- The paper introduces a unified framework (UCGM) that integrates diffusion, flow-matching, and consistency models using a flexible consistency ratio to transition between paradigms.
- The methodology employs a Unified Trainer (UCGM-T) and Unified Sampler (UCGM-S) to optimize training and sampling efficiency, achieving an FID of 1.30 in 20 steps on ImageNet.
- The framework’s self-boosting mechanism and reduced computational overhead highlight its potential to advance practical and theoretical generative modeling research.
Unified Continuous Generative Models
Introduction
The emergence of diffusion models, flow-matching models, and consistency models has marked a significant advancement in the domain of continuous generative models. These approaches have primarily been developed independently, each characterized by distinct training and sampling methods despite their shared goal of generating high-fidelity data. This paper introduces a novel framework, Unified Continuous Generative Models (UCGM), which aims to bridge these methodologies by providing a unified framework for training and sampling. UCGM showcases state-of-the-art performance across ImageNet datasets, elevating the capabilities of multi-step diffusion models and few-step consistency models alike.
Methodology
UCGM introduces a Unified Trainer (UCGM-T) and a Unified Sampler (UCGM-S) designed to integrate and enhance existing paradigms under a unified objective. The trainer incorporates a consistency ratio parameter (λ∈[0,1]), enabling a transition between few-step models like consistency models and multi-step paradigms such as diffusion and flow-matching models. The training objective is flexible enough to accommodate various noise schedules without requiring specific alterations.
In parallel, UCGM-S is capable of optimizing sampling from models trained by UCGM-T and can be efficiently applied to pre-trained models developed with separate paradigms. The proposed self-boosting mechanisms significantly improve the training and sampling efficiency, reducing computational overhead and enhancing sample quality without the need for classifier-free guidance.
Experimental Results
UCGM demonstrates substantial improvements in sampling efficiency and fidelity. When applied to a 675M diffusion transformer model trained on ImageNet 256×256, UCGM-T achieves an FID of $1.30$ with only $20$ sampling steps. Notably, the application of UCGM-S to models pre-trained under previous paradigms achieved an FID of $1.06$ in just $40$ steps, a remarkable enhancement over traditional methodologies (Figure 1).


Figure 1: NFE~=40, FID~=1.48.
To highlight its versatility, UCGM was tested across varied lambda settings and sampling steps, demonstrating exceptional adaptability (Figure 2).
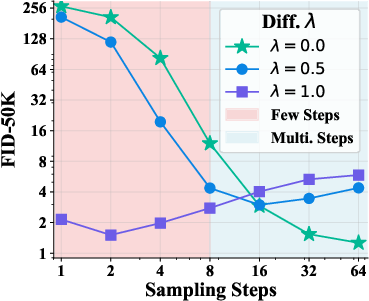
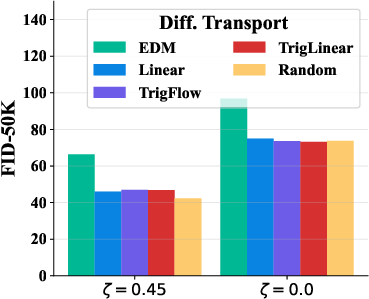
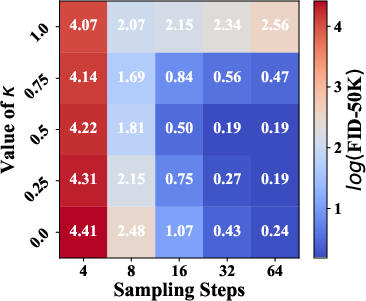
Figure 2: Various lambda and sampling steps.
Implications and Future Directions
The introduction of UCGM presents a significant paradigm shift in generative modeling, offering a cohesive approach that reconciles the strengths of diffusion, flow-matching, and consistency paradigms. Practically, this framework reduces the computational burden, making high-quality generative models more accessible. Theoretically, UCGM paves the way for more integrated research across model types, fostering innovations that leverage the fundamental similarities between these seemingly disparate methods.
Future work should explore further enhancements to UCGM's self-boosting techniques, as well as the potential for UCGM to integrate with emerging generative models beyond the current scope. Additionally, exploring the impact of alternative lambda schedules could provide deeper insights into the fundamental mechanics of model transitions within UCGM.
Conclusion
Through its innovative architecture, UCGM effectively consolidates various continuous generative modeling techniques, setting a new standard for efficiency and quality. This unified approach not only simplifies the training and deployment of generative models but also opens avenues for new research into adaptive generative systems. UCGM stands as a crucial development in the ongoing evolution of AI-based data generation.