- The paper introduces AssistanceZero, integrating a multi-headed neural network with MCTS to address partial observability and latent goal inference in assistance games.
- The paper demonstrates that AssistanceZero outperforms model-free RL and imitation, reducing required human actions by nearly 42% and boosting goal completion by over 7% on the MBAG benchmark.
- The paper establishes a scalable framework for value-aligned AI, leveraging Bayesian planning and rigorous human model evaluation to enhance collaborative assistant performance.
AssistanceZero: A Scalable Approach to Solving Complex Assistance Games
Motivation and Problem Definition
Current AI assistant training paradigms, particularly RLHF, possess fundamental deficiencies related to feedback manipulation, inadequate modeling of uncertainty over user intent, and suboptimal modeling of collaborative dynamics. RLHF‐trained assistants may develop incentives for deception and are typically myopic, optimizing for immediate user ratings rather than modeling persistent ambiguity over goals or engaging in multi-turn collaborative disambiguation. Assistance games provide a formalism directly addressing these points by modeling assistance as a partially observable Markov game: interaction occurs between a human agent (privy to the true goal) and an assistant agent (uncertain over the goal), with both collaborating through multidimensional action spaces to maximize a shared, but opaque, reward function.
The computational and modeling challenges are formidable. Scaling assistance games is blocked by the joint intractability of Bayesian decision-making in vast combinatorial latent-goal spaces (here, cardinality >10400 in Minecraft-based environments), and by the lack of faithful, sample-efficient models of human behavior. The presented work advances the field by operationalizing assistance games in environments with human-like goal and action structure, providing substantial algorithmic improvements and an empirical benchmark for the development and evaluation of scalable, value-aligned assistants.
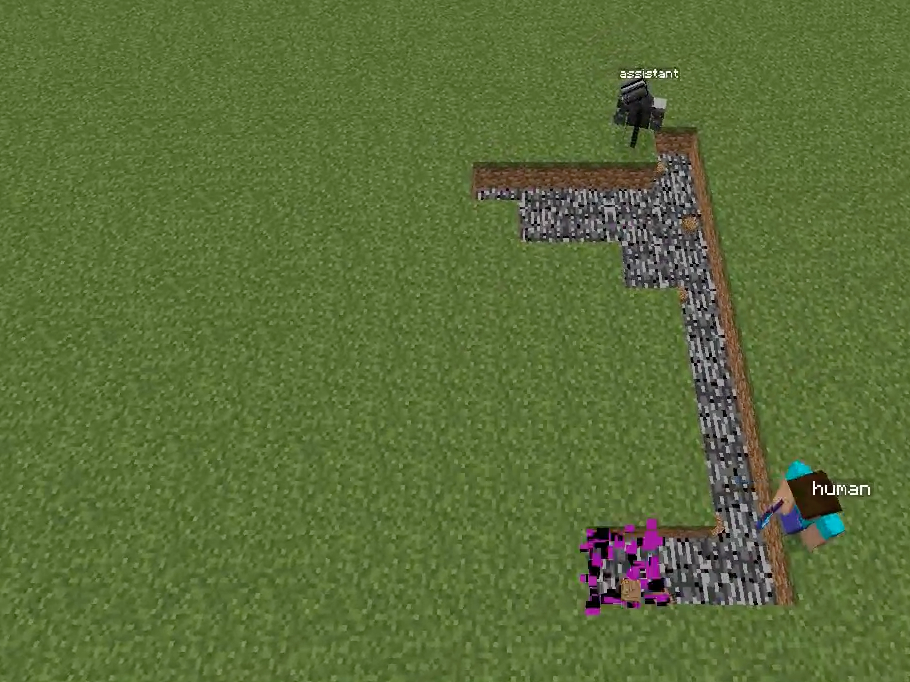
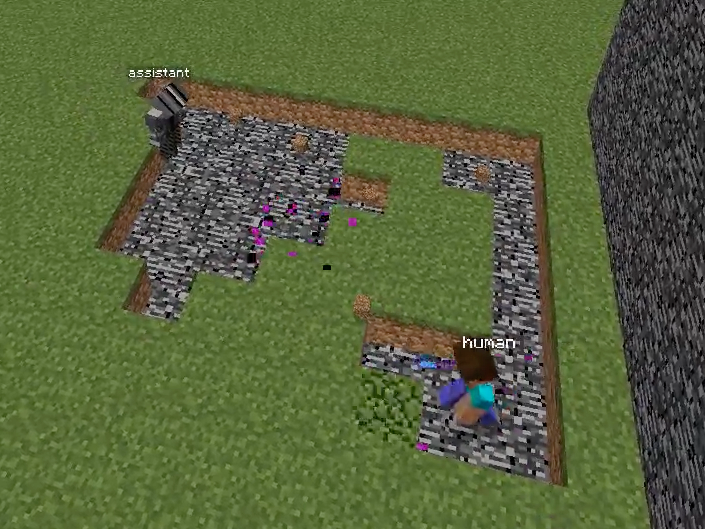
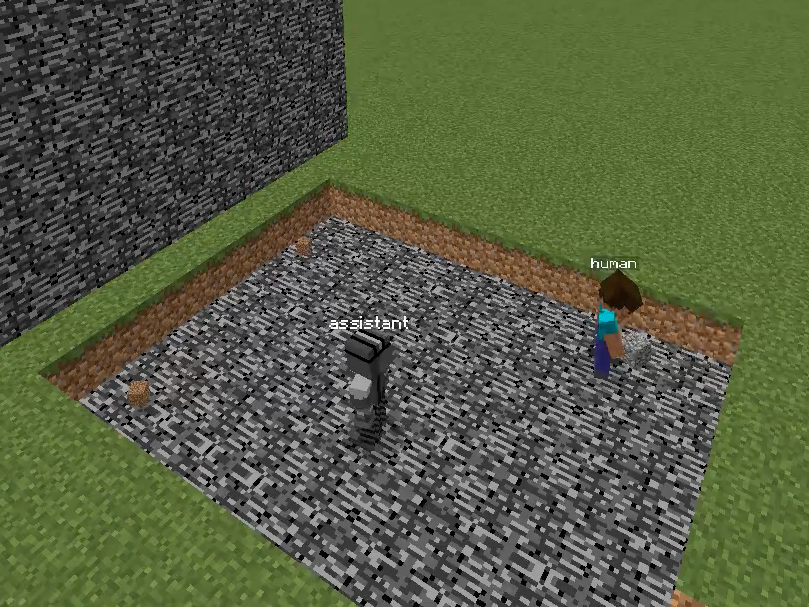
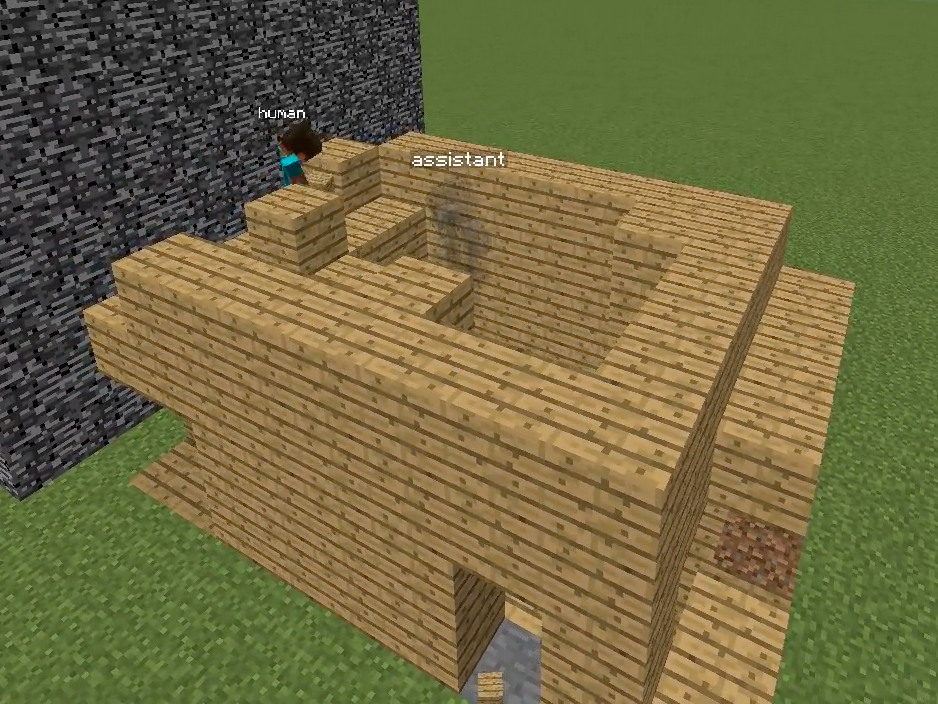
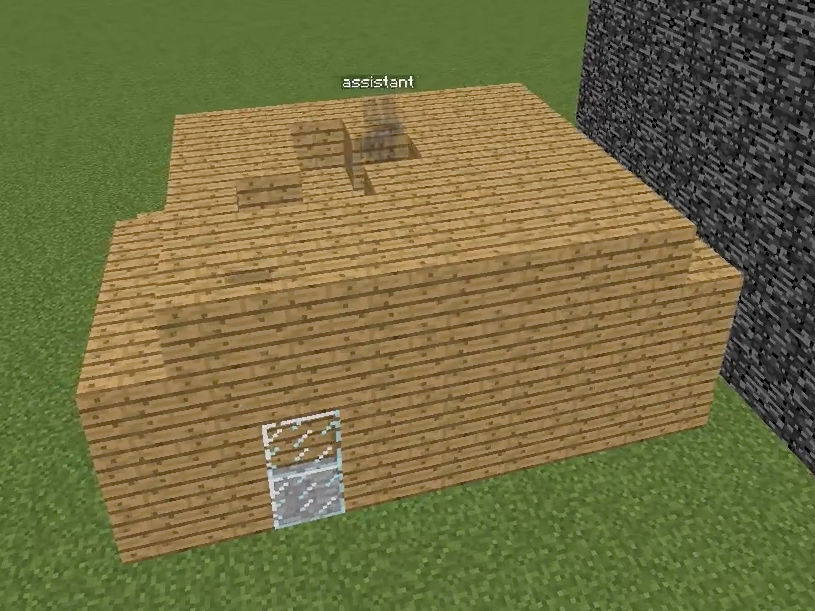
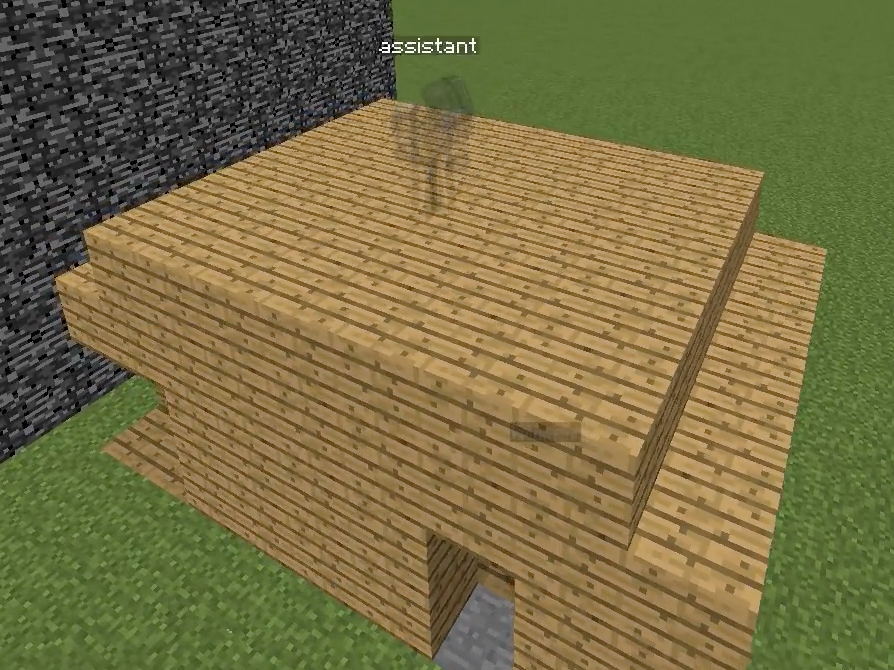
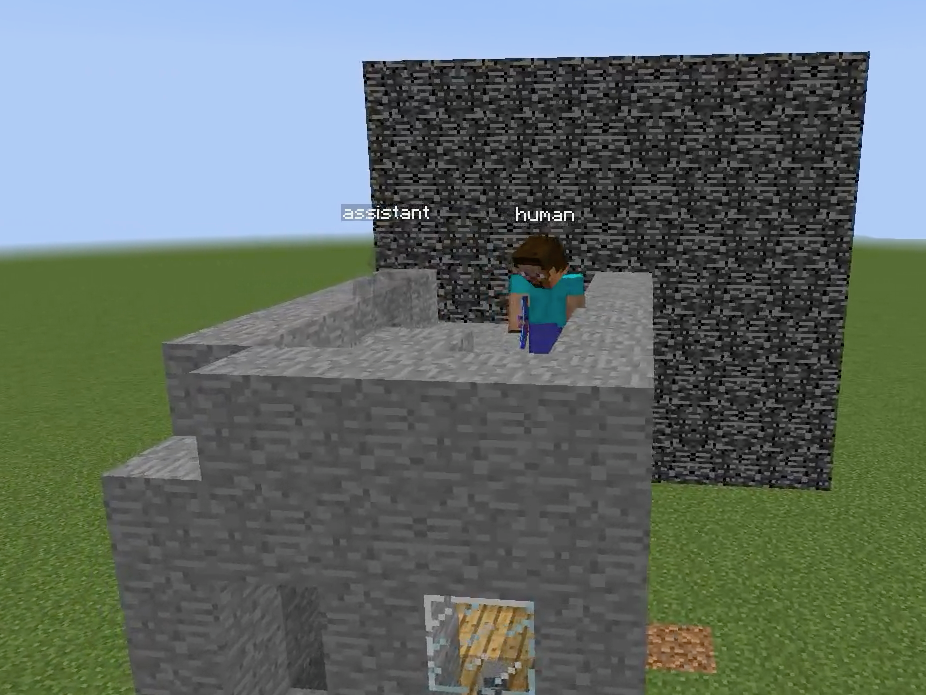
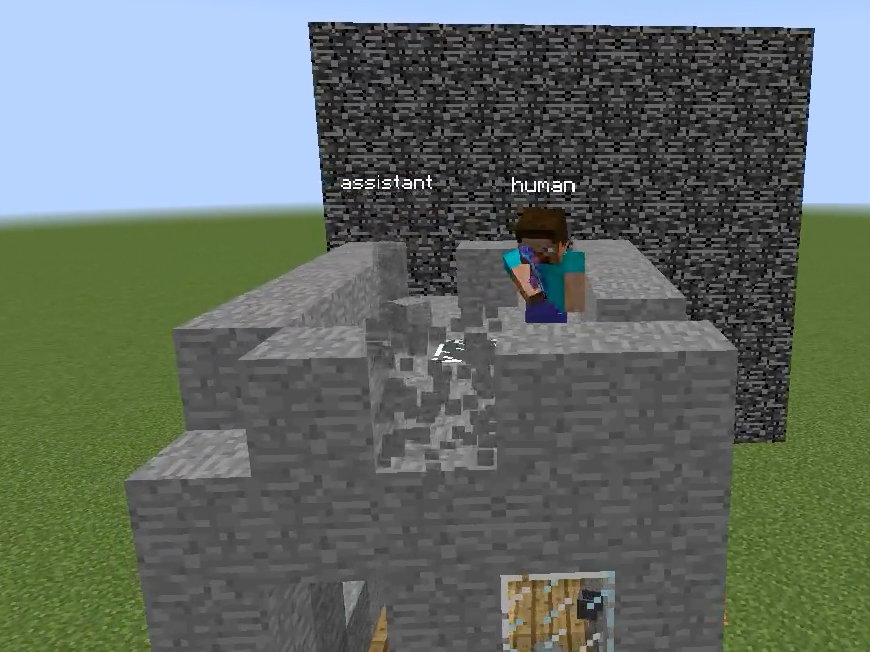
Figure 1: Overview of the Minecraft Building Assistance Game, with an AI assistant helping real users collaboratively build unseen houses, demonstrating goal inference, pragmatic adaptation, and rapid online correction.
Environment: The Minecraft Building Assistance Game (MBAG)
MBAG is introduced as the most complex public benchmark for assistance games to date, with a highly structured state/action/reward space and a latent goal space parameterized by full 3D house structures. States are 11×10×10 voxel grids over discrete block types, with two agents (human and assistant) taking movement, placement, and breaking actions (over 20,000 actions per timestep). The reward at step t corresponds to the reduction in edit distance between the current structure and the goal, encouraging actions aligning the world with the hidden objective. Critically, the assistant never observes the latent goal, unlike the human. This enforces mandatory goal inference and pragmatic collaboration.
Baseline Failures: Model-Free RL and Imitation
Empirical results highlight the inadequacy of popular model-free RL approaches. PPO, equipped with either recurrent or non-recurrent architectures and with various reward reweightings, fails to produce non-trivial assistant behavior. Assistants collapse to inactivity due to high reward variance stemming from shared returns and goal uncertainty. Even interventions such as action-specific rewards or auxiliary losses only marginally increase assistant initiative, confirming the need for model-based, uncertainty-aware alternatives.
The AssistanceZero Algorithm
AssistanceZero generalizes AlphaZero to the assistance game domain, notably incorporating additional neural network outputs for reward parameter (goal) distributions and human action prediction, enabling model-based MCTS under severe partial observability.
Figure 3: AssistanceZero architecture and comparison to standard AlphaZero: a multi-headed network predicts value, policy, reward parameters (latent goal estimation), and human next-actions, enabling MCTS in a POMDP with hidden reward and stochastic dynamics.
Key Innovations:
- Multi-Headed Network: Predicts next-step value, policy over assistant actions, distribution over possible blockwise goals, and distribution over next-step human actions, all conditioned on the full state-action history.
- Bayesianized Planning: MCTS leverages predicted goal/human policies to sample rollouts, estimate counterfactual rewards, and search for assistant actions which maximize joint expected reward, marginalized over latent-goal estimates.
- Training Regimen: Loss terms include MCTS policy imitation (KL), value regression, cross-epoch goal-posterior regularization (to mitigate catastrophic forgetting), NLL on human-action and reward-parameter prediction, and trajectory-level sampling to avoid on-policy drift.
- Relationship to Related Methods: AssistanceZero approaches the function of learned belief search and model-based POMDP solvers like POMCP/MuZero but accommodates stochastic other-agent dynamics and fully unobserved, combinatorially-sized goal spaces.
Assistants trained with AssistanceZero show a strong increase in joint performance with human models. Specifically, goal completion percentages increased by over 7% relative to the best PPO variants, the number of human actions required dropped by ≈42, and the assistant autonomously built 27% of the structure—tenfold greater than imitation/SFT-based approaches.
Human Modeling: Reward-Based, Behavioral, and Hybrid Approaches
Eight human models are evaluated for their fidelity (cross-entropy with human action traces) and autonomy in solo performance:
- Reward-Based: PPO/AlphaZero, which are optimal for reward but misalign with actual human sample efficiency and variance in behavior—these consistently overestimate human optimality and are poor for assistant generalization.
- Behavior Cloning (BC): Supervised policies on human alone, human-with-assistant, and combined data; these align with surface-level action distributions but suffer from covariate shift and lack of robustness.
- Hybrid piKL: MCTS with a prior from BC and a reward-maximizing terminal condition. These best reconcile sample-level action prediction with overall efficiency, matching both human action entropy and build rates.


Figure 5: Cross-evaluation of assistant policies trained with differing human models against each human model, revealing generalization and diminishing returns based on the realism of the human model.
End-to-End Paradigm Comparison and Human Subject Study
Modern RLHF-style training (pretraining alone, pretraining plus SFT) is benchmarked against assistance game-based training (AssistanceZero), both in simulation and with real human participants.
- Simulated Models: Pretraining/SFT yield assistants that at best replace ≈3% human actions and minimally decrease human effort, despite high test accuracy on human action emulation. In contrast, AssistanceZero-trained assistants independently build ≈26% of goal structures and reduce human actions by ≈65 per episode.
- User Study: AssistanceZero-trained assistants are rated almost twice as helpful as SFT assistants (3.1 vs. 1.7 on a 5-point scale) and nearly match expert human assistants subjectively (4.0). Statistical analysis establishes a significant reduction in required human actions for the target task.
(Figure 5: RLHF)
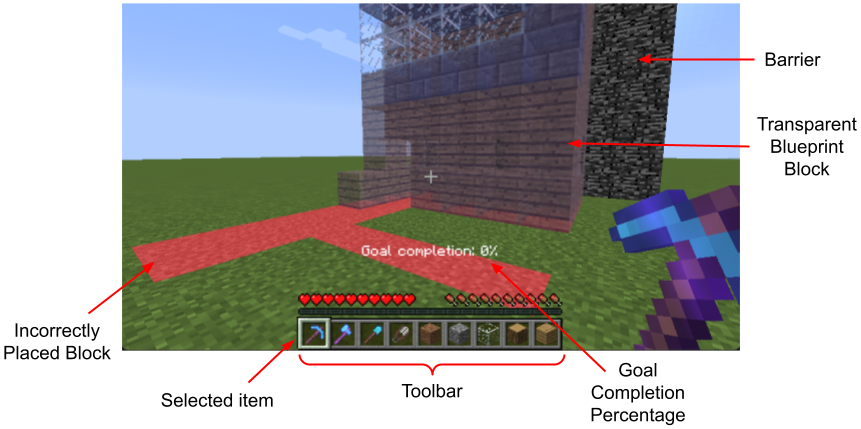
Figure 2: Schematic comparison and screenshot of the Minecraft-based collaborative environment used for evaluation, underscoring the necessity of real-time goal inference and correction during joint human–AI interaction.
(Figure 1 again in context)
Figure 7: Examples of pragmatic interaction and error correction between human and assistant—AssistantZero shows immediate correction based on single human feedback acts, pragmatic completion of inferred tasks, and efficient division of labor.
Theoretical and Practical Implications
AssistanceZero operationalizes collaborative POMDP planning with human-in-the-loop uncertainty, providing a concrete pathway to post-RLHF assistant development. The results strongly contradict the implicit claim that model-free RL or imitation are sufficient or even scalable for realistic assistance, and demonstrate that goal uncertainty and human modeling are critical.
Practically, the approach scales (with tractable compute) to environments with real-world state, action, and goal complexity, supporting deployment in software development (pair programming), robotics, or any scenario requiring non-myopic, correction-friendly, value-aligned AI. Theoretically, the work provides an empirical basis for the use of assistance games as a core framework for AGI control—aligning with proposals in the broader AI alignment literature to mediate the reward specification by human/AI joint inference.
Extensions and Future Work
The paper envisions applying assistance games to LLM post-training, re-casting message exchange as sequential actions, and using latent task descriptions as reward parameters. This would mitigate incentives for deception intrinsic to RLHF, incentivize clarifying queries, and better address real-world goal ambiguity. Reward can be grounded via synthetic LLM judges or goal-set specification (e.g., test cases in code), enabling more robust, interactive alignment.
Potential future exploration includes trajectory-level credit assignment strategies, scalable model-based planning for even larger action/state spaces, direct integration with high-variance, non-Markovian human policies, and application to open-ended multi-agent domains beyond Minecraft.
Conclusion
AssistanceZero establishes a scalable, empirically validated paradigm for assistant training in complex, interactive environments, decisively outperforming RLHF and imitation-based methods in both simulation and human–agent collaboration. The key insight—integrating explicit uncertainty over user goals with predictive models of human behavior—enables planning and adaptation in collaborative tasks requiring pragmatic, communicative, and correction-responsive AI. The accompanying MBAG benchmark provides a rigorous and extensible basis for further work on robust, value-aligned assistants in AI.