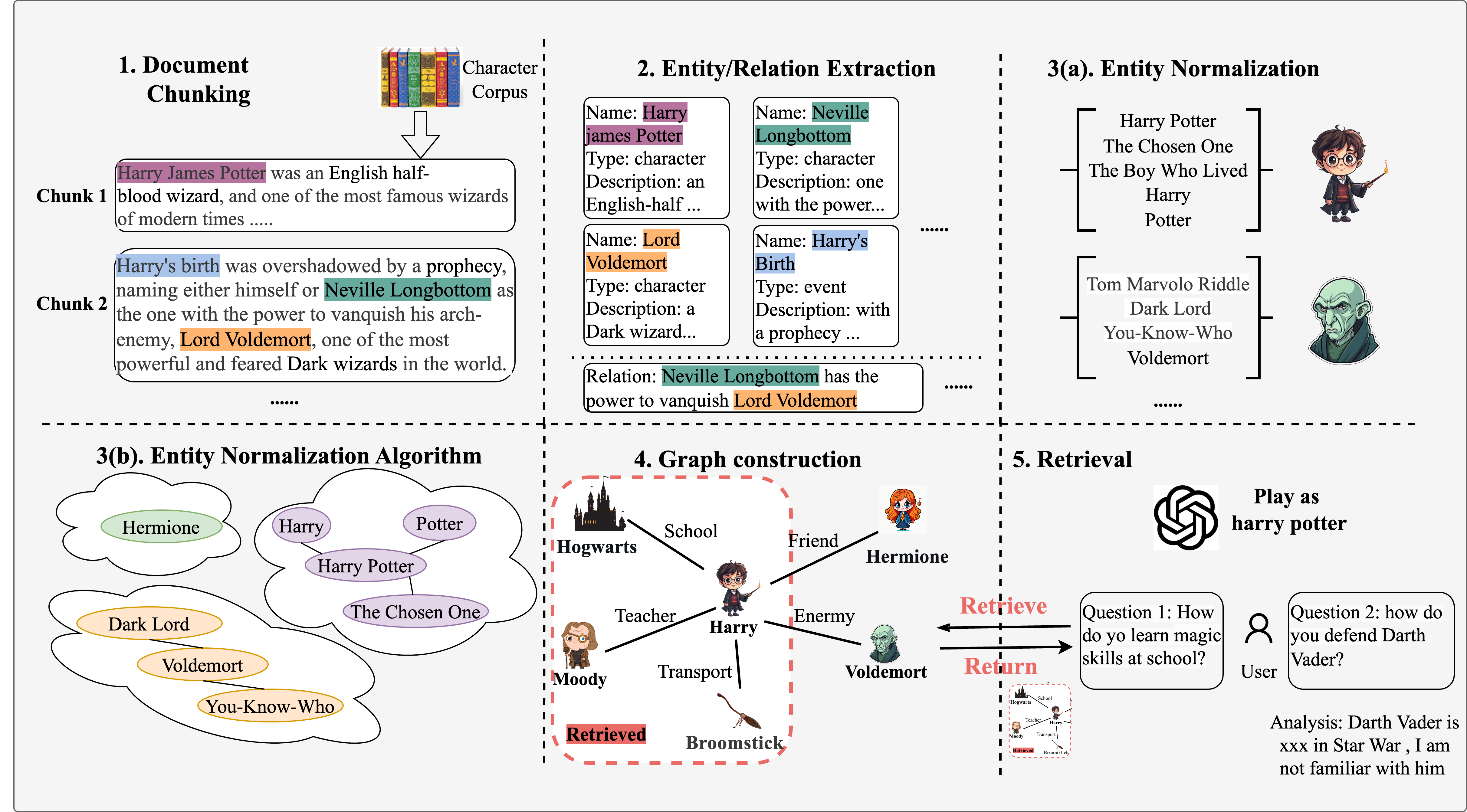
Figure 1: Workflow of our proposed RoleRAG.
Retrieval Module
The retrieval process within RoleRAG is designed to selectively fetch question-relevant information from the knowledge graph. The retrieval is context-aware, leveraging graph structure to discern between in-scope and out-of-scope queries. This prevents LLMs from generating responses that hallucinate or exceed the character's established knowledge boundaries.
A detailed walkthrough illustrates how RoleRAG processes a query: the module matches entities in the query with their graph representations, retrieves relevant relationships and descriptions, and uses this data to inform the LLM's response generation. Questions that fall outside the character's scope are explicitly rejected, supporting more trustworthy interactions.
Empirical Evaluation
The evaluation of RoleRAG involves extensive testing against existing LLMs using datasets tailored to role-playing scenarios, including queries about characters from the Harry Potter series and historical figures. The framework was benchmarked on metrics such as knowledge exposure, hallucination reduction, and rejection of incorrect questions. Metrics are visually represented to provide clarity on the framework's impact.
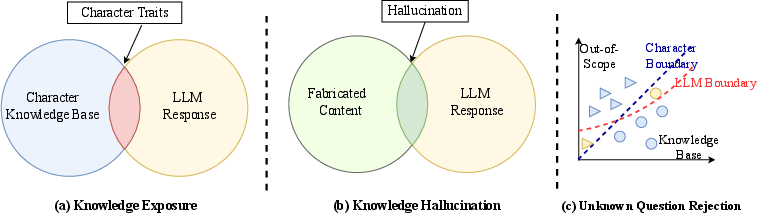
Figure 2: Illustration of evaluation metrics. We encourage LLMs to exhibit more personal traits, minimize fabricated content, and align more closely with the boundaries of character cognition.
RoleRAG demonstrated superior performance across all benchmarks, notably improving knowledge alignment and verification capabilities, while significantly lowering the incidence of fabricated responses. These improvements are attributed to the strategic entity normalization process and the boundary-aware retrieval module.
Discussion and Future Directions
RoleRAG's innovations offer promising avenues for enhancing the fidelity of role-playing LLMs. By incorporating more structured approaches to knowledge retrieval and enforcing cognitive boundaries, the framework addresses common pitfalls associated with LLM-based character imitation. Future research could explore extending this approach to handle multi-turn dialogues, ensuring consistency over longer interactions, and adapting the system to an even wider array of characters.
Conclusion
The integration of graph-guided retrieval to enhance role-playing in LLMs effectively bridges the gap between general language understanding and contextually accurate character portrayal. RoleRAG serves as a robust framework supporting the development of more interactive and reliable conversational agents, with applications spanning entertainment, education, and beyond. By prioritizing entity consistency and contextual relevance, it sets a new standard for role-playing in AI systems.

