Achieving Tokenizer Flexibility in Language Models through Heuristic Adaptation and Supertoken Learning
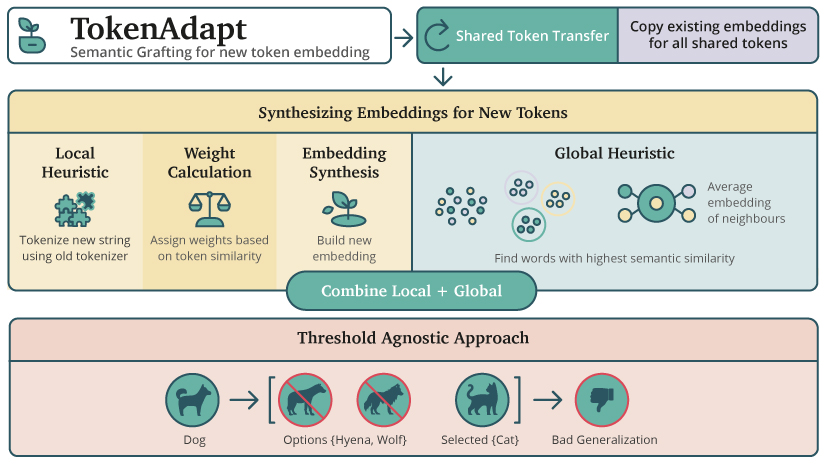
Abstract: Pretrained LLMs are often constrained by their fixed tokenization schemes, leading to inefficiencies and performance limitations, particularly for multilingual or specialized applications. This tokenizer lock-in presents significant challenges. standard methods to overcome this often require prohibitive computational resources. Although tokenizer replacement with heuristic initialization aims to reduce this burden, existing methods often require exhaustive residual fine-tuning and still may not fully preserve semantic nuances or adequately address the underlying compression inefficiencies. Our framework introduces two innovations: first, Tokenadapt, a model-agnostic tokenizer transplantation method, and second, novel pre-tokenization learning for multi-word Supertokens to enhance compression and reduce fragmentation. Tokenadapt initializes new unique token embeddings via a hybrid heuristic that combines two methods: a local estimate based on subword decomposition using the old tokenizer, and a global estimate utilizing the top-k semantically similar tokens from the original vocabulary. This methodology aims to preserve semantics while significantly minimizing retraining requirements. Empirical investigations validate both contributions: the transplantation heuristic successfully initializes unique tokens, markedly outperforming conventional baselines and sophisticated methods including Transtokenizer and ReTok, while our Supertokens achieve notable compression gains. Our zero-shot perplexity results demonstrate that the TokenAdapt hybrid initialization consistently yields lower perplexity ratios compared to both ReTok and TransTokenizer baselines across different base models and newly trained target tokenizers. TokenAdapt typically reduced the overall perplexity ratio significantly compared to ReTok, yielding at least a 2-fold improvement in these aggregate scores.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.