- The paper introduces MMEvalPro, a novel benchmark that integrates perception and knowledge questions to reveal true multimodal capabilities.
- It employs a Genuine Accuracy metric by testing models across three components, exposing significant performance differences between LMMs and LLMs.
- The rigorous annotation pipeline, involving multiple experts, enhances data quality and reliability for advancing multimodal AI research.
MMEvalPro: Calibrating Multimodal Benchmarks Towards Trustworthy and Efficient Evaluation
Introduction
The evaluation of Large Multimodal Models (LMMs) has been increasingly scrutinized due to their shortcomings in genuinely reflecting the abilities of these systems. While traditional benchmarks often employ multiple-choice questions (MCQs) with visual components, they do not adequately distinguish between models with and without visual understanding capabilities. The paper introduces MMEvalPro, a novel benchmark designed to reveal the true capabilities of LMMs by incorporating a more rigorous evaluation pipeline that includes perception and knowledge questions.
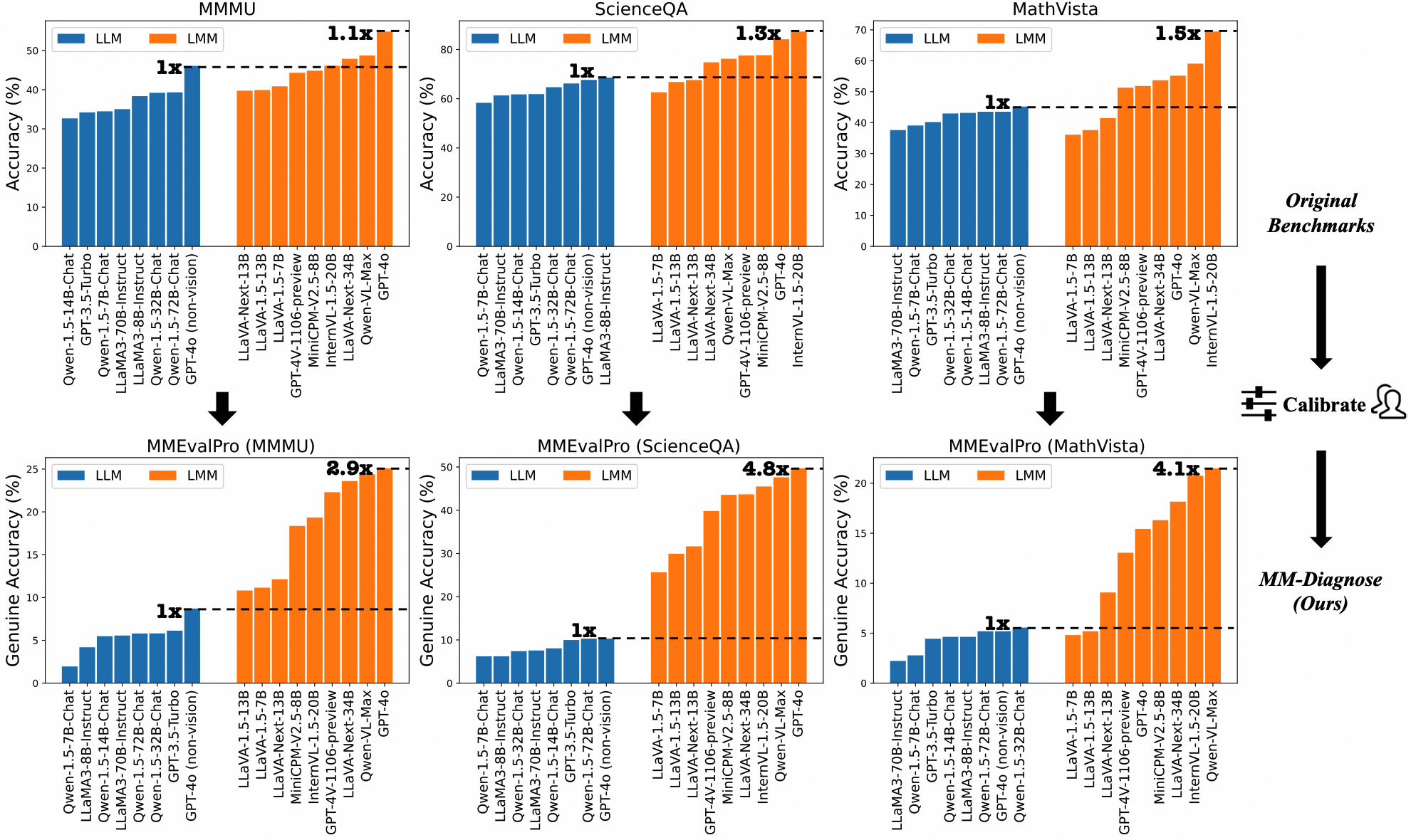
Figure 1: LLMs and LMMs' performance comparison between original multimodal benchmarks and MMEvalPro. Performance gap between LLM and LMM is much clearer in MMEvalPro.
Probing the Credibility of Multimodal Benchmarks
Existing benchmarks are critiqued for allowing models lacking visual understanding to perform comparably to those that include it. The initial experiments reveal that the gap between LLMs and LMMs on standard benchmarks is not as significant as anticipated, indicating these evaluations do not fully capture the models' multimodal capabilities. Critical issues are data leakage and the ability for LLMs to guess answers without processing visual content.
The "Answer Consistency Test" illustrates that models often provide correct answers without true comprehension by failing on subsequent perception and knowledge checks that should conceptually precede or support the MCQ answer. The result is a prevalent Type-I error, where benchmarks inaccurately gauge genuine understanding.

Figure 2: Examples from different splits in the MMEvalPro dataset.
MMEvalPro: A Comprehensive Benchmark
MMEvalPro addresses these deficiencies by implementing a trio of evaluations for each MCQ: an original question, a perception question about the visual data, and a knowledge anchor question requiring subject matter understanding. This trilogy aims to gauge the model's comprehensive capabilities. Genuine Accuracy (GA) is introduced as a primary metric, requiring correct answers across all triplet components.
A meticulously designed annotation pipeline ensures data quality, involving multiple annotators for redundancy and validation by domain experts. The pipeline ensures questions are created to necessitate both the visual and knowledge components critical for genuine comprehension.
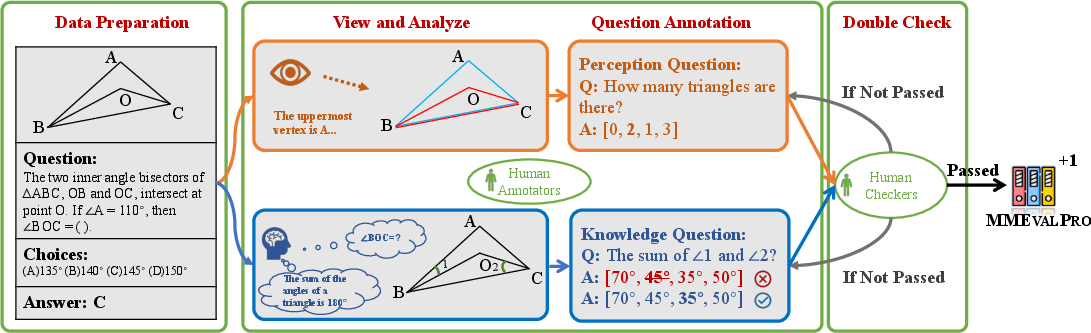
Figure 3: Annotation pipeline for MMEvalPro.
Experimental Evaluation
In experiments executed with MMEvalPro, a significant drop is observed in the performance of LLMs and some LMMs when compared to existing benchmarks. This drop highlights the challenge posed by the GA requirement and underscores the more rigorous evaluation MMEvalPro provides. Notably, the best LMMs still fall behind human baselines, demonstrating the benchmark's rigor.
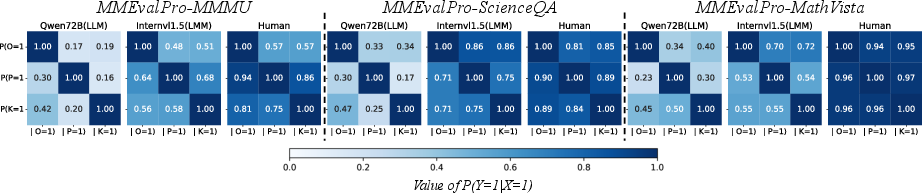
Figure 4: Heatmaps of conditional accuracy of MMEvalPro.
Fine-grained Analysis
Further analysis with metrics such as Consistency Gap (CG), Perception Accuracy (PA), and Knowledge Accuracy (KA) illustrates the underlying issues causing performance disparities. LMMs exhibit higher PA over KA, expected due to their visual processing capabilities, contrasting with LLMs' lack of such features.
Case studies further delineate these inconsistencies, with complex visual and conceptual reasoning tasks highlighting gaps in models' reasoning processes when images are misinterpreted or irrelevant.
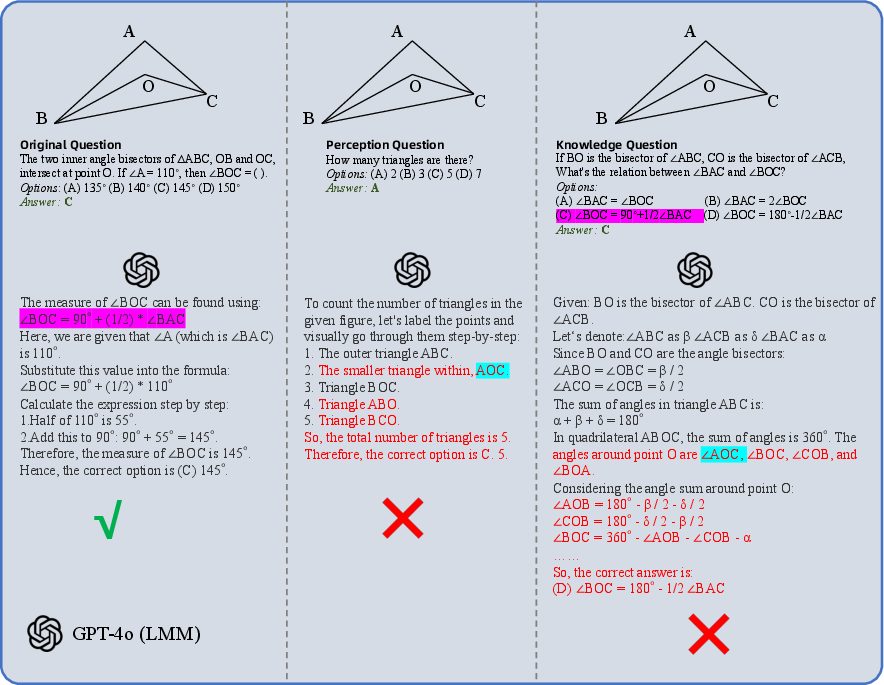
Figure 5: Case study on the answer in-consistency problem of LMMs.
Conclusion
MMEvalPro offers a robust and nuanced framework for evaluating multimodal models, exposing the limitations of current systems while providing a path to improve their assessment. Its adoption could lead to more accurate benchmarks that reflect true model capabilities across modalities, fostering further advancements in multimodal AI research. As models evolve, benchmarks like MMEvalPro will continue to serve a critical role in assessing technological progress and guiding development priorities.

