- The paper introduces SSAM, leveraging the Mamba architecture as a selective state space model for self-supervised audio representation learning.
- It employs masked log-mel spectrogram patches and linear-time convolutions to efficiently overcome the quadratic complexity of Transformer-based models.
- Experiments on AudioSet demonstrate significant gains in accuracy and data efficiency across diverse downstream audio tasks.
Audio Mamba: Selective State Spaces for Self-Supervised Audio Representations
Introduction
This paper introduces Self-Supervised Audio Mamba (SSAM), a selective structured state space model (SSM) for learning general-purpose audio representations from masked spectrogram patches. The work is motivated by the limitations of Transformer-based models, particularly their quadratic complexity with respect to sequence length, and leverages recent advances in SSMs—specifically, the Mamba architecture—to address these issues in the audio domain. The authors empirically demonstrate that SSAM, pretrained on AudioSet, outperforms comparable self-supervised audio spectrogram transformer (SSAST) baselines across ten diverse downstream audio recognition tasks, with significant improvements in aggregate performance, data efficiency, and adaptability to varying sequence lengths and model sizes.
Methodology
Selective State Space Models and Mamba
SSAM is built upon the Mamba architecture, a context-aware SSM that generalizes classical state space models by conditioning parameters on the input sequence, enabling selective and efficient long-range modeling. Unlike traditional SSMs, which are time-invariant, Mamba introduces input-dependent parameterization, allowing for greater expressivity and adaptability.
The core SSM equations are discretized and implemented as global convolutions over the input sequence, with the Mamba variant introducing context-aware selection mechanisms. This enables linear-time sequence modeling, in contrast to the quadratic complexity of attention-based Transformers.
Self-Supervised Learning with Masked Spectrogram Modeling
The SSAM framework operates on log-mel spectrograms, which are divided into non-overlapping patches. These patches are linearly projected, augmented with sinusoidal positional embeddings, and prepended with a class token. A random 50% of patches are masked and replaced with a learnable mask token, following an unstructured masking strategy shown to be effective for audio.
The masked sequence is processed by a stack of Mamba blocks, each with an expansion factor of 3 and increased internal dimensions to match the parameter count of standard Transformer blocks. The encoded representations are then passed through a single-layer MLP to reconstruct the original patches, with mean-squared error as the pretraining objective. During downstream evaluation, the reconstruction head is discarded, and the latent representations are used for classification.
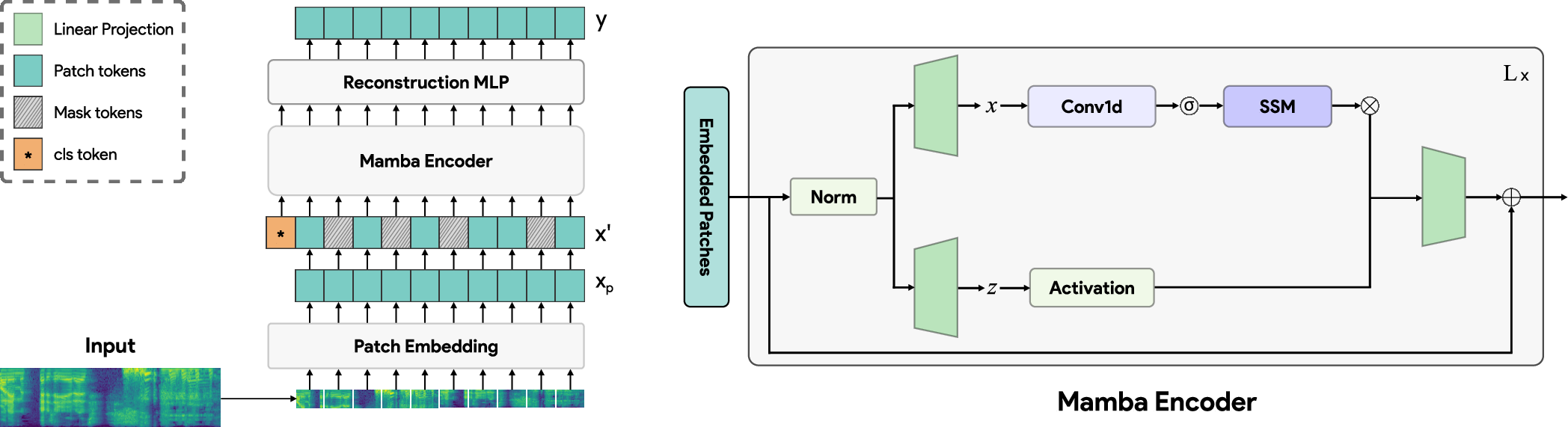
Figure 1: An overview of the proposed SSAM approach (left), and the constituent Mamba blocks (right).
Experimental Setup
Pretraining and Evaluation
SSAM models are pretrained on AudioSet, a large-scale dataset comprising over 2 million 10-second audio clips spanning 527 classes. Downstream evaluation is conducted on a subset of the HEAR benchmark, covering ten diverse audio recognition tasks, including environmental sound classification, speech command recognition, and music analysis.
All models are trained for 100 epochs with a batch size of 1024, using AdamW with linear warmup and cosine decay. No data augmentation is applied. For downstream tasks, fixed-size feature vectors are extracted from 2-second audio chunks, averaged over time, and classified using a single-layer MLP.
Model Configurations
Three SSAM configurations are evaluated: Tiny (dm=192), Small (dm=384), and Base (dm=768), each with 12 Mamba blocks. Patch sizes and sequence lengths are varied to assess adaptability. Directly comparable SSAST models are trained for fair comparison.
Results
SSAM models consistently outperform SSAST baselines across all evaluated tasks and configurations. The SSAM-Base model achieves an aggregate normalized score of 89.7, exceeding the SSAST-Base and official SSAST models by over 20 points, despite having fewer parameters. Notably, even the SSAM-Tiny and SSAM-Small models surpass the official SSAST baseline, highlighting the efficiency of the Mamba-based approach.
The only models outperforming SSAM are Multi-Window Masked Autoencoders (MWMAEs), which are not causal and thus not directly comparable in certain applications. The authors note that integrating Mamba into an MAE framework is non-trivial due to architectural differences.
Ablation Studies
Patch Size and Sequence Length
SSAM demonstrates superior adaptability to varying patch sizes and sequence lengths. As the number of patches increases (i.e., higher time/frequency resolution), the performance gap between SSAM and SSAST widens, with SSAM maintaining robust performance even at high resolutions.
Data Efficiency
SSAM exhibits improved data efficiency, with the performance gap over SSAST increasing as more pretraining data is used. This suggests that SSAM scales more effectively with data, making it suitable for scenarios with limited labeled resources.
Bidirectional Modeling
Ablations with bidirectional SSMs (Vim blocks) reveal that unidirectional Mamba blocks outperform their bidirectional counterparts for audio spectrogram modeling. This is attributed to the inherently unidirectional temporal structure of audio, in contrast to the spatial structure of images where bidirectionality is beneficial.
Implementation Considerations
Computational Efficiency
The linear-time complexity of Mamba blocks enables efficient processing of long audio sequences, making SSAM suitable for large-scale and real-time applications. The reduced parameter count relative to Transformers further enhances scalability.
Model Deployment
SSAM's causal nature and adaptability to varying input resolutions facilitate deployment in streaming and low-latency settings. The absence of data augmentation in pretraining simplifies integration into existing pipelines.
Limitations
While SSAM outperforms Transformer-based baselines, it does not surpass non-causal MAE-based models in aggregate performance. Integrating Mamba with MAE frameworks remains an open challenge due to architectural incompatibilities.
Theoretical and Practical Implications
The results establish selective state space models as a viable alternative to attention-based architectures for self-supervised audio representation learning. The demonstrated data efficiency, adaptability, and computational advantages suggest broad applicability in audio understanding, especially in resource-constrained or real-time environments.
The findings also highlight the importance of architectural alignment with data modality—unidirectional modeling is preferable for audio, whereas bidirectionality benefits vision tasks. This underscores the need for modality-specific architectural choices in general-purpose representation learning.
Future Directions
Potential avenues for future research include:
- Integrating Mamba-based SSMs with MAE frameworks to combine the benefits of causality and reconstruction-based pretraining.
- Extending SSAM to other modalities, such as multimodal audio-visual representation learning.
- Exploring lightweight variants for on-device and edge deployment.
- Investigating the impact of data augmentation and alternative masking strategies on representation quality.
Conclusion
SSAM demonstrates that selective state space models, specifically the Mamba architecture, are highly effective for self-supervised audio representation learning. The approach achieves substantial improvements over Transformer-based baselines in both performance and efficiency, adapts well to varying data and model scales, and is well-suited for practical deployment in diverse audio recognition tasks. The work provides a strong foundation for further exploration of SSMs in audio and other sequential domains.