- The paper introduces InfiniRetri, a novel training-free method that leverages intrinsic attention to retrieve information from unlimited-length contexts.
- It demonstrates robust performance on tasks like the Needle-In-a-Haystack test, achieving 100% accuracy and significant improvements on LongBench datasets.
- The method reduces computational overhead with optimized cache management and dynamic chunk processing, paving the way for scalable real-world applications.
Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing
Introduction
The paper "Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing" addresses the limitations faced by LLMs when dealing with tasks that require processing input tokens exceeding their context window size. Current methods either incur significant post-training costs, require additional tools, or exhibit limited improvements on realistic tasks. The authors introduce InfiniRetri, a novel method leveraging the intrinsic attention patterns of LLMs to enhance their capabilities for processing long contexts without additional training. This method achieves remarkable accuracy on tasks like the Needle-In-a-Haystack (NIH) test, surpassing previous state-of-the-art (SOTA) methods.
Technical Approach
The core insight of the paper is the observed correlation between attention distribution and retrieval-augmented capabilities across LLM layers. InfiniRetri exploits this alignment to accurately retrieve information from inputs of unlimited length using the models' inherent attention mechanisms rather than relying on external modules. This approach not only enhances retrieval capabilities but also reduces computational overhead and inference latency.
Observations and Methodology
The authors provide a detailed analysis of attention score distributions across various layers of LLMs. They demonstrate that layers closer to the model's output exhibit more pronounced attention patterns, aligning with question-focused retrieval capabilities. Figure 1 illustrates these attention patterns across layers, highlighting how they contribute to effective retrieval.



Figure 1: Visual representation of attention scores in Qwen2-7B-Instruct showing alignment with retrieval-augmented patterns.
The workflow of InfiniRetri involves segmenting the input text into manageable chunks and iteratively processing these segments while dynamically merging them with cached tokens. Figure 2 outlines this process, illustrating how the method maintains context and enables long-context processing.
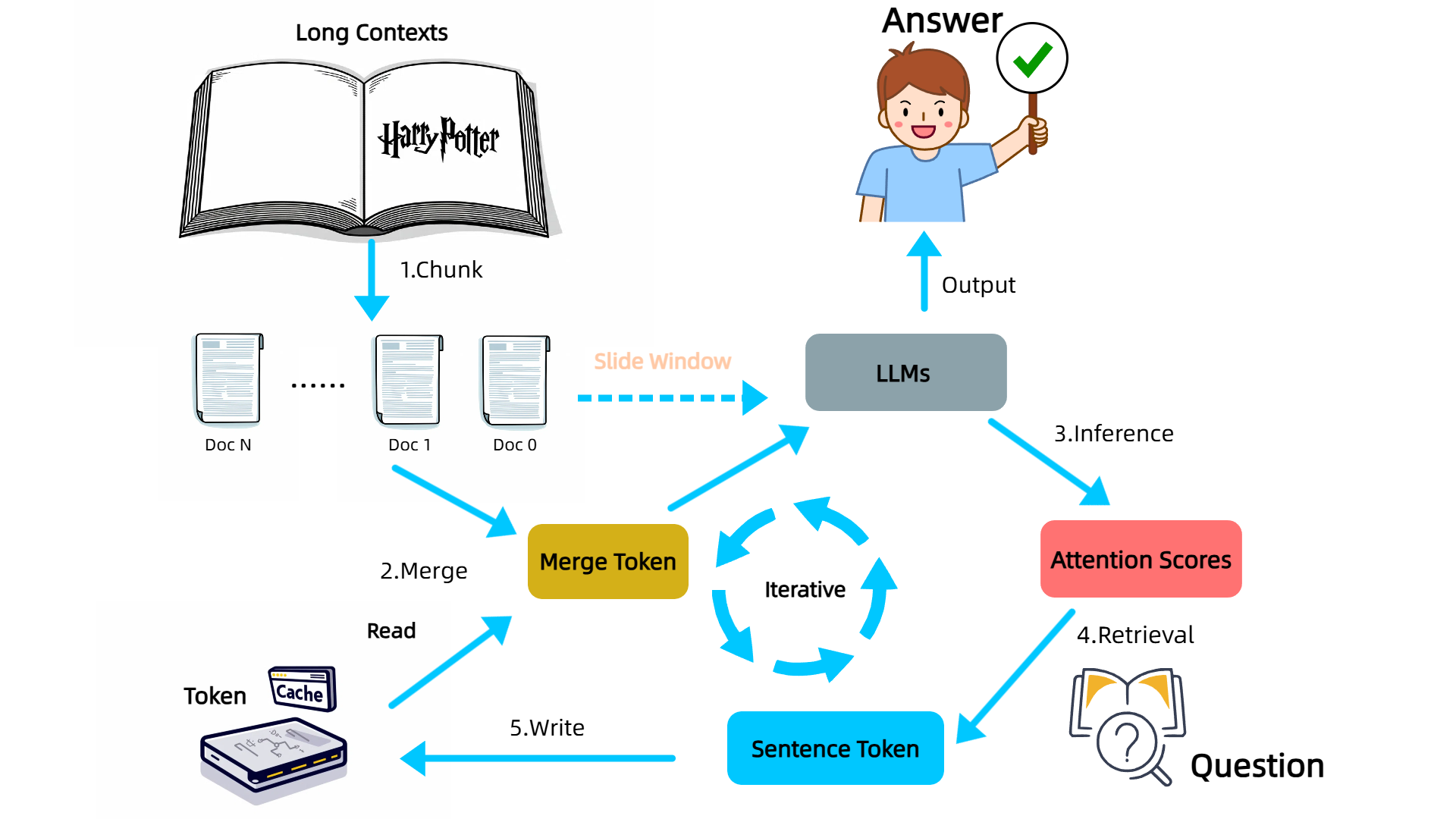
Figure 2: Entire Workflow of Our Method InfiniRetri for Enhancing Long-Context Processing in LLMs.
Key Technical Components
- Segment and Slide Window: Replicates human reading by processing text in segments, maintaining sequence order to enhance processing without finetuning.
- Retrieval in Attention: Leverages layer-wise attention patterns to efficiently locate relevant information in large contexts.
- Cache Management: Optimizes cache usage by storing token IDs rather than key-value pairs, facilitating longer context handling with lower computational cost.
Experimental Results
The evaluation of InfiniRetri demonstrates substantial improvements in long-context processing tasks. On the NIH test, the method achieves 100% accuracy with models like Mistral-7B-Instruct, processing over 1M tokens accurately, as depicted in Figure 3.
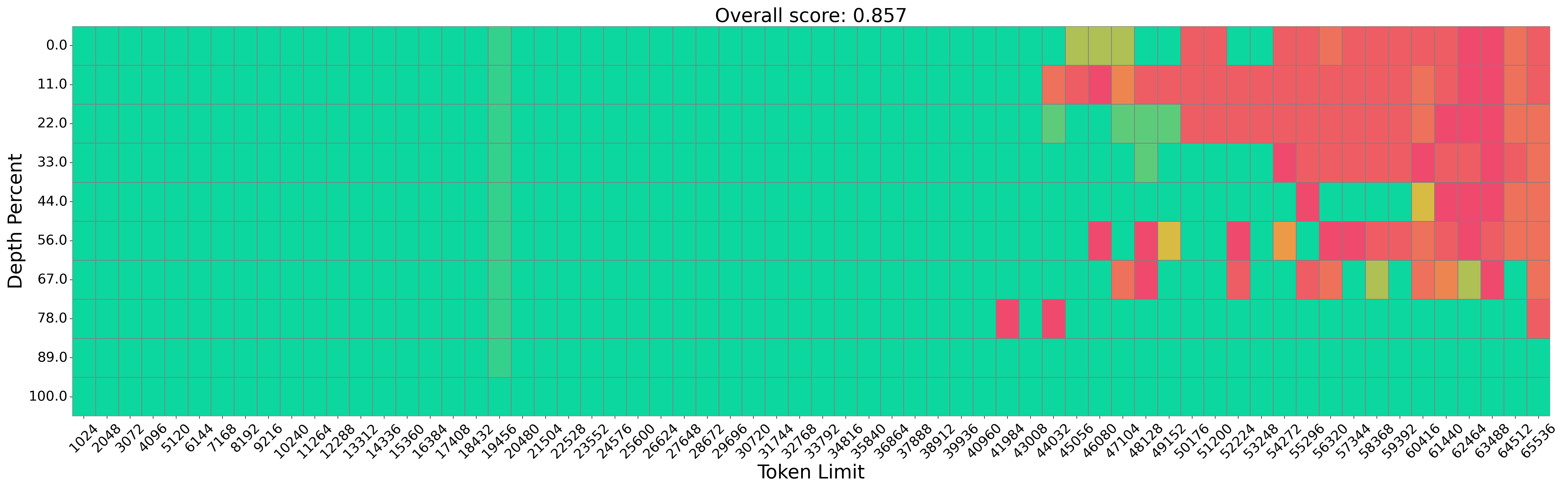
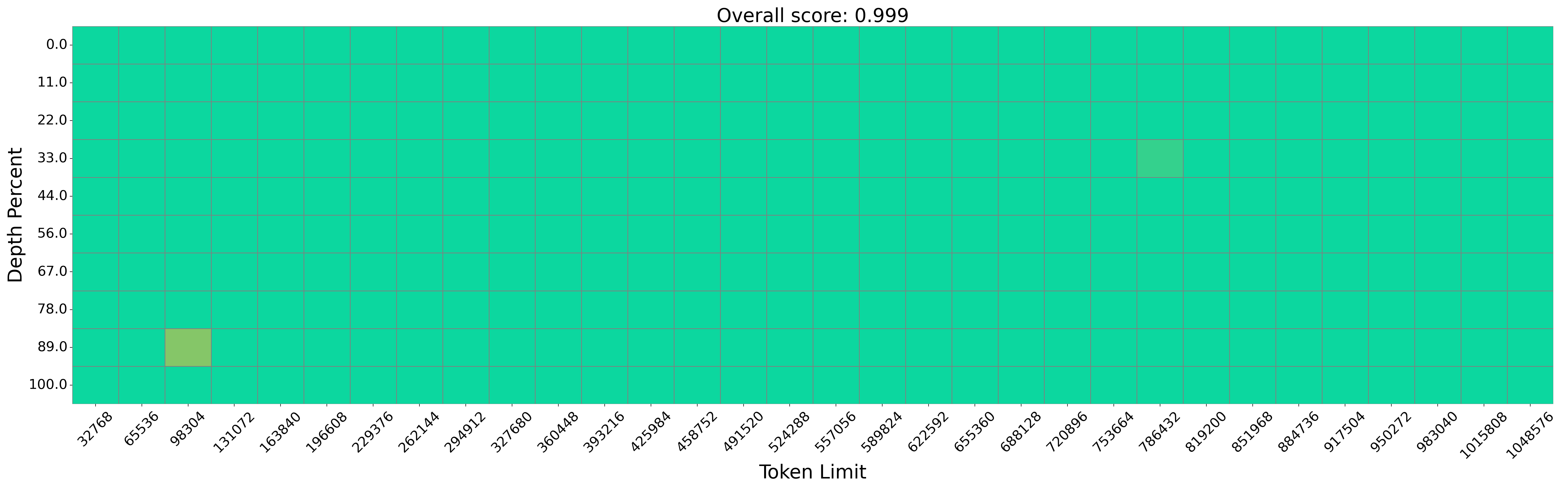
Figure 3: Performance Comparison on the Needle in a Haystack Task Using Mistral-7B-Instructv0.2.
In addition to this, InfiniRetri outperforms existing methods on LongBench datasets, particularly excelling in multi-document QA tasks like HotpotQA, showcasing up to 369.6% improvement with certain models.
Implications and Future Work
InfiniRetri presents a compelling training-free solution to LLM long-context processing, offering practical advantages in scenarios requiring extensive retrieval and question-answering capabilities. Its compatibility with existing Transformer-based architectures highlights its adaptability and potential for widespread application. This methodology not only sets new performance benchmarks but also proposes a paradigm shift from traditional context window scaling to enhancing intrinsic model capabilities.
Future research may focus on optimizing the method for summarization tasks, exploring integration with multimodal data, and expanding its applications across diverse NLP tasks, facilitating broader adoption in industry settings.
Conclusion
InfiniRetri sets a new standard in LLM long-context processing by innovatively leveraging attention mechanisms to achieve retrieval over infinite text lengths. This work offers substantial advancements in efficiency and accuracy, paving the way for enhanced applications of LLMs in complex real-world scenarios. The method's ability to function without additional training makes it a versatile tool for long-context NLP tasks, underscoring significant potential for future developments in AI and machine learning.