- The paper introduces DFloat11, a lossless compression technique that reduces LLM model size by approximately 30% with 100% accuracy.
- It employs Huffman coding on BFloat16 exponents along with custom GPU kernels and hierarchical lookup tables for efficient, parallel decompression.
- Experimental results demonstrate up to 46.24× higher throughput and lower latency, enabling large models to run on resource-constrained GPUs.
A Method for Lossless Compression of LLMs for Efficient GPU Inference
The paper "70% Size, 100% Accuracy: Lossless LLM Compression for Efficient GPU Inference via Dynamic-Length Float" (arXiv ID: (2504.11651)) introduces Dynamic-Length Float (DFloat11), a novel lossless compression framework designed to enhance the efficiency of GPU inference for large-scale AI models, specifically LLMs and Diffusion Models (DMs). This framework is particularly aimed at reducing the model size by approximately 30% without sacrificing accuracy, facilitating more efficient deployments on resource-constrained hardware.
Motivation and Methodology
The motivation behind DFloat11 stems from the observation of information redundancy in the BFloat16 representation used widely for LLM weights. The BFloat16 format dedicates an 8-bit field to exponents, which, despite only carrying about 2.6 bits of actual information, suggests an opportunity for compression. This redundancy is due to the limited set of exponent values effectively used during model inference, as seen in Figure 1.
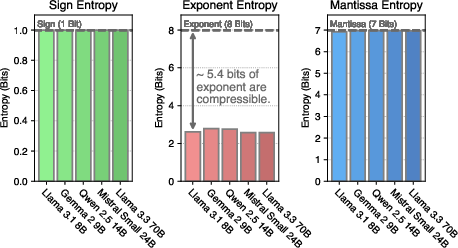
Figure 1: The allocation of bits for the components of BFloat16 and the Shannon entropy of these components in various LLMs.
Dynamic-Length Float Compression
DFloat11 addresses this inefficiency by applying Huffman coding to compress the exponents in BFloat16 weights, leaving the sign and mantissa bits unchanged, as shown in Figure 2. This lossless compression technique reduces the size of model weights to about 11 bits on average, offering a significant size reduction.
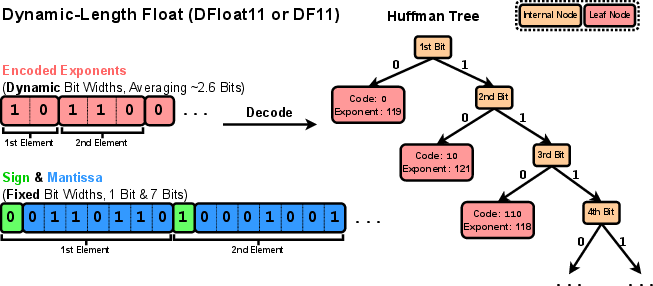
Figure 2: Our proposed format Dynamic-Length Float for compressing BFloat16 weights of LLMs losslessly down to 11 bits.
Efficient GPU Inference Implementation
For practical application, the paper introduces a custom GPU kernel that enables fast online decompression. A critical aspect of this implementation is the use of hierarchical lookup tables stored in high-speed GPU shared memory (SRAM) to efficiently decode Huffman codes, as depicted in Figure 3. This method avoids the sequential nature of traditional Huffman decoding, which is inefficient for parallel GPU architectures.
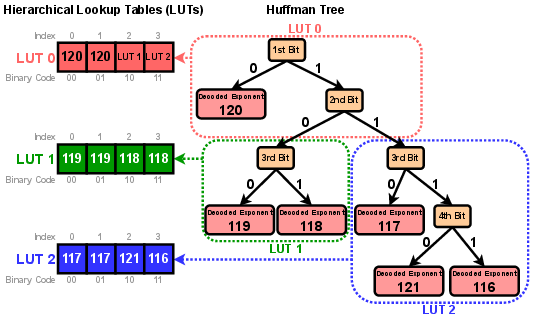
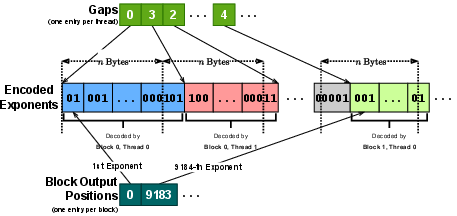
Figure 3: Hierarchical lookup tables in GPU SRAM for efficient Huffman decoding via array lookups.
Experimental Results
The DFloat11 format achieves a consistent compression ratio of approximately 30% across several state-of-the-art models without any loss of precision (Figure 4). Such a reduction allows these models to run efficiently within the GPU's memory constraints, significantly improving throughput and supporting longer sequence lengths during inference.
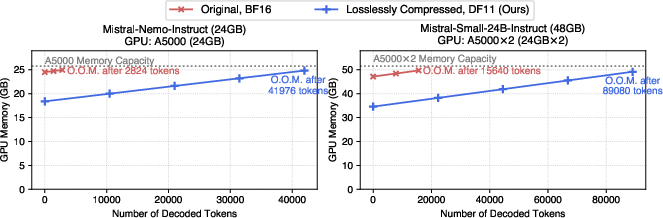
Figure 4: Comparison of GPU memory consumption between BF16 models and DF11 counterparts.
Inference Efficiency
Through extensive evaluations, DFloat11 models demonstrate superior performance compared to original models requiring CPU offloading due to memory constraints. The DF11 compressed models deliver 2.31–46.24× higher throughput and lower latency during token decoding benchmarks, as illustrated in Figure 5.
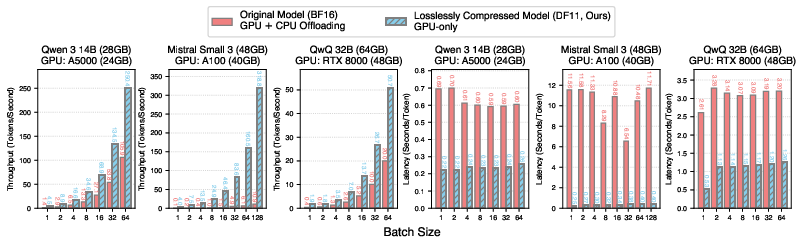
Figure 5: Throughput and latency comparisons for token decoding using BF16 models with CPU offloading versus DF11 models.
Implications and Conclusion
The adoption of DFloat11 represents a substantial advancement in the deployment of large AI models, making it feasible to run models like Llama 3.1 405B on a single node equipped with 8×80GB GPUs without losing model precision. This capability not only reduces the hardware requirements and costs associated with deploying large models but also enhances their accessibility and scalability.
DFloat11's contributions lie in its ability to preserve the exact output of original models while introducing only marginal decompression overhead, crucially maintaining the integrity and reliability needed for applications in sensitive domains such as finance and healthcare. As a result, DFloat11 sets a new standard for memory-efficient LLM deployment, offering a highly attractive alternative to existing quantization strategies.
In conclusion, this paper provides a robust framework for improving the performance of LLMs in resource-constrained environments, paving the way for more efficient AI deployments without sacrificing accuracy or reliability. Future work may explore the extension of these methodologies to other data formats and hardware configurations, further integrating these capabilities into contemporary AI systems.