- The paper presents TRACT, which integrates chain-of-thought reasoning with regression-aware fine-tuning to improve LLM evaluation.
- It employs a two-stage fine-tuning process using self-generated CoTs to mitigate distribution shifts and refine score predictions.
- Experimental results demonstrate superior Pearson correlations versus baselines, underlining its value for educational and content moderation applications.
Overview of the Paper
The paper "TRACT: Regression-Aware Fine-tuning Meets Chain-of-Thought Reasoning for LLM-as-a-Judge" proposes a novel method, TRACT, which enhances the ability of LLMs to perform automatic text evaluation by combining regression-aware fine-tuning with chain-of-thought (CoT) reasoning. This approach aims to improve LLMs' numerical prediction accuracy when assigning scores to texts based on specified rubrics, overcoming the limitations of cross-entropy (CE) loss-based fine-tuning.
Methodology
Chain-of-Thought and Regression-Aware Fine-Tuning
TRACT's methodology consists of two main components: the combination of CoT reasoning with regression-aware training and a two-stage fine-tuning process. Initially, the LLM is fine-tuned to generate CoTs that serve as supervision. Then, a second stage fine-tuning integrates these CoTs with a regression-aware loss function, referred to as CoT-RAFT, which is the sum of a CE loss for learning the CoT reasoning and a regression-aware loss for score prediction.
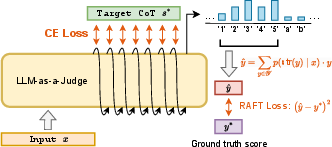
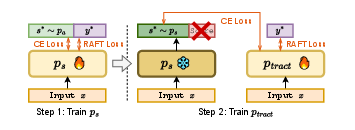
Figure 1: CoT-RAFT fine-tuning objective.
Two-Stage Fine-Tuning Procedure
The proposed two-stage fine-tuning algorithm is crucial for aligning the CoT supervision with the model's CoT distribution, significantly enhancing performance. In the first stage, the model learns from the CoT annotations and ground truth scores. The second stage involves fine-tuning the model using self-generated CoTs, which helps bridge the gap between training and inference CoTs, addressing the distribution shift that occurs when using LLM-generated CoTs at inference time.
Experimental Results
The experiments conducted on multiple datasets demonstrate that TRACT consistently outperforms existing baselines, including models like Prometheus-2-7B, which are fine-tuned on additional data. TRACT achieves superior Pearson correlation coefficients, which measure the alignment between predicted and actual scores, highlighting its effectiveness in numerical assessments.
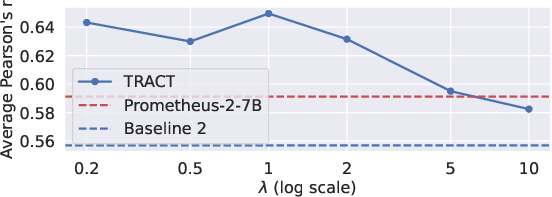
Figure 2: Performance of TRACT across varying values of lambda.
Ablation Studies and Analysis
Extensive ablation studies validate the significance of each component of TRACT, such as the necessity of CoT reasoning and the benefits of self-generated CoTs. The studies reveal that using self-generated CoTs and initializing the second-stage model from the seed LLM considerably enhances performance. Additionally, the sensitivity analysis of the lambda parameter in the CoT-RAFT loss function shows that it performs well across a range of values, with optimal performance achieved around a lambda of 1.
Implementation Considerations
Computational Requirements
TRACT's implementation requires substantial computational resources for the extensive fine-tuning process. The two-stage approach demands iterative training on large LLMs, which can be resource-intensive. Fine-tuning is performed using LoRA, a low-rank adaptation technique, to efficiently adjust model weights without needing to retrain the entire model from scratch.
Practical Implications
In practice, using TRACT can significantly improve the evaluation accuracy of LLMs, making them more reliable for automatic assessment tasks. This improvement is particularly beneficial in educational technology and content moderation, where consistent and accurate scoring is crucial.
Conclusion
TRACT presents a compelling approach to enhancing the numerical prediction capabilities of LLMs by integrating chain-of-thought reasoning with regression-aware fine-tuning. The methodology addresses the inherent limitations of traditional CE loss-based fine-tuning, resulting in models that yield more accurate and reliable evaluations. The results indicate significant advancements over existing methods, especially under constrained computational resources, marking a substantial step forward in the domain of automatic text evaluation.
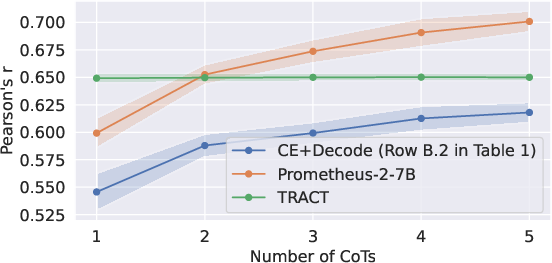
Figure 3: Average Pearson's r as a function of the number of sampled CoTs for Mistral model; showcases TRACT outperforming Prometheus under limited inference budget.
This work not only improves the evaluation ability but also sets a new standard for future research in LLM-based evaluation systems, highlighting the potential for further applications and refinements in model fine-tuning techniques.