Prompt Baking
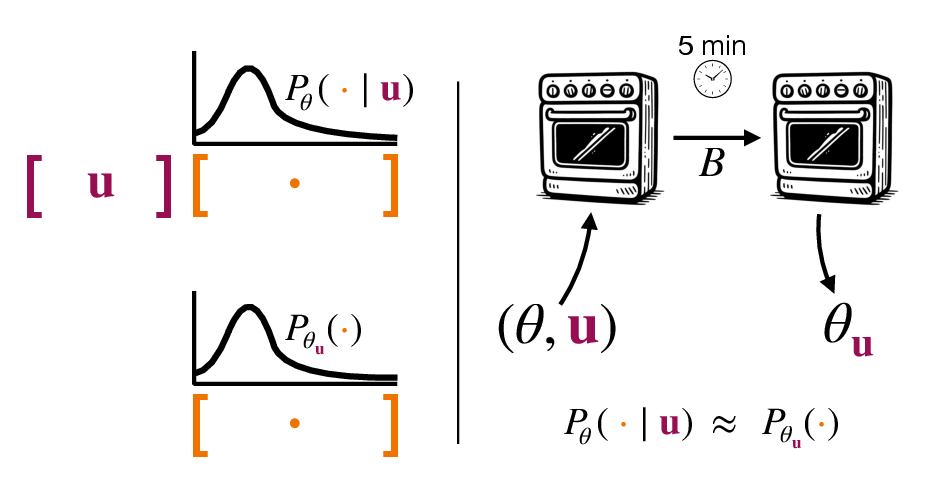
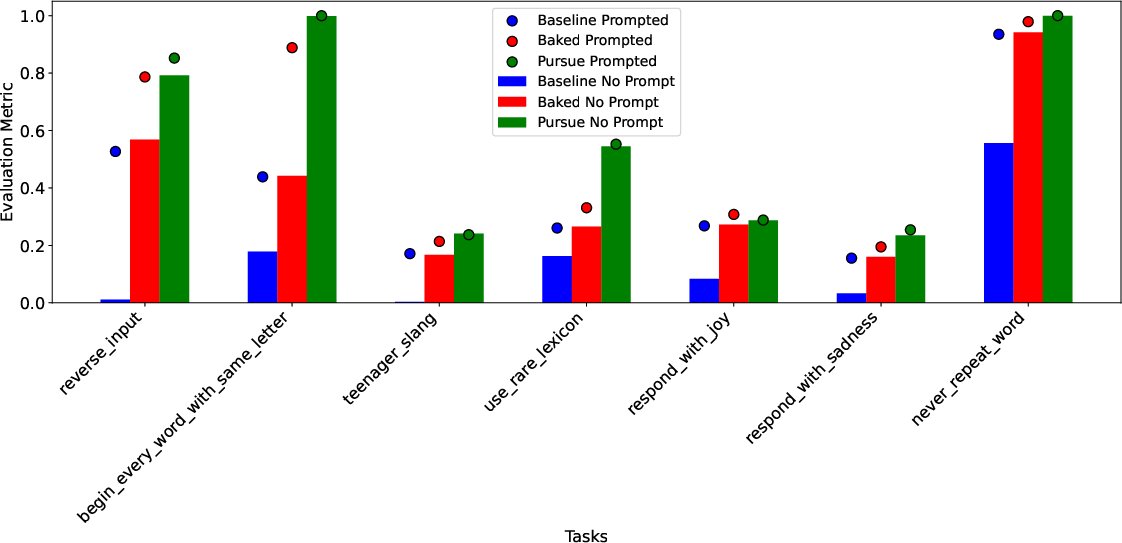
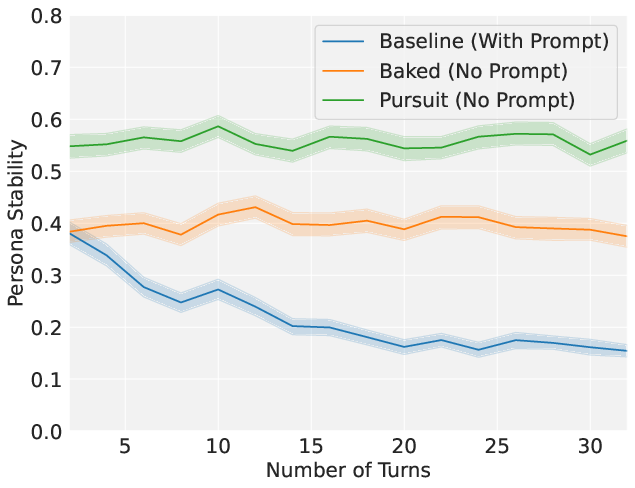
Abstract: Two primary ways to change LLM behavior are prompting and weight updates (e.g., fine-tuning). Prompting LLMs is simple and effective, specifying the desired changes explicitly in natural language, whereas weight updates provide more expressive and permanent behavior changes, specified implicitly via training on large datasets. We present a technique for "baking" prompts into the weights of an LLM. Prompt Baking converts a prompt $u$ and initial weights $\theta$ to a new set of weights $\theta_u$ such that new "baked" LLM behaves like the original prompted LLM. Mathematically, we minimize the KL divergence between $P_\theta(\cdot | u)$ and $P_{\theta_u}(\cdot)$, where $P$ is the LLM's probability distribution over token sequences. Across all our experiments, we find prompts can be readily baked into weight updates. Baking chain-of-thought prompts improves zero-shot performance on GSM8K, ASDiv, MBPP, ARC-Easy, ARC-Challenge, and CommonsenseQA benchmarks. Baking news headlines directly updates an LLM's knowledge. And baking instructions & personas alleviates "prompt forgetting" over long sequences. Furthermore, stopping baking early creates "half-baked" models, continuously scaling prompt strength. Baked models retain their sensitivity to further prompting and baking, including re-prompting with the baked-in prompt. Surprisingly, the re-prompted models yield further performance gains in instruction following, as well as math reasoning and coding benchmarks. Taking re-prompting and re-baking to the limit yields a form of iterative self-improvement we call Prompt Pursuit, and preliminary results on instruction following exhibit dramatic performance gains. Finally, we discuss implications for AI safety, continuous model updating, enhancing real-time learning capabilities in LLM-based agents, and generating more stable AI personas.
- Online continual learning with maximally interfered retrieval, 2019. URL https://arxiv.org/abs/1908.04742.
- Concrete problems in ai safety, 2016. URL https://arxiv.org/abs/1606.06565.
- Anthropic. Golden gate claude, 05 2024. URL https://www.anthropic.com/golden-gate-claude. Accessed on August 30, 2024.
- Gradient-free neural network training via synaptic-level reinforcement learning. arXiv preprint arXiv:2105.14383, 2021.
- What’s the magic word? a control theory of llm prompting, 2024. URL https://arxiv.org/abs/2310.04444.
- Language models are few-shot learners, 2020. URL https://arxiv.org/abs/2005.14165.
- How to tell deep neural networks what we know. CoRR, abs/2107.10295, 2021. URL https://arxiv.org/abs/2107.10295.
- The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
- The Feynman Lectures on Physics, Vol. III: Quantum Mechanics. Addison-Wesley, Reading, Massachusetts, 1965. Chapter on Operators.
- Robert M. French. Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 3(4):128–135, 1999. ISSN 1364-6613. doi: https://doi.org/10.1016/S1364-6613(99)01294-2. URL https://www.sciencedirect.com/science/article/pii/S1364661399012942.
- Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
- Large language models can self-improve, 2022. URL https://arxiv.org/abs/2210.11610.
- Llmlingua: Compressing prompts for accelerated inference of large language models, 2023. URL https://arxiv.org/abs/2310.05736.
- Daniel Kahneman. Thinking, fast and slow. Farrar, Straus and Giroux, 2011.
- Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521–3526, March 2017. ISSN 1091-6490. doi: 10.1073/pnas.1611835114. URL http://dx.doi.org/10.1073/pnas.1611835114.
- Learning to solve the credit assignment problem. arXiv preprint arXiv:1906.00889, 2019.
- Scalable agent alignment via reward modeling: a research direction, 2018. URL https://arxiv.org/abs/1811.07871.
- Measuring and controlling instruction (in)stability in language model dialogs, 2024. URL https://arxiv.org/abs/2402.10962.
- An empirical study of catastrophic forgetting in large language models during continual fine-tuning, 2024. URL https://arxiv.org/abs/2308.08747.
- Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation, 24:109–165, 1989. ISSN 0079-7421. doi: https://doi.org/10.1016/S0079-7421(08)60536-8. URL https://www.sciencedirect.com/science/article/pii/S0079742108605368.
- Bennet B Murdock Jr. The serial position effect of free recall. Journal of experimental psychology, 64(5):482, 1962.
- Quantum cognition. Annual review of psychology, 73(1):749–778, 2022.
- Engineering flexible machine learning systems by traversing functionally-invariant paths, 2023. URL https://arxiv.org/abs/2205.00334.
- Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
- Progress & compress: A scalable framework for continual learning, 2018. URL https://arxiv.org/abs/1805.06370.
- Distilling reasoning capabilities into smaller language models, 2023. URL https://arxiv.org/abs/2212.00193.
- Reward is enough. Artificial Intelligence, 299:103535, 2021.
- Judgment under uncertainty: Heuristics and biases: Biases in judgments reveal some heuristics of thinking under uncertainty. science, 185(4157):1124–1131, 1974.
- A comprehensive survey of continual learning: Theory, method and application, 2024a. URL https://arxiv.org/abs/2302.00487.
- Large language model enhanced knowledge representation learning: A survey, 2024b. URL https://arxiv.org/abs/2407.00936.
- Self-consistency improves chain of thought reasoning in language models, 2023a. URL https://arxiv.org/abs/2203.11171.
- Self-instruct: Aligning language models with self-generated instructions, 2023b. URL https://arxiv.org/abs/2212.10560.
- Chain-of-thought prompting elicits reasoning in large language models, 2023.
- A survey on knowledge distillation of large language models, 2024. URL https://arxiv.org/abs/2402.13116.
- Continual learning through synaptic intelligence. In International Conference on Machine Learning, pages 3987–3995. PMLR, 2017.
- A comprehensive study of knowledge editing for large language models, 2024. URL https://arxiv.org/abs/2401.01286.
- Representation engineering: A top-down approach to ai transparency, 2023. URL https://arxiv.org/abs/2310.01405.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.