- The paper introduces the ExFM framework that efficiently serves trillions-parameter models for online ads recommendation by leveraging external distillation and data augmentation.
- The methodology addresses strict latency constraints and dynamic streaming data challenges by amortizing a foundation model over multiple vertical models.
- Experimental evaluation demonstrates significant performance improvements, including a 1000X inference efficiency gain across various service stages.
Efficient Serving of Trillions-Parameter Models in Online Ads Recommendation
Introduction
The paper "External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation" discusses the challenges and solutions in deploying large foundation models for ads recommendation systems. The focus is on overcoming restrictions in training and inference budgets and addressing data distribution shifts due to streaming data. Large models have shown significant performance improvements, yet their practical deployment in industrial settings is hindered by latency constraints and dynamic data environments.
Core Concept: ExFM Framework
The proposed framework, External Large Foundation Model (ExFM), implements a novel approach using external distillation techniques combined with a Data Augmentation Service (DAS) to maintain high-performance models without incurring extra computational costs. The ExFM framework utilizes a teacher model akin to a foundation model (FM) to serve multiple vertical models (VMs), effectively amortizing the cost of model building and maintenance.
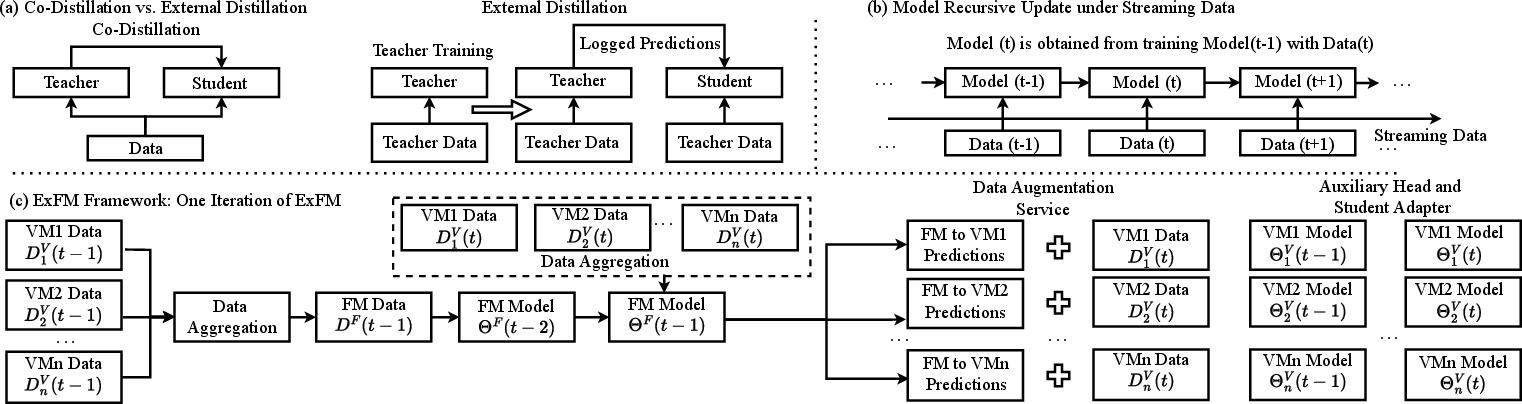
Figure 1: The proposed ExFM framework that enables trillions-parameter model serving with a designed data augmentation system (DAS) and external distillation.
Challenges in Industrial-Scale Applications
Two primary challenges addressed in the paper include:
- C1: Restricted Training and Inference Latency: Ensuring models meet latency requirements is critical for user experience during serving.
- C2: Streaming Data With Shifting Distributions: Continuous data arrival requires models to adapt to real-time changes to avoid overfitting and maintain predictive accuracy.
Components of the ExFM Framework
1. Data Augmentation Service (DAS)
DAS manages FM supervision logging and integrates it with VMs’ training data across distributed settings efficiently.
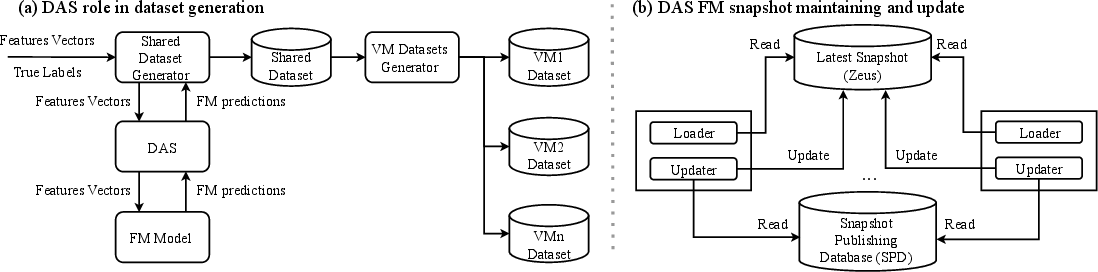
Figure 2: Data Augmentation Service (DAS) strategically enhances training data preparation for VMs.
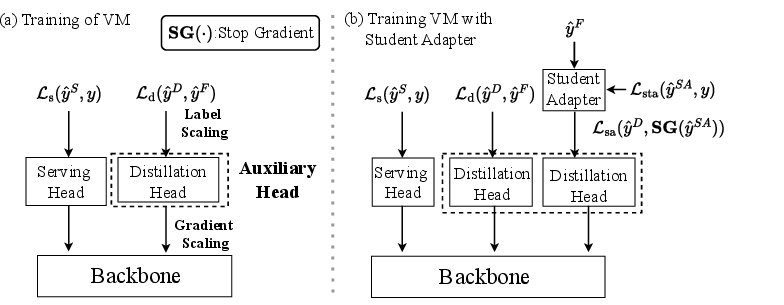
2. Auxiliary Head (AH) and Student Adapter (SA)
These components are designed to mitigate the data distribution gap between FM and VMs:
The paper evaluates ExFM using industrial-scale internal datasets and public datasets, demonstrating substantial performance gains across different models and application contexts:
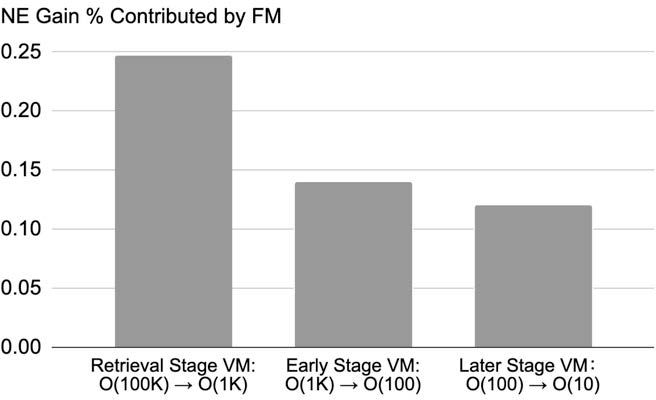
Figure 4: Inference NE gain of 1000X, 3.2T FM on cross-stage VMs, showing the impact of large-scale foundation models.
- Effectiveness across Multiple VMs: ExFM enhances VM performance across various service stages and domains, highlighting versatility in real-world applications.
Key Experimental Insights and Hyper-Parameter Impacts
The paper identifies hyperparameters like Gradient Scaling (GS), Label Scaling (LS), and Loss Weighting (LW) as critical factors impacting ExFM performance:
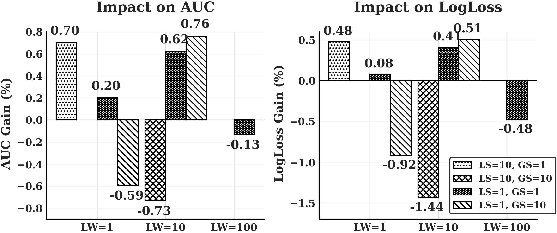
Figure 5: Joint impact of LW, LS, and GS showing their influence on VM performance.
Adjusting these parameters appropriately can optimize the transfer of FM benefits to VMs.
Conclusion
ExFM offers a robust solution to effectively deploy large foundation models in online ads recommendation systems, achieving efficient model serving and significant performance improvements. Its design principles and experimental validations provide a promising pathway for scaling AI systems in dynamic industrial environments. The framework demonstrates potential scalability in serving models of LLM magnitude without compromising industry latency constraints. Future research might explore further refinements in the integration measures and expand the application scope of ExFM in other domains.