- The paper categorizes LLM-powered agents into recommender-, interaction-, and simulation-oriented methods to enhance personalized recommendations.
- It details a modular agent architecture—including profile, memory, planning, and action modules—that improves interaction and adaptability.
- The study evaluates benchmark datasets and proposes future research on multi-agent collaboration, interpretability, and robust security measures.
A Survey on LLM-powered Agents for Recommender Systems
The paper "A Survey on LLM-powered Agents for Recommender Systems" provides a thorough examination of the integration of LLM agents into the domain of recommender systems. This document categorizes existing approaches, elucidates the underlying agent architecture, and addresses the current state and prospective developments in this burgeoning field.
Introduction
Recommender systems have become critical in guiding users through the vast amounts of available content on digital platforms. Despite the achievements of traditional recommendation techniques, challenges remain, particularly in comprehending intricate user preferences, enabling effective interactions, and facilitating interpretable suggestions. Leveraging LLMs, with their advanced natural language capabilities and reasoning skills, represents a promising strategy for addressing these challenges. LLM agents offer numerous advantages, such as understanding complex user preferences, providing recommendations through interactive dialogues, and simulating realistic user behaviors.
Methodology
The paper identifies three key paradigms for LLM-powered agents in recommender systems: recommender-oriented, interaction-oriented, and simulation-oriented approaches.
Recommender-oriented Methods
These methods aim to enhance recommendation mechanisms using intelligent agents by capitalizing on LLMs' planning and reasoning abilities. Agents utilize user histories to generate tailored recommendations. Techniques like RecMind and MACRec exemplify the application of LLMs in direct recommendation tasks, enabling systems to transcend simple feature-based matching.

Figure 1: Illustration of Different Method Objectives. We classify existing methods into the following three categories: (1) Recommender-oriented method; (2) Interaction-oriented method; (3) Simulation-oriented method.
Interaction-oriented Methods
Focused on engaging users through dialogues, these methods enhance recommendation accuracy and interpretability. LLMs facilitate conversational interactions and provide recommendations with explanatory contexts. This approach not only tracks user interests but also delivers recommendations akin to human conversations, as seen in systems like AutoConcierge and RAH.
Simulation-oriented Methods
By employing multi-agent frameworks, these approaches simulate complex user-item interactions. They enable recommender systems to model realistic user behaviors using LLMs, as seen in Agent4Rec and AgentCF. These methods provide valuable insights into user responses, enabling fine-tuning of recommendation strategies.
Agent Architecture
The architectural foundations of LLM-powered agents are dissected into four core modules: Profile Construction, Memory Management, Strategic Planning, and Action Execution. This modular architecture facilitates the integration of LLMs into recommender systems, enabling flexible and adaptive recommendation processes.
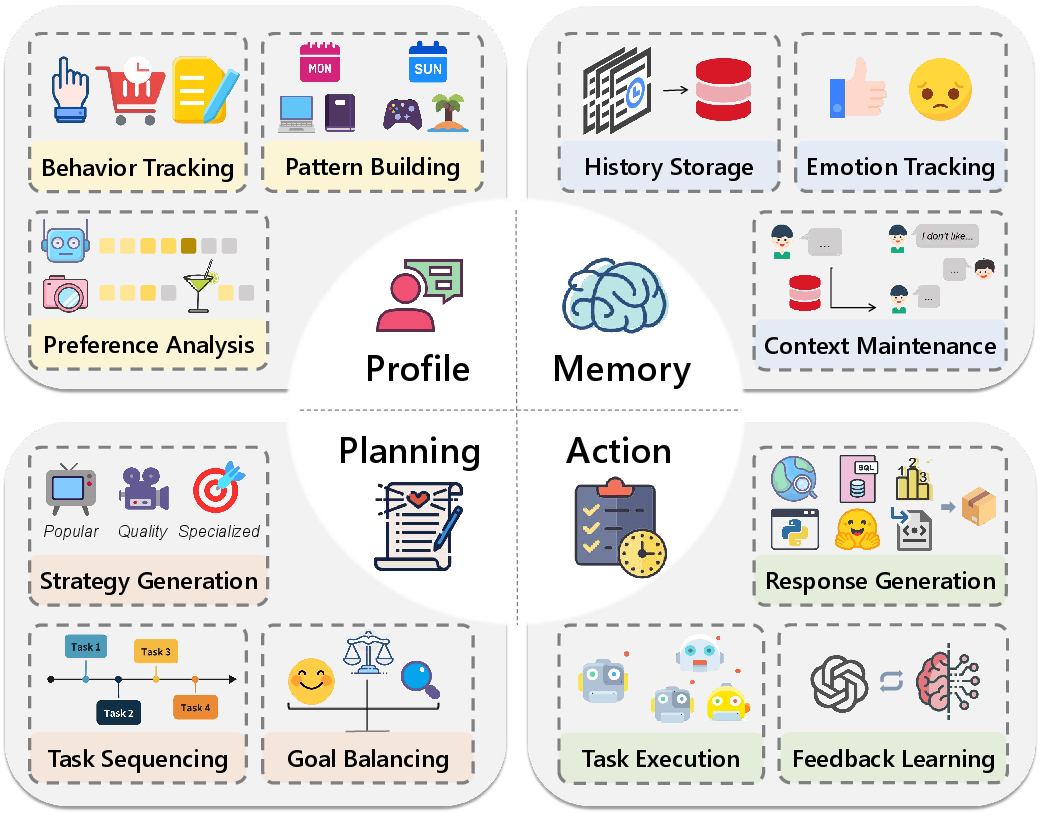
Figure 2: Illustration of Agent Components and Corresponding Functions.
Profile Module
This module develops dynamic representations of users and items, adapting to behavioral patterns and contextual signals to deliver personalized recommendations.
Memory Module
Functioning as a knowledge repository, the memory module manages historical interactions to inform and personalize future recommendations.
Planning Module
This module devises multi-step action plans to achieve long-term user engagement and satisfaction, optimizing the recommendation sequence for both user and item discovery.
Action Module
Responsible for executing recommendations based on strategic plans, this module interacts with various system components to refine and deliver appropriate recommendations.
Evaluation and Datasets
The paper provides a comprehensive analysis of benchmark datasets and evaluation criteria. Standard recommendation metrics are used alongside advanced evaluation methods to assess the efficacy of LLM-powered agents. The diversity of datasets, ranging from traditional recommendation datasets like Amazon Reviews and MovieLens to conversational datasets like ReDial, enables robust testing and validation of various approaches.
Future Directions
To further enhance the capabilities of LLM-powered agents in recommender systems, research should focus on optimizing system architecture, developing robust evaluation frameworks, and addressing security challenges. Multi-agent collaboration, interpretability, and resilient adversarial defenses are critical areas for continued exploration.
Conclusion
This survey elucidates the transformative potential of LLM-powered agents in reshaping recommender systems. By systematically categorizing approaches, analyzing architectures, and outlining future research directions, it lays the groundwork for future advancements and the broader application of LLMs in personalization and conversational AI.