- The paper introduces a method to identify independent reasoning steps and execute them concurrently, reducing sequential decoding overhead.
- It utilizes a tree-like attention mask to simultaneously decode multiple tokens, significantly speeding up processes in tasks like retrieval and planning.
- Experimental results demonstrate up to 100% faster decoding with maintained or slightly improved answer quality in multi-document QA and planning tasks.
Accelerate Parallelizable Reasoning via Parallel Decoding within One Sequence
Introduction
The paper "Accelerate Parallelizable Reasoning via Parallel Decoding within One Sequence" addresses the inefficiency of generating lengthy reasoning sequences in LLMs. While recent reasoning models have enhanced accuracy through detailed processes, these come at significant computational costs. The proposed method leverages parallelizable tasks within reasoning sequences to decode multiple tokens per forward pass via a tree-like attention mask, maintaining answer quality and conserving memory usage.
Methodology
The presented method comprises three stages aimed at exploiting parallelizable steps in reasoning tasks:
- Identification of Parallelizable Steps: Tasks that can be decomposed into independent steps are recognized using a special mark to denote the beginning of steps that can occur concurrently. Only the titles of these steps are generated sequentially to minimize output tokens.
- Parallel Decoding: Utilizing a tree-like attention mask, each step is treated as an independent branch, enabling the simultaneous generation of tokens for each branch in a single forward pass. This significantly accelerates generation while sharing non-parallel tokens across branches.
- Concatenation and Continuation: After decoding, the content of these parallel steps is concatenated with non-parallel parts, allowing the model to resume its reasoning process effectively.
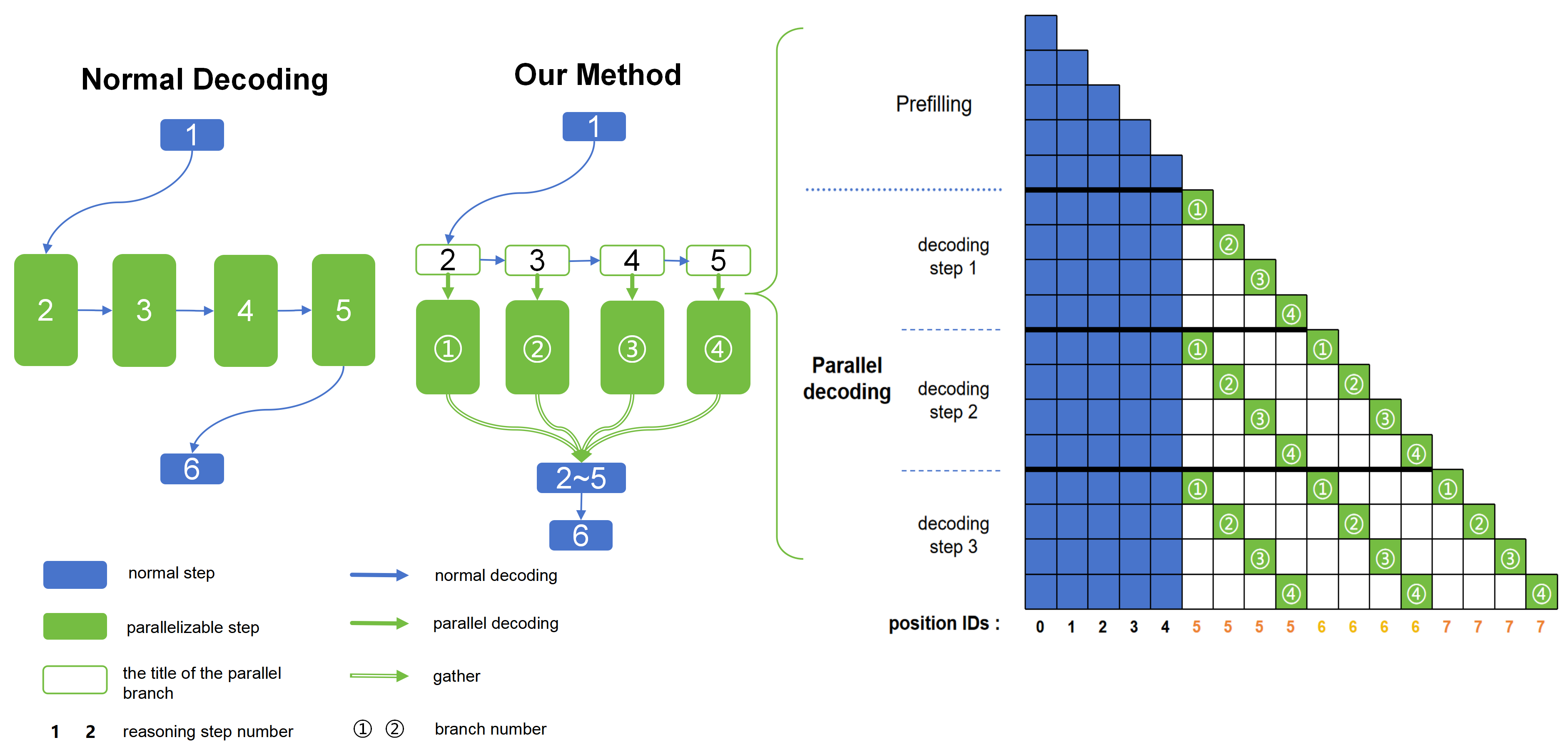
Figure 1: Comparison between our method and traditional decoding for a case with six steps where four are parallelizable.
Experimental Results
The proposed method was tested across three parallelizable tasks: retrieval, multi-document QA, and planning. The decoding speed showed significant enhancements, nearly doubling for retrieval without affecting accuracy, indicating the method's efficacy for retrieval tasks. Multi-document QA tasks saw a 60% increase in decoding speed, with a slight improvement in answer quality. For planning tasks, the decoding speed improved by over 50%, maintaining acceptable levels of accuracy.
Comparatively, methods like Skeleton-of-Thought (SoT) and Chain-of-Draft (CoD) demonstrated faster inference but suffered from quality degradation and increased memory usage. The proposed method stood out by eliminating these drawbacks, making it suitable for various parallelizable reasoning tasks.
Implications and Future Directions
This decoding approach facilitates greater efficiency in scenarios with constrained computational resources without compromising on task performance. The method operates without additional memory consumption or KV cache recomputation, offering flexible applicability across different models and architectures. Future research could explore extending the method to cater to more complex task scenarios or adapting it for diverse LLM architectures and sizes.
Conclusion
The paper presents "Parallel Decoding in One Sequence," a technique that accelerates reasoning tasks by prompting and modifying attention masks to effectively decode parallelizable steps. This approach achieves a balance between speed and answer quality while maintaining the flexibility and adaptability of LLMs. Future work could further explore its applicability to broader task types and model designs, offering a promising direction for efficient LLM reasoning.

