- The paper demonstrates that GPT-4V outperforms other models in caption generation for scientific figures, sometimes surpassing human-written captions.
- It employs comprehensive experiments across eight arXiv domains using BLEU-4 and ROUGE metrics, complemented by detailed human evaluations.
- The study highlights ongoing challenges and calls for tailored datasets and refined methodologies to further enhance multimodal caption generation.
Introduction
The paper delineates the advancements in captioning scientific figures, primarily through multimodal models. Established through the "SciCap Challenge 2023," the research explores tools to automate caption generation across diverse academic fields. It emphasizes the comparison of human-written captions against machine-generated ones, highlighting the superiority of large multimodal models, notably GPT-4V.
Background on SciCap and Captioning Tasks
Since its inception in 2021, the SciCap dataset has aimed to enhance figure captions in scholarly articles, underpinning the development of accurate models that can generate captions reflecting the complex interplay of visual and textual information. Research in this domain repeatedly identifies that caption generation largely leans on text summarization due to the dependence on figure-mentioning paragraphs. This dependency is critical to match the generated content with the contextual necessities of scientific figures.
Models Evaluated
The research evaluates multiple models, emphasizing their performance in generating scientific figure captions. GPT-4V exhibited significant favor among professional editors compared to other models, indicating its efficiency and potential in this generative task. Models such as UniChart, and text summarization models like Pegasus, also participate in the evaluation, providing a comprehensive view of the existing technological landscape in academic captioning.
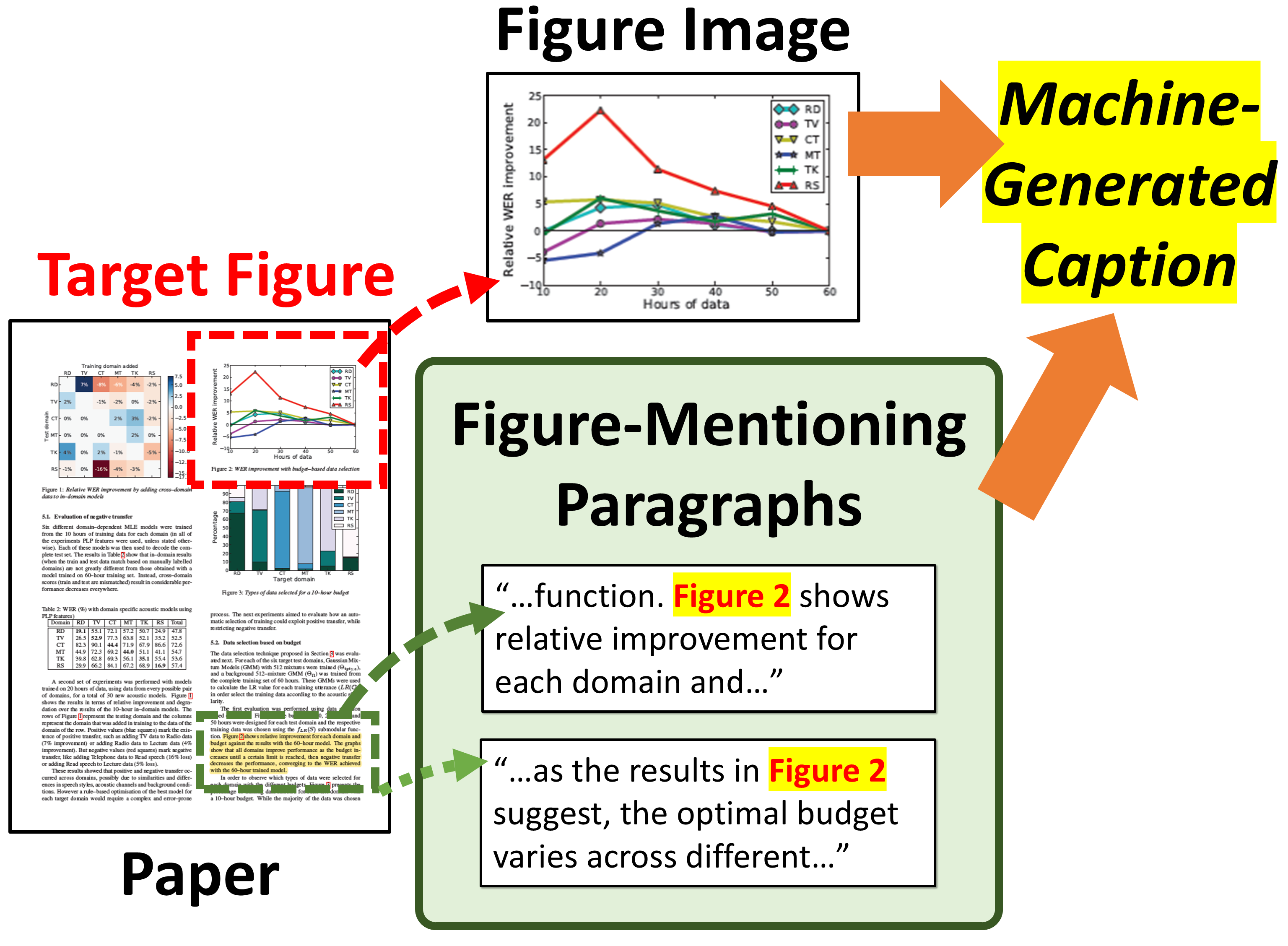
Figure 1: In SciCap Challenge, models generate captions based on the figure and the figure-mentioning paragraph.
Methodology and Experiments
The paper involves several experiments iterating over datasets and models to examine scores across eight arXiv domains, maintaining a focus on automatic and human evaluations. Automatic metrics include BLEU-4 and ROUGE scores for assessing linguistic alignment and quality. However, expert human evaluations provide depth in understanding algorithmic performance in real-world conditions.
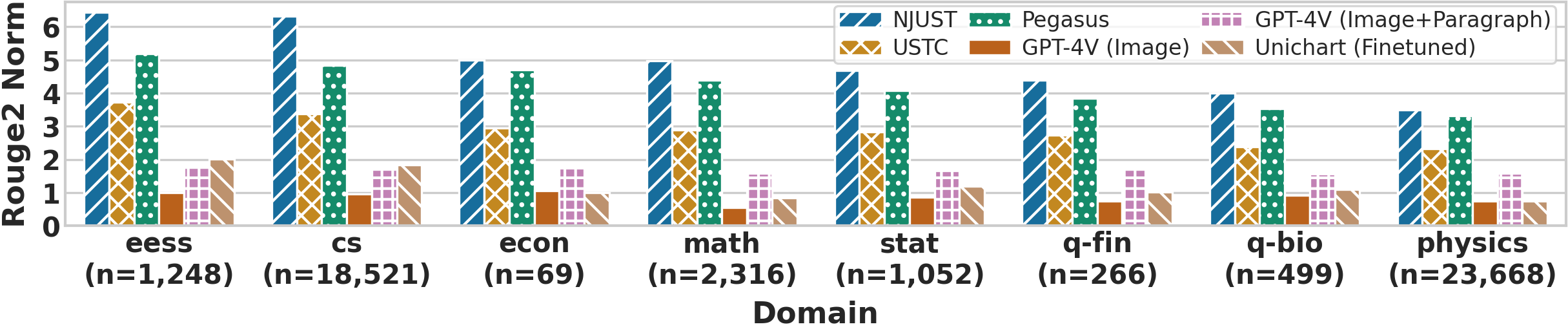
Figure 2: ROUGE-2 normalized scores of each model across eight arXiv domains, highlighting similar trends and demonstrating the generalizability of the caption generation approaches.
Human Evaluation Results
Professional editors tasked with evaluating the captions consistently favored GPT-4V's outputs over others, including human-authored captions. This preference for AI-generated content suggests improvements yet the challenge remains unsolved, given that machine-generated replacements surpass human counterparts in certain contexts.
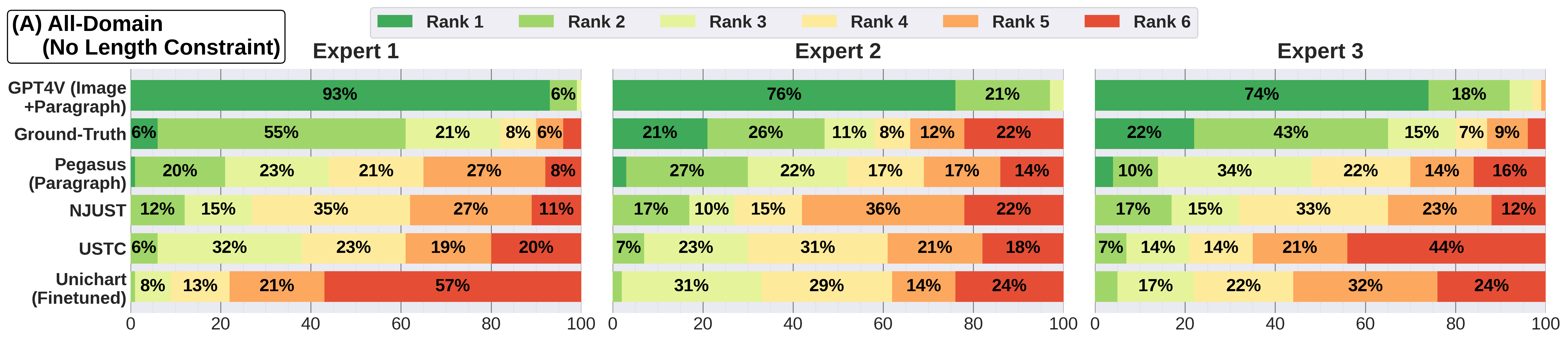


Figure 3: Rankings of generated captions by all models in Study 2 across three evaluation conditions (A, B, C) and three experts. GPT-4V (Image+Paragraph) consistently outperformed other models, including humans, across varying length constraints.
Implications and Future Directions
The paper concludes with the persistence of high-quality caption generation challenges and potential areas for enhancement. While the solution by GPT-4V demonstrates significant progress, the necessity for improved evaluation methods and personalized content generation remains. Enhanced datasets and methodologies could further refine multimodal models' applicability across academic publishing disciplines.

Figure 4: Two examples where experts favored GPT-4V's captions for providing sufficient details and highlighting key takeaway messages, two key factors identified in our comment analysis.
Conclusion
In acknowledging GPT-4V's strength, this research underscores the inherent limitations of current caption generation methodologies. It calls for additional refinement, both theoretically and practically, advocating for tailored models adaptable to various domains beyond the scope of arXiv.

