- The paper demonstrates that an RL framework with a fine-tuned attacker LLM improves ASR by up to 57.2% on LLaMA2-7B-chat and 50.3% on Claude 2.
- The methodology leverages Proximal Policy Optimization and vector reward signals to generate effective adversarial suffixes without requiring white-box access.
- The approach scales across open and closed-source models, achieving high ASR scores such as 94.97% on GPT-3.5 and 99.4% on Gemma-2B-it, validating its robustness.
LLM Stinger: Jailbreaking LLMs using RL Fine-Tuned LLMs
Introduction
The paper "LLM Stinger: Jailbreaking LLMs using RL fine-tuned LLMs" (2411.08862) introduces LLM Stinger, a robust framework designed to generate adversarial suffixes that effectively jailbreak safety-trained LLMs. It addresses the growing challenge of bypassing the safety mechanisms embedded in open-source and closed-source LLMs. Unlike traditional jailbreak and adversarial attack methods that rely heavily on prompt engineering or white-box access to models, LLM Stinger leverages an automated reinforcement learning loop for adapting and optimizing adversarial suffixes, providing significant advantages in terms of scalability and attack success rate (ASR).
Overview of LLM Stinger
LLM Stinger exploits reinforcement learning (RL) to derive customizable adversarial suffixes intended for jailbreaks. This involves a finely-tuned attacker LLM operating within an RL framework capable of generating attack vectors from existing harmful suffixes within the HarmBench benchmark. The paper details using these attack vectors on LLMs that have undergone rigorous safety training, such as those implemented within Claude and GPT models. Notably, LLM Stinger demonstrates remarkable improvements, offering a +57.2% ASR improvement on LLaMA2-7B-chat and a +50.3% ASR increase on Claude 2. It further achieves notably high ASRs of 94.97% on GPT-3.5 and 99.4% on Gemma-2B-it, proving the robustness and adaptability of LLM Stinger across various LLM architectures.
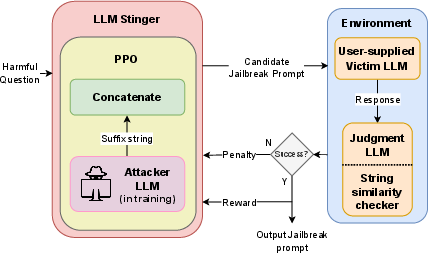
Figure 1: Architecture Diagram of LLM Stinger.
Implementation Methodology
The implementation details emphasize the innovative use of a transformer-based LLM within an RL loop, highlighting an attacker LLM using Proximal Policy Optimization (PPO) for iterative refinement and suffix generation. The paper describes a setup where the attacker LLM incorporates reward signals based on feedback from binary judgment and string similarity assessments. These signals assist in generating suffixes that maximize the probability of bypassing model defenses within black-box settings. Notably, this eliminates the need for direct access to model internals—making LLM Stinger applicable across both open and closed-source models.
Additionally, the paper discusses the customization of the TRL library to handle vector reward signals for precise feedback implementation, guiding the suffix refinement process. The computational framework employs powerful hardware equipped with NVIDIA V100 GPUs, indicating the necessity for high-performance processing in conducting large-scale testing and training iterations.
Experimental Setup
The paper's experimental setup utilizes HarmBench—a standardized framework for evaluating adversarial attack methodologies on LLMs. This setup enables comprehensive testing against multiple victim models, ensuring LLM Stinger's robustness and adaptability. The authors employ open-source models like LLaMA-2 and Vicuna as well as closed-source models like GPT and Claude APIs. The results, analyzed and tabulated extensively, demonstrate LLM Stinger's consistent performance in achieving high ASR scores across diverse LLM environments.
Results and Discussions
Results from various attack scenarios highlight the effectiveness of LLM Stinger in surpassing existing adversarial attack benchmarks. By focusing on ASR as a critical metric, the study illustrates the tangible benefits of using a fine-tuned attacker LLM within an RL framework. Significant ASR improvements on LLaMA-2-chat and Claude models underscore the framework's capacity to adaptively exploit model vulnerabilities despite extensive safety training. Furthermore, LLM Stinger's competency in both open and closed-source contexts makes it a versatile tool for adversarial testing.
Conclusions
The LLM Stinger framework represents a potent advancement in the domain of adversarial attacks on large, safety-trained LLMs. By implementing an RL-guided heuristic search mechanism with judgment model feedback and string similarity evaluation, LLM Stinger efficiently prunes search spaces and fosters high-potential exploration avenues. The ability to discover efficient, novel attack suffixes illustrates the practical strength and applicability of this methodology. The paper suggests future expansions to multi-modal LLMs and additional token-level attack methods, promising further developmental pathways in adversarial attack strategies.
In summary, LLM Stinger enhances adversarial testing capabilities, allowing for unprecedented scalability and adaptability across complex LLM infrastructure, paving the way for future research and development in automated jailbreak methodologies.

