- The paper shows that distributed representations derived using dictionary learning and NMF enhance interpretability over local features.
- Psychophysics experiments involving 560 participants confirm higher accuracy and comprehension with distributed features across network layers.
- Findings indicate that overcoming superposition with sparse distributed representations is key to improving model confidence and decision-making.
Local vs Distributed Representations: What Is the Right Basis for Interpretability?
Introduction
The paper introduces a pertinent investigation into the link between local and distributed representations in deep neural networks (DNNs) and their interpretability. The authors challenge the prevailing reliance on local representations, where individual neurons are typically studied for interpretability. They emphasize the limitations imposed by superposition in local representations—where neurons respond to multiple features—and advocate for the use of distributed representations using dictionary learning methods (Figure 1).

Figure 1: A conceptual depiction of local versus distributed representations in neural networks, highlighting the challenge of superposition in local representations and the vector-based simplification in distributed representations.
Methodology
Sparse Distributed Representations
For generating sparsely distributed representations, the paper utilizes CRAFT, a dictionary learning method. The process involves applying Non-negative Matrix Factorization (NMF) to map activation spaces of neural networks into more interpretable bases. This decomposition results in vectors driven by singular, interpretable features.
Psychophysics Experiments
The core empirical analysis comprises three psychophysics experiments, involving a cohort of 560 participants, evaluating how intuitive and comprehensible features derived from distributed representations are compared to local representations.
- Experiment I (Figure 2): Evaluated interpretability with trials illustrating the maximally and minimally activating stimuli for both local and distributed representations.

Figure 2: Illustration of a trial setup in Experiment I, demonstrating the task for participants to discern the query image consistent with reference images.
- Experiment II (Figure 3): Introduced semantic controls to minimize semantic bias in reference images, aiming to discern visual coherence purely based on feature interpretation rather than semantic categories.

Figure 3: Example of semantic control in trials to eradicate bias, hence focusing on visual pattern recognition rather than semantic inference.
- Experiment III (Figure 4 and Figure 5): Integrated feature visualization with natural images to explore whether visualizations enhance interpretability—a hypothesis with divided evidence from preceding studies.

Figure 4: Mixed trials in Experiment III integrating feature visualizations with natural images.
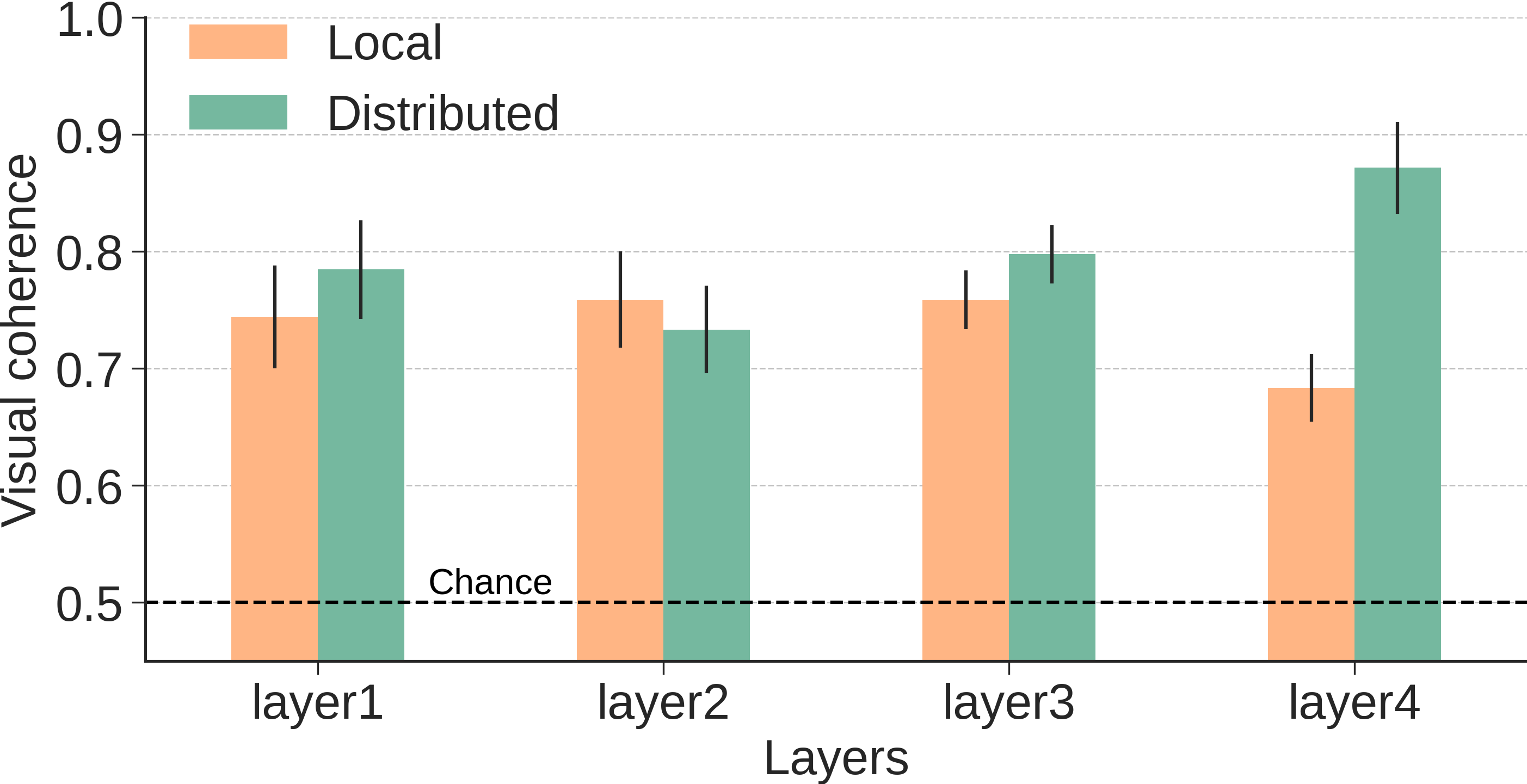
Figure 5: Results from Experiment III highlighting performance discrepancies across network layers between local and distributed conditions.
Results
A pivotal takeaway from the experimental results is that distributed representations invariably led to higher interpretability scores. Participants consistently exhibited better performance in tasks involving distributed features, with accuracy peaking at deeper network layers. The authors assert that these vectors not only correspond closely to perceivable visual features but are indispensable to model decisions, evidenced by a noticeable drop in model confidence upon their omission (Figure 6).
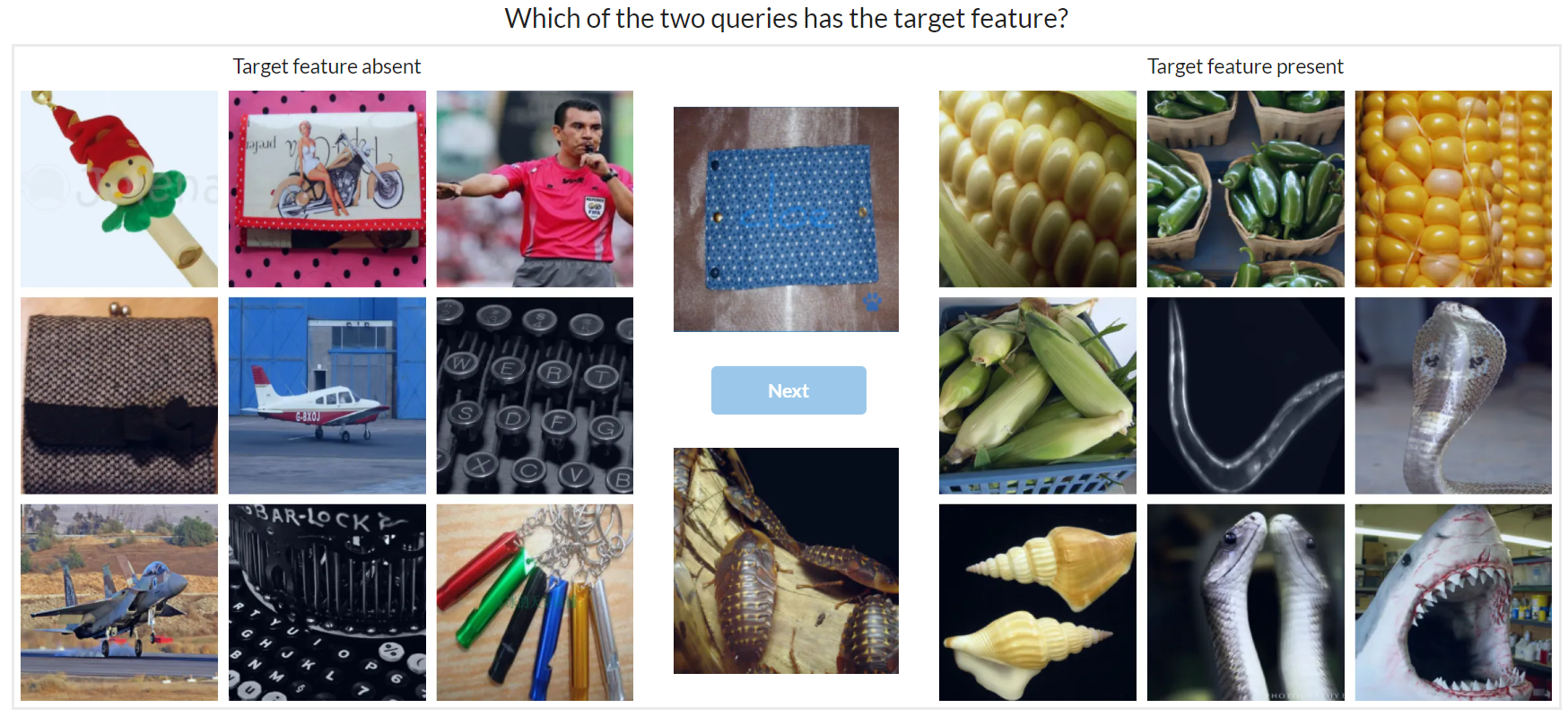
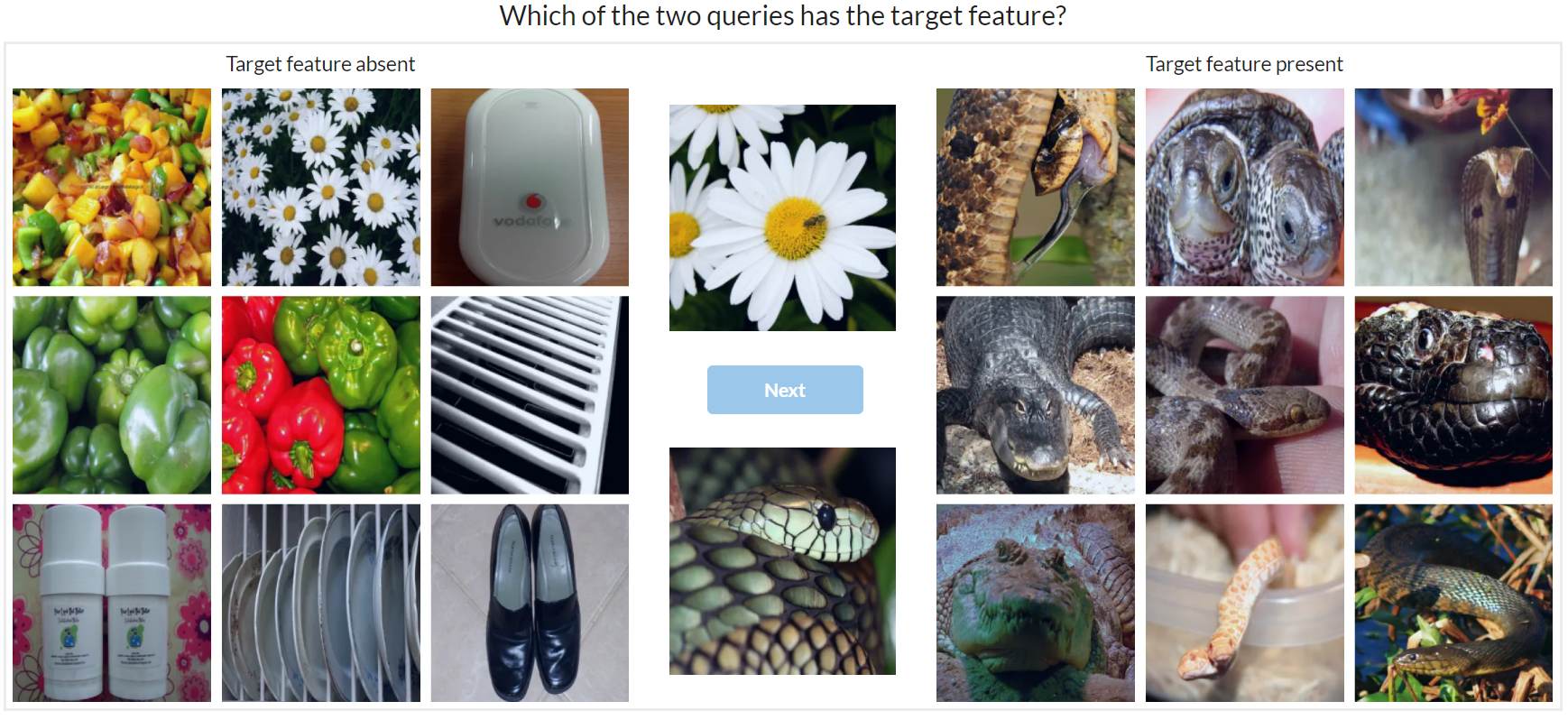
Figure 6: Demonstrates the superior feature importance of distributed representations over local ones across various network layers.
Conclusion
This inquiry confirms the potential of sparsely distributed representations as a superior basis for interpretability in computer vision models. Distributed features ease human interpretation and align better with the model’s significant decision-making processes, particularly in complex and deep network structures. While existing local methods falter due to the superposition problem, distributed methods promote clearer, more cogent feature mappings. Future research could further explore scalable methods for synthesizing these representations in other neural architectures, potentially fostering universal interpretability frameworks applicable across AI systems.

