- The paper introduces a universal checkpointing system for reconfigurable parallelism in large-scale DNN training using atomic checkpoints.
- It employs a pattern-based reconfiguration pipeline and optimizations such as nested parallel reconfiguration, redundancy-bypassing loading, and lazy invocation.
- Evaluation shows that UCP supports diverse parallelism strategies efficiently with minimal training overhead and enhanced fault recovery.
Universal Checkpointing for Reconfigurable Parallelism in Large-Scale DNN Training
Introduction
The study explores Universal Checkpointing (UCP), a system designed to address the challenges of reconfigurable parallelism in large-scale deep neural network (DNN) training. When training large DNNs, resizing and reconfiguring parallelism strategies without losing training efficiency or accuracy is crucial. Existing checkpointing mechanisms are tightly coupled with specific parallelism strategies, limiting their adaptability. The UCP aims to resolve this limitation by introducing a flexible checkpointing system supporting a broad range of parallelism strategies.
Atomic Checkpoints
UCP departs from conventional tightly-coupled checkpointing systems by leveraging atomic checkpoints, an abstraction that decouples checkpoint data from specific parallelism strategies or hardware configurations. This decoupling allows UCP to offer a flexible and universal format for saving model states. An atomic checkpoint represents a consolidated view of a model's parameters, allowing seamless transitioning between different form factors in which DNN models might be configured or trained.
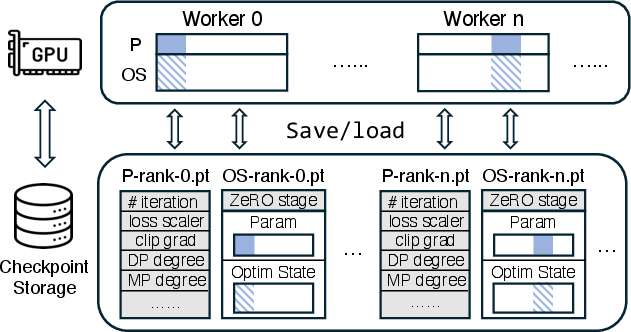
Figure 1: Existing distributed checkpoints are highly coupled to specific model parallelism strategy. Each worker in ZeRO-3 saves its own unique sharded model parameters (P) and optimizer states (OS). Reconfiguring ZeRO-3 requires altering each sharded parameter and optimizer states.
Pattern-Based Reconfiguration
The pattern-based reconfiguration pipeline constitutes the core of UCP's strategy to achieve seamless parallelism reconfiguration. By recognizing pre-defined tensor patterns in model parameters—such as replicates, sharded, unique, and more—UCP utilizes pattern-based transformation operations, which allow the system to automatically adapt parameter storage and retrieval processes to suit the target parallelism strategy.
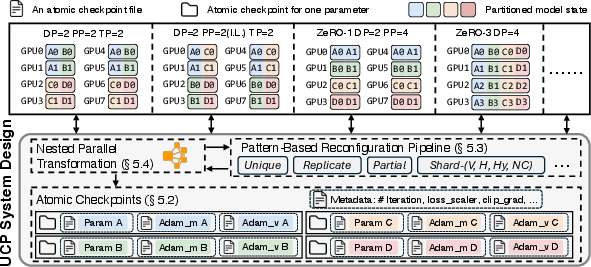
Figure 2: Overview of UCP system design. UCP enables flexible and efficient reconfiguration from any Source parallelism strategy, e.g., Psrc (ZeRO-1 + PP) = (DP=2, PP=4) to any Target parallelism strategy, e.g., Ptgt (3D-Parallel) = (DP=2, TP=2, PP=2), via {atomic checkpoints}, {pattern-based reconfiguration pipeline}, and efficient optimizations such as {nested parallel reconfiguration}.
Efficient Reconfiguration
Efficiency in UCP is achieved through three core optimizations:
- Nested Parallel Reconfiguration: UCP employs a MapReduce framework to handle reconfiguration, leveraging multiple nodes and processors to distribute the data transformation workload efficiently.
- Redundancy-Bypassing Loading: By eliminating redundant loading in DP groups and utilizing fast GPU interconnects, UCP optimizes the loading phase and minimizes I/O pressure.
- Lazy Reconfiguration Invocation: The system optimizes performance by triggering reconfiguration only when necessary, thus preserving training speeds and preventing excessive computing overhead.
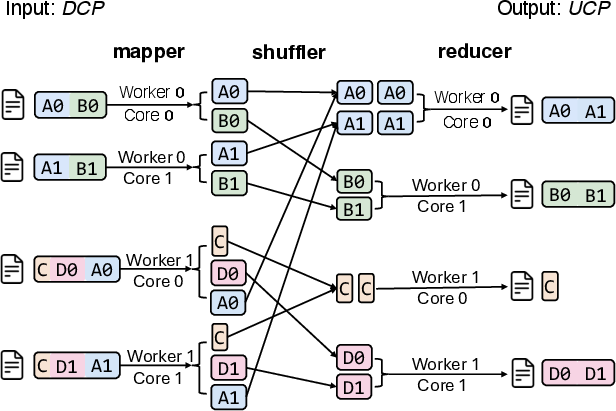
Figure 3: Illustration of the nested parallel reconfiguration process of UCP. UCP leverages a MapReduce-based approach to utilize the aggregated compute and bandwidth of multi-node multi-processors to convert distributed checkpoints into atomic checkpoints in parallel. Meanwhile, it performs careful load balancing to avoid the straggle problem.
Evaluation and Impact
The evaluation of UCP demonstrates its capability to support a broader set of reconfigurable parallelism strategies, achieving higher flexibility compared to existing systems like DCP and MCP. UCP proves effective across various model sizes, scales efficiently with the size of the networks, and maintains a minimal overhead on the total training time. This system enables efficient fault recovery and dynamic resource utilization in large-scale distributed training environments, improving throughput in potentially unstable hardware scenarios.
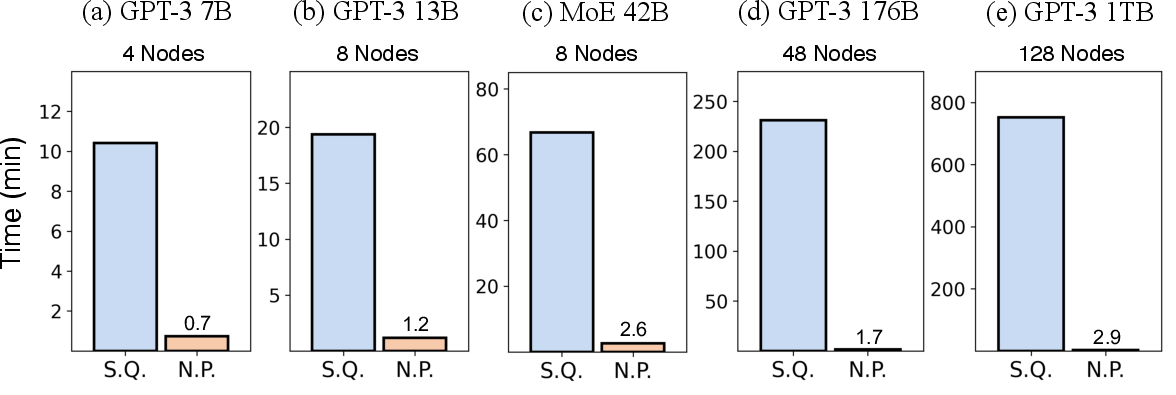
Figure 4: Time cost for converting distributed checkpoints to UCP atomic checkpoints with sequential (S.Q.) and nested parallel (N.P) approach across different model sizes.
Conclusion
UCP represents a significant advancement in distributed DNN training by enabling flexible and efficient reconfiguration through atomic checkpoints and a pattern-based reconfiguration framework. It broadens the adaptability of training strategies across different hardware configurations without compromising system efficiency or model accuracy. The development of UCP marks a step forward in managing the complexity and dynamism of large-scale AI training systems.

