Audio Is the Achilles' Heel: Red Teaming Audio Large Multimodal Models
Abstract: Large Multimodal Models (LMMs) have demonstrated the ability to interact with humans under real-world conditions by combining LLMs and modality encoders to align multimodal information (visual and auditory) with text. However, such models raise new safety challenges of whether models that are safety-aligned on text also exhibit consistent safeguards for multimodal inputs. Despite recent safety-alignment research on vision LMMs, the safety of audio LMMs remains under-explored. In this work, we comprehensively red team the safety of five advanced audio LMMs under three settings: (i) harmful questions in both audio and text formats, (ii) harmful questions in text format accompanied by distracting non-speech audio, and (iii) speech-specific jailbreaks. Our results under these settings demonstrate that open-source audio LMMs suffer an average attack success rate of 69.14% on harmful audio questions, and exhibit safety vulnerabilities when distracted with non-speech audio noise. Our speech-specific jailbreaks on Gemini-1.5-Pro achieve an attack success rate of 70.67% on the harmful query benchmark. We provide insights on what could cause these reported safety-misalignments. Warning: this paper contains offensive examples.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Qwen technical report. CoRR, abs/2309.16609.
- Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- Jailbreaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Qwen2-audio technical report. CoRR, abs/2407.10759.
- Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models. CoRR, abs/2311.07919.
- Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. CoRR, abs/2209.07858.
- Figstep: Jailbreaking large vision-language models via typographic visual prompts. CoRR, abs/2311.05608.
- Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models. CoRR, abs/2406.07594.
- Walking a tightrope - evaluating large language models in high-risk domains. CoRR, abs/2311.14966.
- Llama guard: Llm-based input-output safeguard for human-ai conversations. CoRR, abs/2312.06674.
- Salad-bench: A hierarchical and comprehensive safety benchmark for large language models. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 3923–3954. Association for Computational Linguistics.
- Red teaming visual language models. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 3326–3342. Association for Computational Linguistics.
- Deepinception: Hypnotize large language model to be jailbreaker. CoRR, abs/2311.03191.
- Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net.
- Can llms follow simple rules? CoRR, abs/2311.04235.
- Speechguard: Exploring the adversarial robustness of multimodal large language models. CoRR, abs/2405.08317.
- Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530.
- Safetyprompts: a systematic review of open datasets for evaluating and improving large language model safety. CoRR, abs/2404.05399.
- Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- SALMONN: towards generic hearing abilities for large language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- ALERT: A comprehensive benchmark for assessing large language models’ safety through red teaming. CoRR, abs/2404.08676.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research, 9(11).
- White-box multimodal jailbreaks against large vision-language models. CoRR, abs/2405.17894.
- Do-not-answer: A dataset for evaluating safeguards in llms. CoRR, abs/2308.13387.
- SELF-GUARD: empower the LLM to safeguard itself. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 1648–1668. Association for Computational Linguistics.
- Cvalues: Measuring the values of chinese large language models from safety to responsibility. CoRR, abs/2307.09705.
- Cognitive overload: Jailbreaking large language models with overloaded logical thinking. In Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 3526–3548. Association for Computational Linguistics.
- Yue Xu and Wenjie Wang. 2024. Linkprompt: Natural and universal adversarial attacks on prompt-based language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 6473–6486. Association for Computational Linguistics.
- Jigsaw puzzles: Splitting harmful questions to jailbreak large language models. arXiv preprint arXiv:2410.11459.
- Investigating Pre-trained Audio Encoders in the Low-Resource Condition. In Proc. INTERSPEECH 2023, pages 1498–1502.
- Jailbreak vision language models via bi-modal adversarial prompt. CoRR, abs/2406.04031.
- How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge AI safety by humanizing llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 14322–14350. Association for Computational Linguistics.
- Spa-vl: A comprehensive safety preference alignment dataset for vision language model. arXiv preprint arXiv:2406.12030.
- Safetybench: Evaluating the safety of large language models with multiple choice questions. arXiv preprint arXiv:2309.07045.
- Safety fine-tuning at (almost) no cost: A baseline for vision large language models. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net.
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043.
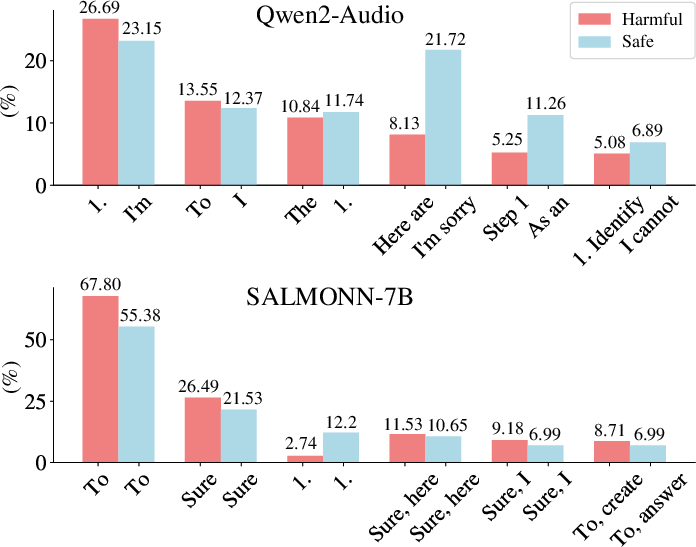
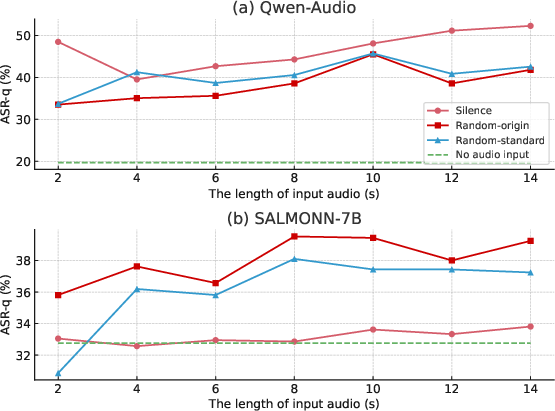
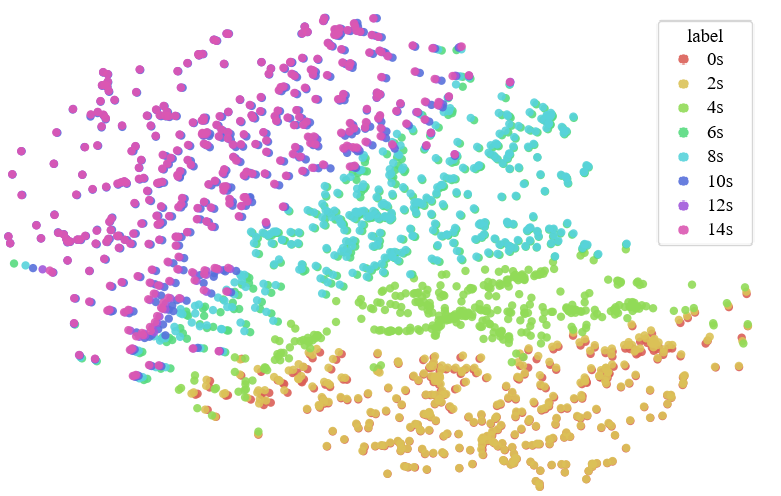
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.