- The paper presents Preference Optimization as a novel method leveraging human feedback to enhance the alignment and fairness of visual contrastive models.
- It employs a Markov Decision Process to combine preference and regularization losses, improving resistance against typographic attacks while maintaining accuracy.
- Experimental results show improved performance over benchmarks like PAINT, demonstrating significant reduction in gender bias and typographic vulnerabilities.
Aligning Visual Contrastive Learning Models via Preference Optimization
Contrastive learning has become a dominant method for training models that understand semantic similarities between data points by aligning their representations in a shared embedding space. Despite notable successes, these models often suffer from biases and vulnerabilities inherent to the training data. The paper "Aligning Visual Contrastive learning models via Preference Optimization" addresses these issues by introducing Preference Optimization (PO) as an alignment technique, aiming to improve performance and fairness in contrastive models like CLIP.
Preference Optimization Framework
Methodology
Preference Optimization takes advantage of human feedback and preference modeling to align model behavior with desired outcomes. The framework applies principles from Reinforcement Learning from Human Feedback (RLHF) and adapt them to contrastive learning. The primary goals are:
- Enhancing robustness against typographic attacks.
- Mitigating biases, particularly related to gender understanding.
The paper proposes a Markov Decision Process (MDP) formulation for contrastive learning tasks, treating them as retrieval systems where the alignment task focuses on selecting preferred outputs from a set. The policy optimization utilizes techniques such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO) to adjust model behavior effectively.
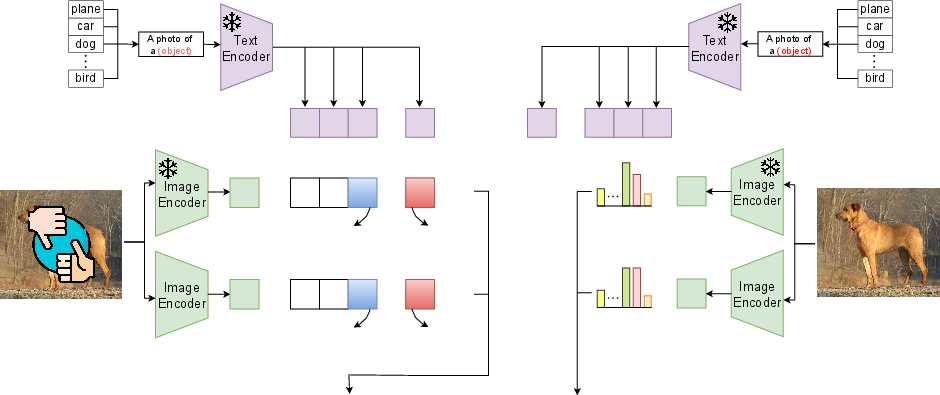
Figure 1: Overview of our proposed framework, on the left side, we calculate the preference optimization loss Lpref using the preference dataset, and the regulatory loss Lreg using the clean regularization dataset.
Dataset and Training
Two types of datasets are used: a Preference Dataset containing preferred and dispreferred pairs to guide the model towards desired behaviors, and a Regularization Dataset consisting of clean samples to maintain accuracy on non-adversarial data. The overall loss function combines preference optimization with a regularization term to ensure model proximity to its original state, preventing excessive divergence.
Experimental Results
Typographic Attack Robustness
The PO framework was tested on typographic attack datasets using CLIP as the base model. Results show significant improvement over existing models such as PAINT and Defense-prefix. The approach effectively blocks adversarial influences without compromising performance on clean data.
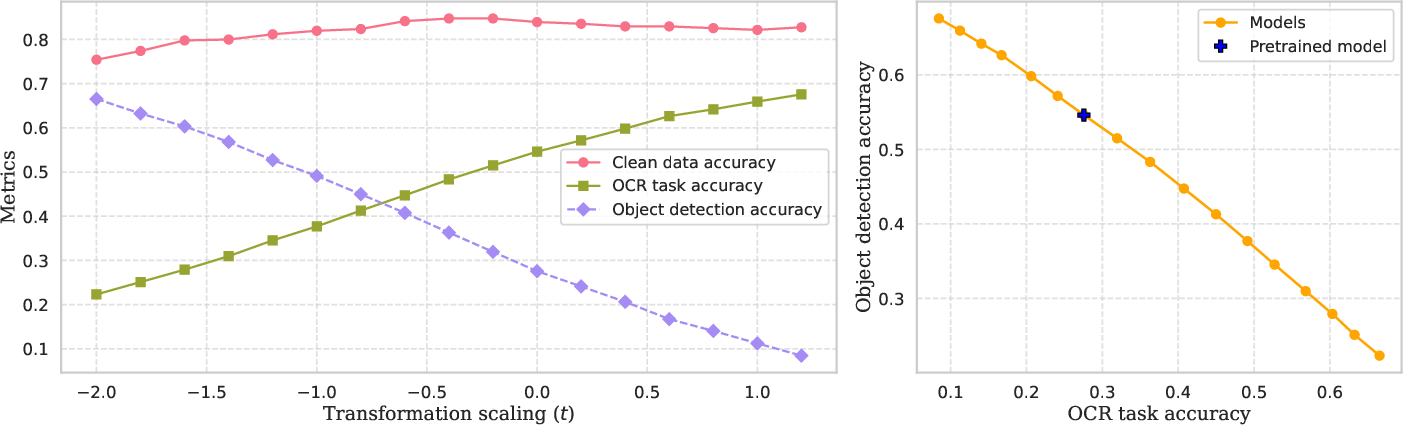
Figure 2: (Left) Accuracy on typographic samples and percentage of typographic label predictions versus transformation scaling factor t. As t increases, the model favors object labels over typographic labels while maintaining accuracy.
Mitigating Gender Bias
The framework achieved high control over gender-specific predictions, illustrating its ability to disentangle gender biases effectively. Adjustments are managed using transformation scaling, demonstrating a capacity to reverse or neutralize biases in model decision-making.
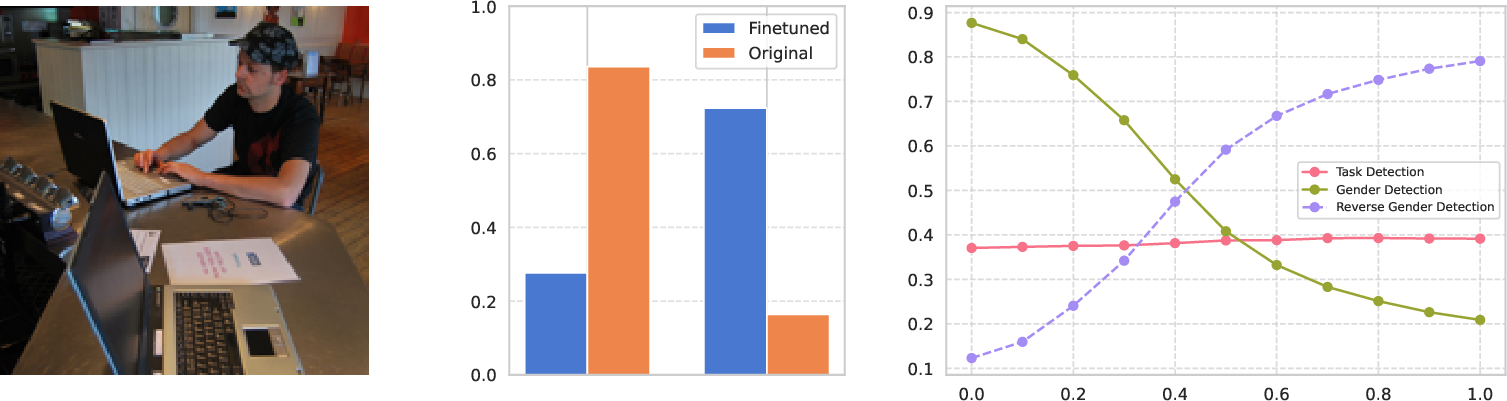
Figure 3: (Left) Image input. (Center) Comparison of model predictions before and after applying our gender-flipping method, showing changes in the predicted gender probabilities.
Conclusions
This research presents Preference Optimization as a promising technique for improving contrastive learning models where biases and adversarial vulnerabilities are concerns. The practical application of PO to tasks such as typographic attacks and gender bias illustrates its versatility and efficacy. Future research could explore extending these alignment methods to other data modalities, seeking further fairness and robustness improvements.
Overall, the paper's approach demonstrates how preference-based optimization can align models with human values while retaining previously learned knowledge and capabilities, laying groundwork for more resilient and socially aware AI systems.

