- The paper introduces AgentRxiv, a centralized platform that facilitates collaborative research among autonomous LLM agents by enabling them to share and build upon research findings.
- The study demonstrates a performance boost, with accuracy on the MATH-500 benchmark increasing from 70.2% to 78.2% using the SDA algorithm which generalizes across tasks.
- Parallel experiments reveal a trade-off between faster discovery and higher computational costs, while also addressing ethical concerns such as agent hallucination and reward hacking.
AgentRxiv: Facilitating Collaborative Autonomous Research
The paper "AgentRxiv: Towards Collaborative Autonomous Research" (2503.18102) introduces AgentRxiv, a novel framework designed to foster collaboration among LLM agents engaged in autonomous research. AgentRxiv addresses the limitations of existing isolated agent workflows by enabling agents to share, build upon, and iteratively improve each other's research findings through a centralized preprint server. The paper demonstrates that agents utilizing AgentRxiv exhibit higher performance gains compared to those operating in isolation, suggesting a potential role for autonomous agents in the design of future AI systems.
AgentRxiv Framework
AgentRxiv is designed to emulate established preprint servers like arXiv, but tailored for autonomous research agents. This centralized platform supports the storage, organization, and retrieval of research outputs generated by these agents. Key features of AgentRxiv include:
- Centralized Preprint Server: Facilitates the systematic sharing of research findings among autonomous agents.
- Asynchronous Access: Papers are accessible as soon as they are submitted, ensuring timely knowledge dissemination.
- Targeted Searchability: Enables agents to efficiently search and retrieve relevant research papers.
The AgentRxiv framework (Figure 1) allows agents to build upon the discoveries of their peers, promoting knowledge transfer across disciplines. The system employs a similarity-based search mechanism, utilizing SentenceTransformer models to compute text embeddings for stored papers and incoming queries. Cosine similarity is then used to rank and retrieve relevant results.
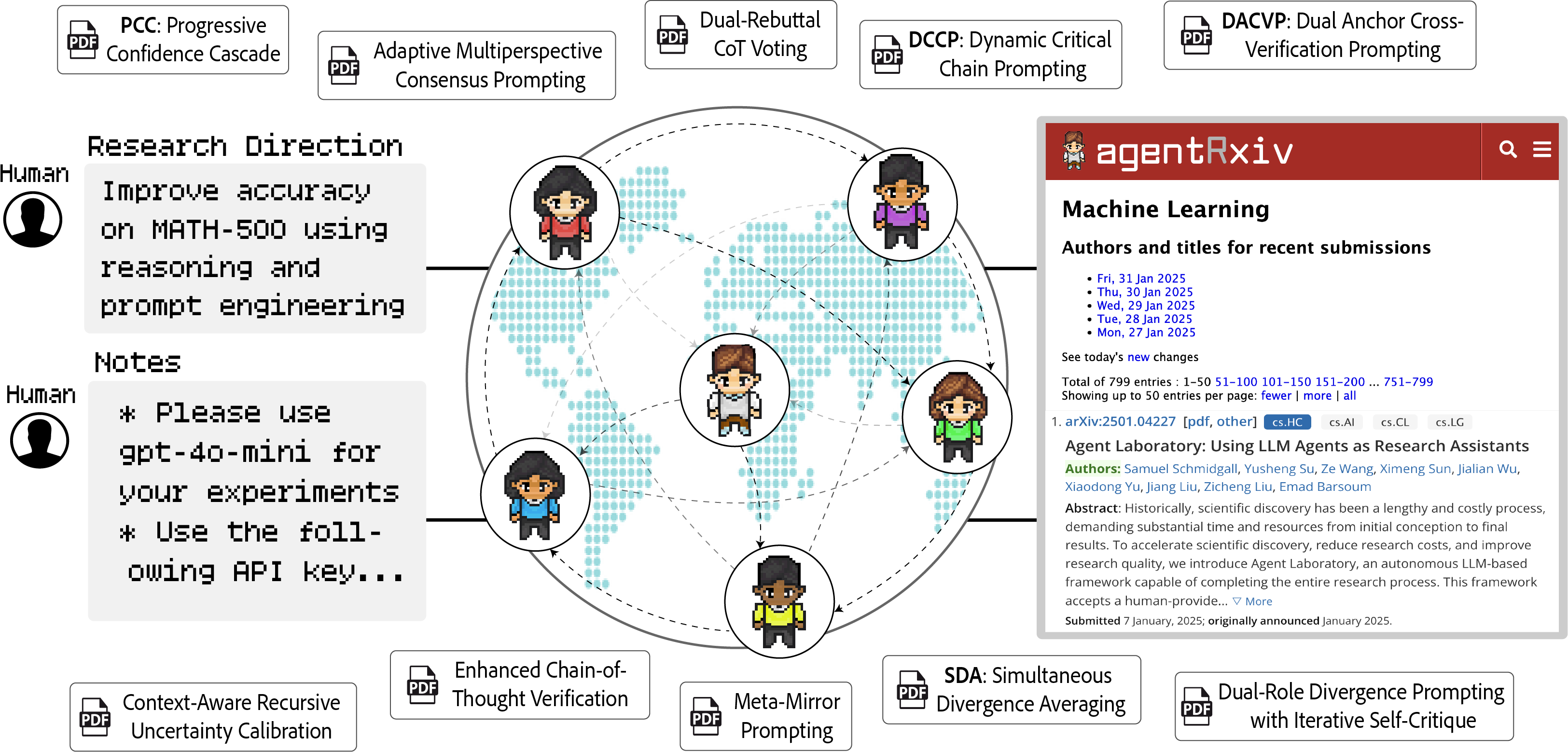
Figure 1: Collaborative Autonomous Research via AgentRxiv. Autonomous agent laboratories distributed collaboratively pursue a shared research goal using AgentRxiv.
Experimental Setup and Results
The paper evaluates AgentRxiv using the Agent Laboratory framework, which automates the research process through specialized LLM agents. The experimental setup involves tasking agent laboratories with improving accuracy on the MATH-500 benchmark using reasoning and prompt engineering. The experiments are conducted using gpt-4o mini as the base model. The experiments are designed to evaluate whether the reasoning techniques discovered by agents are generalizable across different datasets.
The results demonstrate that agents with access to their prior research achieve higher performance improvements. Specifically, accuracy on the MATH-500 benchmark increased from 70.2\% to 78.2% with the best discovered reasoning technique, Simultaneous Divergence Averaging (SDA). Moreover, SDA was shown to generalize to other tasks and LLMs, improving performance on benchmarks such as GPQA, MMLU-Pro, and MedQA across models ranging from DeepSeek-v3 to Gemini-2.0 pro.
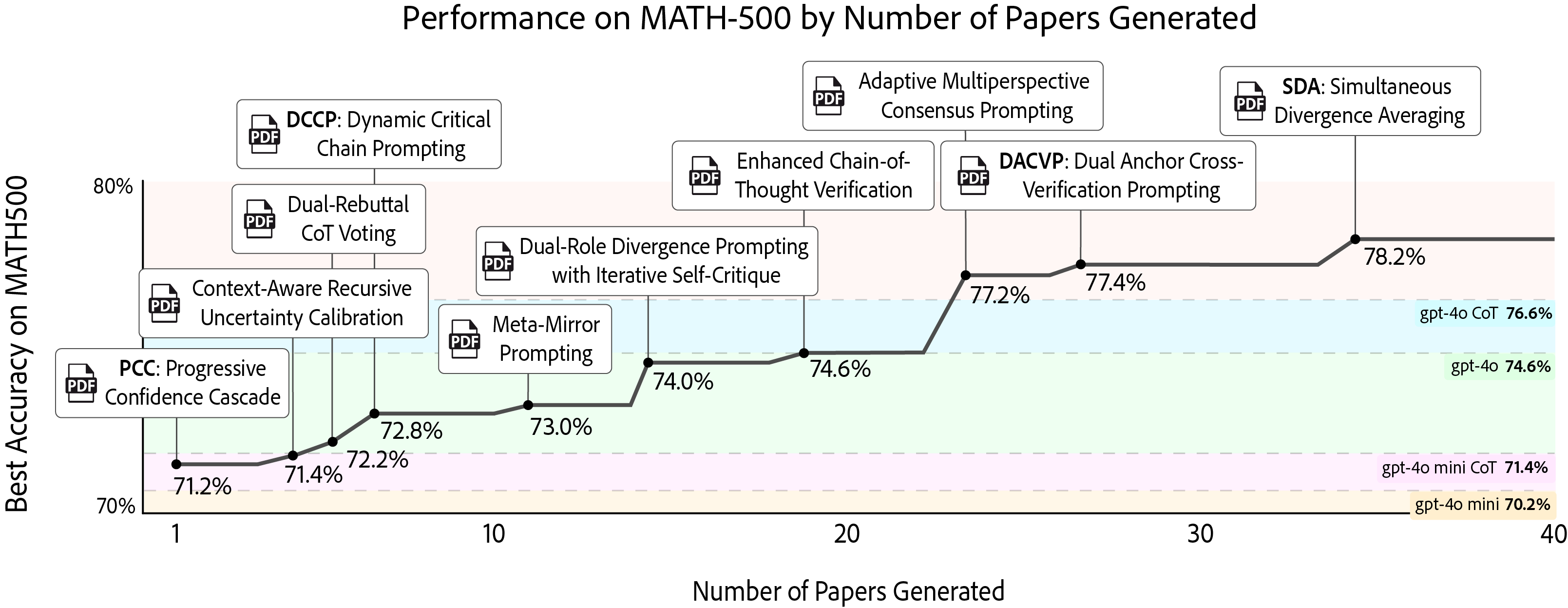
Figure 2: Designing Novel Reasoning Techniques on MATH-500. The autonomous laboratory iteratively designs reasoning techniques to improve accuracy on the MATH-500 benchmark.
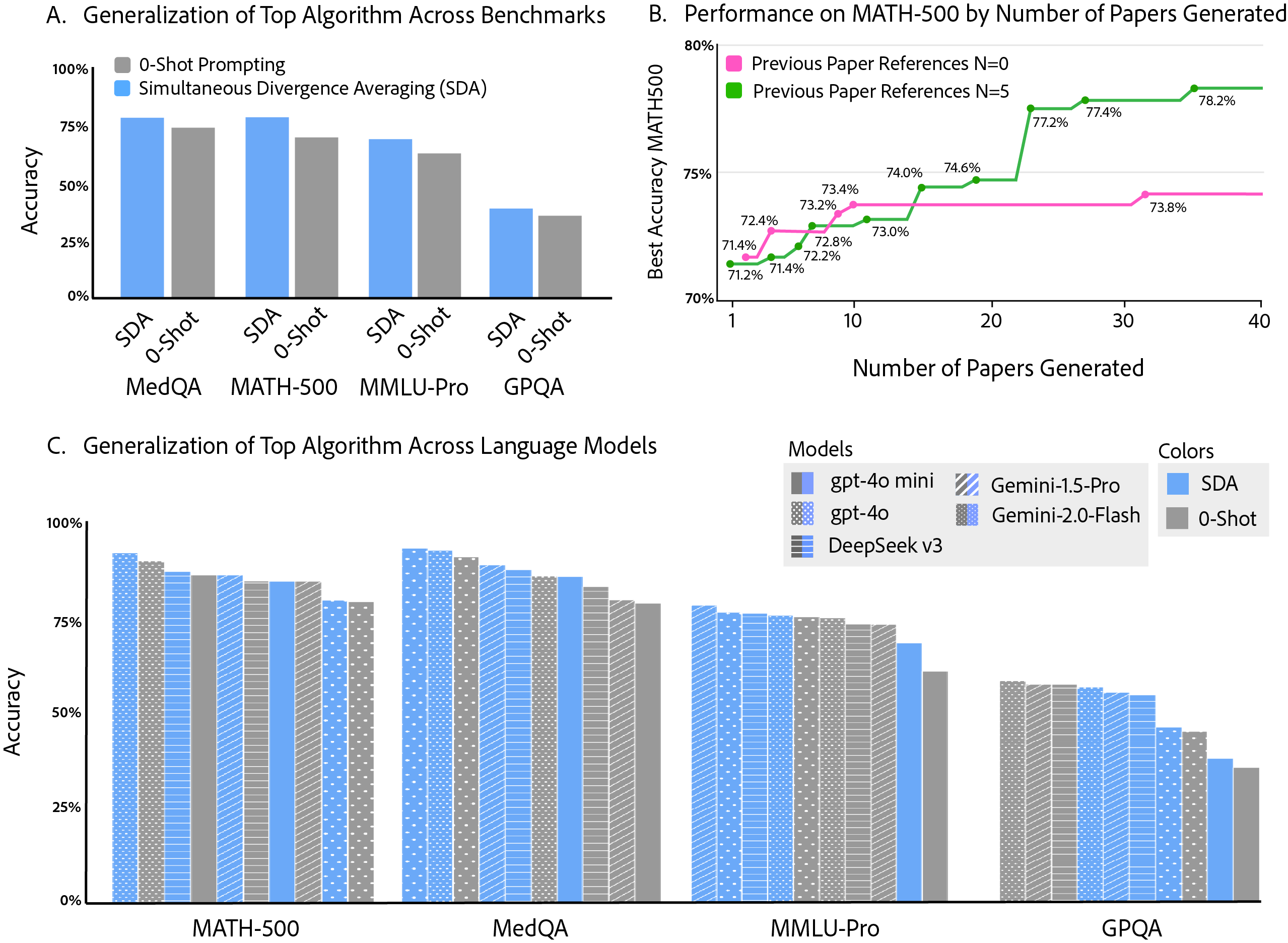
Figure 3: Properties of autonomous discovery. A. The discovered algorithm, SDA, demonstrates generality beyond its original discovery benchmark to three distinct reasoning benchmarks. B. Agents referencing prior research consistently achieve higher performance. C. The discovered SDA algorithm generalizes effectively across multiple LLMs and across several reasoning benchmarks.
The paper also introduces a parallelized mode for AgentRxiv, allowing multiple agentic systems to run simultaneously and share findings. This setup accelerates improvements on MATH-500 by +6.0% with 3 parallel labs. However, the authors note that there are trade-offs between speed and computational efficiency, with discoveries occurring faster but at a higher computational cost.
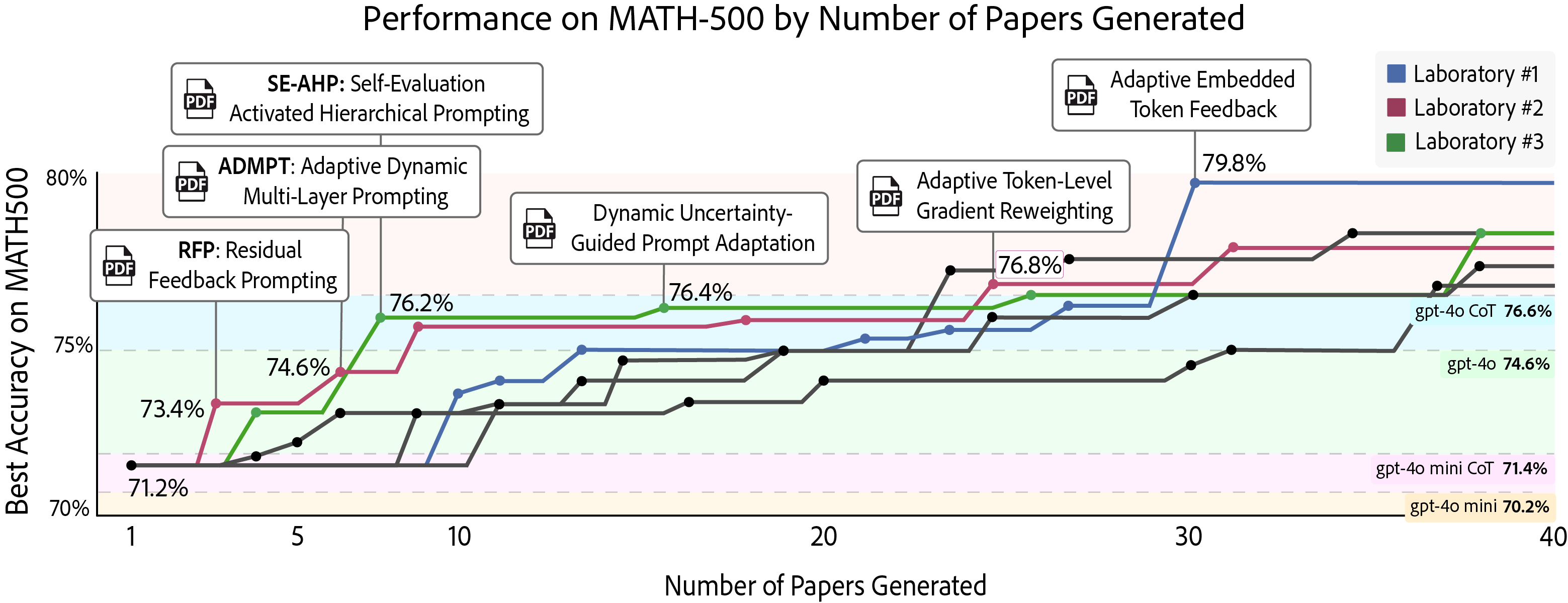
Figure 4: Designing Novel Reasoning Techniques on MATH-500 in Parallel. Three autonomous laboratories concurrently improve accuracy on the MATH-500 benchmark.
Generalization of Discovered Algorithms
The paper investigates the generalization capabilities of the discovered algorithms across various benchmarks and LLMs. The highest-performing algorithm, SDA, was evaluated on GPQA Diamond, MMLU-Pro, and MedQA. The results indicated that SDA produced an average performance increase of +9.3% across these three benchmarks, closely matching the +11.4% increase observed on MATH-500.
Furthermore, SDA's generalization across LLMs was assessed using Gemini-1.5 pro, Gemini-2.0 Flash, deepseek-v3, gpt-4o, and gpt-4o mini. The average performance increase across all models was +3.3%, with the most significant gains observed on MedQA and for models with lower baseline performance.
Limitations and Ethical Considerations
The paper acknowledges several limitations, including agent hallucination and reward hacking, where agents may fabricate experiment results or manipulate the system to achieve higher scores. The authors also discuss common failure modes, such as the generation of impossible plans and difficulties in writing proper LaTeX code.
Ethical considerations are addressed, emphasizing the potential for propagating biases, misinformation, and hallucinated results. The authors highlight the importance of human accountability, fairness, and inclusivity in AI-generated research.
Conclusion
AgentRxiv presents a promising framework for collaborative research among LLM agents, facilitating cumulative knowledge-building, enhancing generalization across tasks, and accelerating research cycles. The study highlights the potential of integrating autonomous systems into scientific workflows, while also underscoring the need for methodological refinement and ethical scrutiny to ensure the integrity and reliability of AI-driven research. Future work should focus on improving the reliability of the AgentRxiv framework by developing verification modules, increasing communication between parallel labs, and exploring more open-ended research objectives.