Rethinking Multi-Modal Object Detection from the Perspective of Mono-Modality Feature Learning
Published 14 Mar 2025 in cs.CV | (2503.11780v2)
Abstract: Multi-Modal Object Detection (MMOD), due to its stronger adaptability to various complex environments, has been widely applied in various applications. Extensive research is dedicated to the RGB-IR object detection, primarily focusing on how to integrate complementary features from RGB-IR modalities. However, they neglect the mono-modality insufficient learning problem, which arises from decreased feature extraction capability in multi-modal joint learning. This leads to a prevalent but unreasonable phenomenon\textemdash Fusion Degradation, which hinders the performance improvement of the MMOD model. Motivated by this, in this paper, we introduce linear probing evaluation to the multi-modal detectors and rethink the multi-modal object detection task from the mono-modality learning perspective. Therefore, we construct a novel framework called M$2$D-LIF, which consists of the Mono-Modality Distillation (M$2$D) method and the Local Illumination-aware Fusion (LIF) module. The M$2$D-LIF framework facilitates the sufficient learning of mono-modality during multi-modal joint training and explores a lightweight yet effective feature fusion manner to achieve superior object detection performance. Extensive experiments conducted on three MMOD datasets demonstrate that our M$2$D-LIF effectively mitigates the Fusion Degradation phenomenon and outperforms the previous SOTA detectors. The codes are available at https://github.com/Zhao-Tian-yi/M2D-LIF.
The paper identifies fusion degradation in multi-modal object detection and proposes the M²D-LIF framework to enhance mono-modality feature learning.
It employs a teacher-student distillation approach alongside a brightness-aware fusion mechanism to optimize feature extraction and fusion.
Experiments on DroneVehicle, FLIR, and LLVIP datasets demonstrate state-of-the-art mAP improvements with a low parameter count.
Rethinking Multi-Modal Object Detection
This paper (2503.11780) addresses the issue of insufficient mono-modality feature learning in multi-modal object detection (MMOD), which leads to a phenomenon called "Fusion Degradation." The authors introduce a novel framework, M2D-LIF, comprising Mono-Modality Distillation (M2D) and Local Illumination-aware Fusion (LIF), to enhance mono-modality learning and achieve superior object detection performance.
Identifying Fusion Degradation
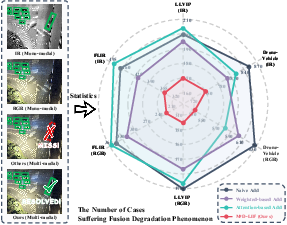
The authors identify a significant problem in MMOD: the "Fusion Degradation" phenomenon. This occurs when objects detectable by a mono-modal detector are missed by a multi-modal detector (Figure 1).
Figure 1: An illustration of the Fusion Degradation phenomenon, showing missed detections by multi-modal methods compared to mono-modal methods, along with statistics of its prevalence.
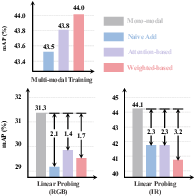
To investigate the underlying causes, the paper employs a linear probing evaluation. Mono-modal and multi-modal object detectors are trained, and their backbones are evaluated by freezing them and training new detection heads. The results indicate that multi-modal joint training leads to insufficient learning of each modality, which limits the overall detection performance (Figure 2).
Figure 2: Linear probing evaluation on the FLIR dataset, demonstrating the performance of different feature fusion methods.
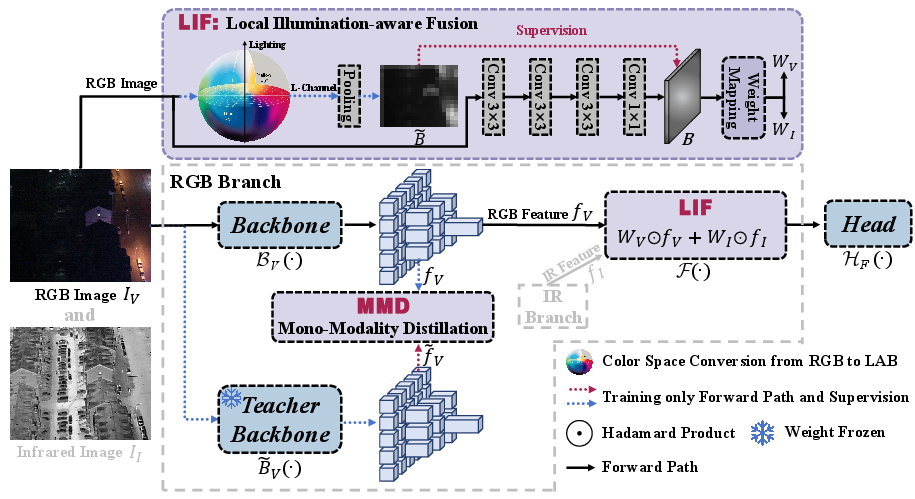
The M2D-LIF Framework
To mitigate the fusion degradation phenomenon, the authors propose the M2D-LIF framework. This framework facilitates sufficient learning of mono-modality features during multi-modal joint training and employs a lightweight feature fusion approach. The M2D-LIF framework consists of two main components: Mono-Modality Distillation (M2D) and Local Illumination-aware Fusion (LIF) (Figure 3).
Figure 3: An overview of the M2D-LIF framework, highlighting the Mono-Modality Distillation (M2D) and Local Illumination-aware Fusion (LIF) components.
Mono-Modality Distillation (M2D)
M2D enhances feature extraction by using a teacher-student approach. A pre-trained mono-modal encoder distills knowledge to the multi-modal backbone network. The M2D method incorporates inner-modality and cross-modality distillation losses to optimize the framework during training. The inner-modality distillation loss LIM aligns the multi-modal backbone with the feature responses of the teacher model:
LIM=D(fV,fV)+D(fI,fI)
where D(⋅,⋅) denotes a distillation method, fV and fI are the outputs of the student backbones, and fV and fI are the outputs of the teacher backbones.
The cross-modality distillation loss LCM leverages salient object location priors to guide feature distillation. An attention mechanism, specifically SimAM, extracts salient object feature attention maps, which serve as location priors. The attention map M is calculated as:
M=Sigmoid(4(σ2+λ)(f−μ)2+2σ2+2λ)
The cross-modality feature distillation loss is formulated as:
LCM=D(MV⊙fI,MV⊙fV)+D(MI⊙fV,MI⊙fI)
where MV and MI are the attention maps of different modalities. The overall loss function of M2D is defined as the sum of the inner- and cross-modality loss:
LIF is a weighted-based fusion method that dynamically sets different weights for different illumination regions using a predicted brightness map. The brightness map B is predicted using convolutional layers:
B=ConvBlock(IV)
where IV is the RGB image. The loss function LLI is the L2 norm between the predicted brightness map B and the ground truth B (L channel in LAB color space):
LLI=∣∣B,B∣∣2
The weight generation mechanism adaptively adjusts the weights of different modality features:
{WV=β×min(2αB−α,21)+21,WI=1−WV,
where WV and WI represent the weights of the RGB and infrared modalities, respectively, α is a threshold, and β is the amplitude of WV. The final fused feature fFi is represented as:
fFi=F(fV,fI)=WVi⊙fVi+WIi⊙fIi
The overall loss function is:
L=Ldet+λM2DLM2D+λLILLI
where λM2D and λLI are hyperparameters.
Experimental Results
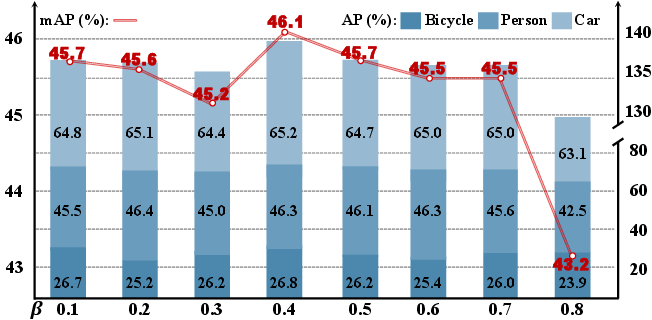
Experiments were conducted on DroneVehicle, FLIR-aligned, and LLVIP datasets. Ablation studies demonstrate the effectiveness of both the M2D and LIF modules. Ablation studies on the hyper-parameter β showed that a value of 0.4 achieved the best results (Figure 4).
Figure 4: A bar chart showing the impact of varying the hyperparameter β on the performance of the M2D-LIF framework.
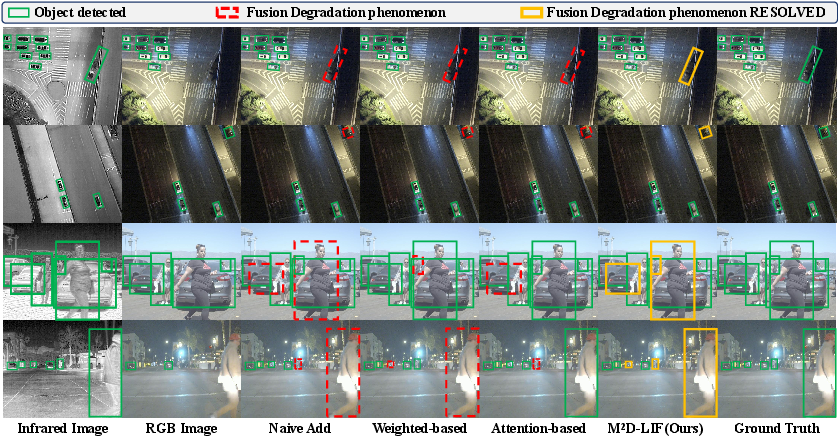
Visualization of detection results demonstrates that M2D-LIF effectively mitigates the Fusion Degradation phenomenon (Figure 5).
Figure 5: Visualizations of Fusion Degradation, comparing the detection results of various methods with M2D-LIF.
The visualization of the LIF weight map shows that the module effectively perceives illumination and assigns higher weights to regions with better lighting conditions (Figure 6).
Figure 6: Visualization of the weight map WV generated by the LIF module, showing its adaptation to local illumination conditions.
Comparison with state-of-the-art methods on the DroneVehicle dataset shows that M2D-LIF achieves the highest mAP50 and mAP of 81.4% and 68.1%, respectively. On the FLIR and LLVIP datasets, M2D-LIF achieves 46.1% and 70.8% mAP, respectively, while maintaining a relatively low parameter count.
Conclusion
The paper (2503.11780) makes a compelling case for rethinking MMOD from a mono-modality learning perspective. The proposed M2D-LIF framework effectively addresses the fusion degradation phenomenon and achieves state-of-the-art performance on multiple datasets. The M2D component enhances mono-modal feature extraction, while the LIF module provides a lightweight yet effective fusion mechanism. This work opens avenues for future research in multi-modal learning, particularly in addressing modality-specific challenges and improving feature fusion strategies.