Multimodal Fusion on Low-quality Data: A Comprehensive Survey
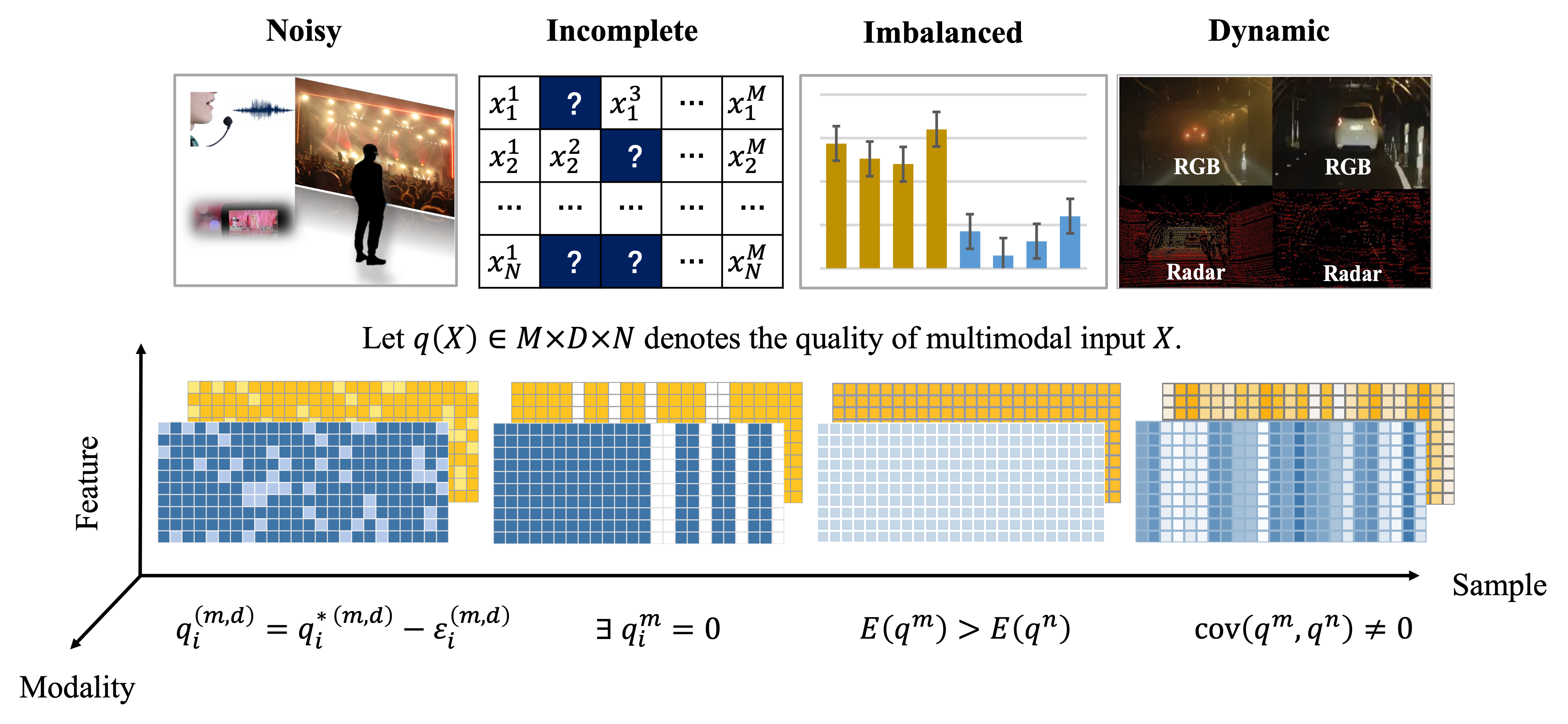
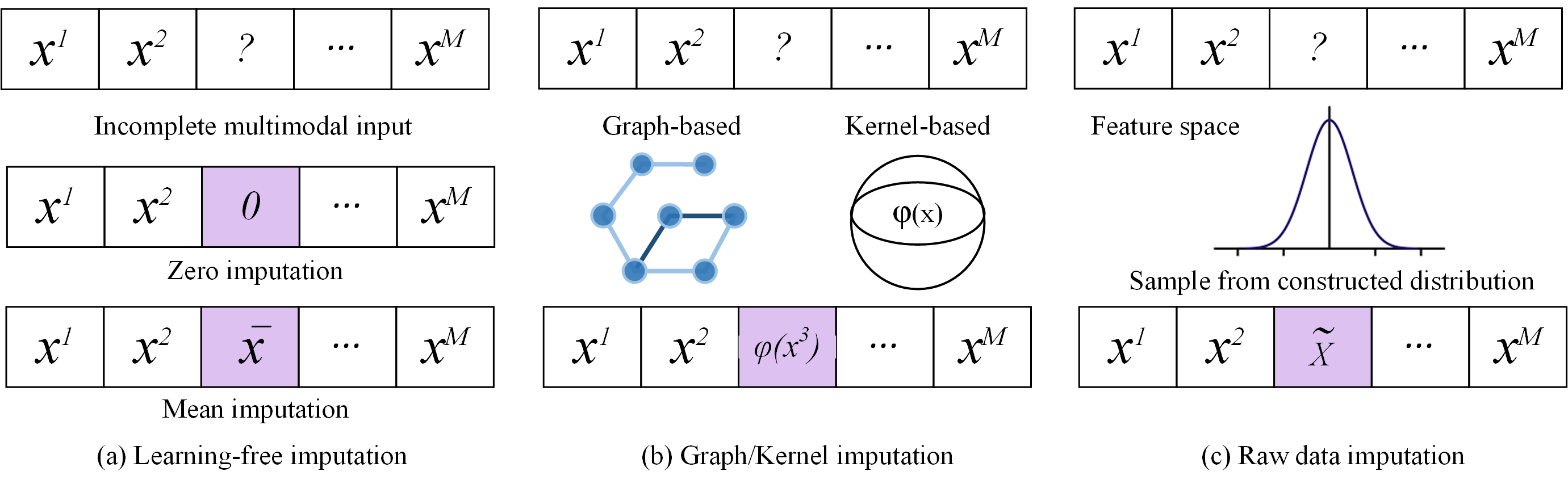
Abstract: Multimodal fusion focuses on integrating information from multiple modalities with the goal of more accurate prediction, which has achieved remarkable progress in a wide range of scenarios, including autonomous driving and medical diagnosis. However, the reliability of multimodal fusion remains largely unexplored especially under low-quality data settings. This paper surveys the common challenges and recent advances of multimodal fusion in the wild and presents them in a comprehensive taxonomy. From a data-centric view, we identify four main challenges that are faced by multimodal fusion on low-quality data, namely (1) noisy multimodal data that are contaminated with heterogeneous noises, (2) incomplete multimodal data that some modalities are missing, (3) imbalanced multimodal data that the qualities or properties of different modalities are significantly different and (4) quality-varying multimodal data that the quality of each modality dynamically changes with respect to different samples. This new taxonomy will enable researchers to understand the state of the field and identify several potential directions. We also provide discussion for the open problems in this field together with interesting future research directions.
- R. Rideaux, K. R. Storrs, G. Maiello, and A. E. Welchman, “How multisensory neurons solve causal inference,” Proceedings of the National Academy of Sciences, vol. 118, no. 32, p. e2106235118, 2021.
- Y. Chang, F. Xue, F. Sheng, W. Liang, and A. Ming, “Fast road segmentation via uncertainty-aware symmetric network,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 11 124–11 130.
- Y. Xiao, F. Codevilla, A. Gurram, O. Urfalioglu, and A. M. López, “Multimodal end-to-end autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, 2020.
- A. Yadav and D. K. Vishwakarma, “A deep multi-level attentive network for multimodal sentiment analysis,” ACM Transactions on Multimedia Computing, Communications and Applications, vol. 19, no. 1, 2023.
- T. Niu, S. Zhu, L. Pang, and A. El Saddik, “Sentiment analysis on multi-view social data,” in MultiMedia Modeling: 22nd International Conference, MMM 2016, Miami, FL, USA, January 4-6, 2016, Proceedings, Part II 22. Springer, 2016, pp. 15–27.
- N. Xu, W. Mao, and G. Chen, “Multi-interactive memory network for aspect based multimodal sentiment analysis,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2019.
- W. Wang, D. Tran, and M. Feiszli, “What makes training multi-modal classification networks hard?” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 12 695–12 705.
- X. Peng, Y. Wei, A. Deng, D. Wang, and D. Hu, “Balanced multimodal learning via on-the-fly gradient modulation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8238–8247.
- N. Wu, S. Jastrzebski, K. Cho, and K. J. Geras, “Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks,” in International Conference on Machine Learning. PMLR, 2022, pp. 24 043–24 055.
- Y. Huang, J. Lin, C. Zhou, H. Yang, and L. Huang, “Modality competition: What makes joint training of multi-modal network fail in deep learning?(provably),” arXiv preprint arXiv:2203.12221, 2022.
- B. Xu, S. Huang, M. Du, H. Wang, H. Song, C. Sha, and Y. Xiao, “Different data, different modalities! reinforced data splitting for effective multimodal information extraction from social media posts,” in Proceedings of the 29th International Conference on Computational Linguistics, 2022, pp. 1855–1864.
- Z. Huang, G. Niu, X. Liu, W. Ding, X. Xiao, H. Wu, and X. Peng, “Learning with noisy correspondence for cross-modal matching,” Advances in Neural Information Processing Systems, vol. 34, pp. 29 406–29 419, 2021.
- C. Xu, D. Tao, and C. Xu, “A survey on multi-view learning,” arXiv preprint arXiv:1304.5634, 2013.
- T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018.
- S. C. Kulkarni and P. P. Rege, “Pixel level fusion techniques for sar and optical images: A review,” Information Fusion, vol. 59, pp. 13–29, 2020.
- X. Cheng, Y. Zhong, Y. Dai, P. Ji, and H. Li, “Noise-aware unsupervised deep lidar-stereo fusion,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 6339–6348. [Online]. Available: http://openaccess.thecvf.com/content_CVPR_2019/html/Cheng_Noise-Aware_Unsupervised_Deep_Lidar-Stereo_Fusion_CVPR_2019_paper.html
- M. Salvi, H. W. Loh, S. Seoni, P. D. Barua, S. García, F. Molinari, and U. R. Acharya, “Multi-modality approaches for medical support systems: A systematic review of the last decade,” Information Fusion, p. 102134, 2023.
- X. Bai, Z. Hu, X. Zhu, Q. Huang, Y. Chen, H. Fu, and C. Tai, “Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 2022, pp. 1080–1089. [Online]. Available: https://doi.org/10.1109/CVPR52688.2022.00116
- B. Rajalingam, F. Al-Turjman, R. Santhoshkumar, and M. Rajesh, “Intelligent multimodal medical image fusion with deep guided filtering,” Multimedia Systems, vol. 28, no. 4, pp. 1449–1463, 2022.
- S. Budhiraja et al., “Multimodal medical image fusion using modified fusion rules and guided filter,” in International Conference on Computing, Communication & Automation. IEEE, 2015, pp. 1067–1072.
- G. Qu, D. Zhang, and P. Yan, “Medical image fusion by wavelet transform modulus maxima,” Optics Express, vol. 9, no. 4, pp. 184–190, 2001.
- A. Achim, C. Canagarajah, and D. Bull, “Complex wavelet domain image fusion based on fractional lower order moments,” in 2005 7th International Conference on Information Fusion, vol. 1. IEEE, 2005, pp. 7–pp.
- N. Yu, T. Qiu, F. Bi, and A. Wang, “Image features extraction and fusion based on joint sparse representation,” IEEE Journal of selected topics in signal processing, vol. 5, no. 5, pp. 1074–1082, 2011.
- M. Gogate, K. Dashtipour, A. Adeel, and A. Hussain, “Cochleanet: A robust language-independent audio-visual model for real-time speech enhancement,” Inf. Fusion, vol. 63, pp. 273–285, 2020. [Online]. Available: https://doi.org/10.1016/j.inffus.2020.04.001
- M. Sadeghi and X. Alameda-Pineda, “Switching variational auto-encoders for noise-agnostic audio-visual speech enhancement,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, June 6-11, 2021. IEEE, 2021, pp. 6663–6667. [Online]. Available: https://doi.org/10.1109/ICASSP39728.2021.9414097
- W.-W. Wang, P.-L. Shui, and X.-C. Feng, “Variational models for fusion and denoising of multifocus images,” IEEE Signal Processing Letters, vol. 15, pp. 65–68, 2008.
- M. Kumar and S. Dass, “A total variation-based algorithm for pixel-level image fusion,” IEEE Transactions on Image Processing, vol. 18, no. 9, pp. 2137–2143, 2009.
- K. Padmavathi, C. Asha, and V. K. Maya, “A novel medical image fusion by combining tv-l1 decomposed textures based on adaptive weighting scheme,” Engineering Science and Technology, an International Journal, vol. 23, no. 1, pp. 225–239, 2020.
- R. Nie, C. Ma, J. Cao, H. Ding, and D. Zhou, “A total variation with joint norms for infrared and visible image fusion,” IEEE Transactions on Multimedia, vol. 24, pp. 1460–1472, 2021.
- Y. Quan, Y. Tong, W. Feng, G. Dauphin, W. Huang, W. Zhu, and M. Xing, “Relative total variation structure analysis-based fusion method for hyperspectral and lidar data classification,” Remote Sensing, vol. 13, no. 6, p. 1143, 2021.
- Y. Liu, D. Zhou, R. Nie, Z. Ding, Y. Guo, X. Ruan, W. Xia, and R. Hou, “Tse_fuse: Two stage enhancement method using attention mechanism and feature-linking model for infrared and visible image fusion,” Digital Signal Processing, vol. 123, p. 103387, 2022.
- S. Changpinyo, P. Sharma, N. Ding, and R. Soricut, “Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3558–3568.
- L. Zhang, X. Zhu, X. Chen, X. Yang, Z. Lei, and Z. Liu, “Weakly aligned cross-modal learning for multispectral pedestrian detection,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5127–5137.
- P. Sharma, N. Ding, S. Goodman, and R. Soricut, “Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2018.
- F. Radenovic, A. Dubey, A. Kadian, T. Mihaylov, S. Vandenhende, Y. Patel, Y. Wen, V. Ramanathan, and D. Mahajan, “Filtering, distillation, and hard negatives for vision-language pre-training,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6967–6977.
- S. Y. Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhang et al., “Datacomp: In search of the next generation of multimodal datasets,” arXiv preprint arXiv:2304.14108, 2023.
- J. A. Maintz and M. A. Viergever, “A survey of medical image registration,” Medical image analysis, vol. 2, no. 1, pp. 1–36, 1998.
- B. Zitova and J. Flusser, “Image registration methods: a survey,” Image and vision computing, vol. 21, no. 11, pp. 977–1000, 2003.
- J. Li, R. Selvaraju, A. Gotmare, S. Joty, C. Xiong, and S. C. H. Hoi, “Align before fuse: Vision and language representation learning with momentum distillation,” Advances in neural information processing systems, vol. 34, pp. 9694–9705, 2021.
- J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in International Conference on Machine Learning. PMLR, 2022, pp. 12 888–12 900.
- R. Huang, Y. Long, J. Han, H. Xu, X. Liang, C. Xu, and X. Liang, “Nlip: Noise-robust language-image pre-training,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 926–934.
- X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei et al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16. Springer, 2020, pp. 121–137.
- R. Nakada, H. I. Gulluk, Z. Deng, W. Ji, J. Zou, and L. Zhang, “Understanding multimodal contrastive learning and incorporating unpaired data,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2023, pp. 4348–4380.
- A. Eitel, J. T. Springenberg, L. Spinello, M. A. Riedmiller, and W. Burgard, “Multimodal deep learning for robust RGB-D object recognition,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2015, Hamburg, Germany, September 28 - October 2, 2015. IEEE, 2015, pp. 681–687. [Online]. Available: https://doi.org/10.1109/IROS.2015.7353446
- D. Hong, N. Yokoya, G.-S. Xia, J. Chanussot, and X. X. Zhu, “X-modalnet: A semi-supervised deep cross-modal network for classification of remote sensing data,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 167, pp. 12–23, 2020.
- F. Huang, A. Jolfaei, and A. K. Bashir, “Robust multimodal representation learning with evolutionary adversarial attention networks,” IEEE Trans. Evol. Comput., vol. 25, no. 5, pp. 856–868, 2021. [Online]. Available: https://doi.org/10.1109/TEVC.2021.3066285
- W. Zhao and H. Lu, “Medical image fusion and denoising with alternating sequential filter and adaptive fractional order total variation,” IEEE Transactions on Instrumentation and Measurement, vol. 66, no. 9, pp. 2283–2294, 2017.
- W. Shao, X. Shi, and S. Y. Philip, “Clustering on multiple incomplete datasets via collective kernel learning,” in IEEE International Conference on Data Mining. IEEE, 2013, pp. 1181–1186.
- D. Zhang, D. Shen, A. D. N. Initiative et al., “Multi-modal multi-task learning for joint prediction of multiple regression and classification variables in alzheimer’s disease,” NeuroImage, vol. 59, no. 2, pp. 895–907, 2012.
- F. Liu, C.-Y. Wee, H. Chen, and D. Shen, “Inter-modality relationship constrained multi-modality multi-task feature selection for alzheimer’s disease and mild cognitive impairment identification,” NeuroImage, vol. 84, pp. 466–475, 2014.
- K.-H. Thung, C.-Y. Wee, P.-T. Yap, D. Shen, A. D. N. Initiative et al., “Neurodegenerative disease diagnosis using incomplete multi-modality data via matrix shrinkage and completion,” NeuroImage, vol. 91, pp. 386–400, 2014.
- J. Wen, Z. Zhang, L. Fei, B. Zhang, Y. Xu, Z. Zhang, and J. Li, “A survey on incomplete multiview clustering,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 53, no. 2, pp. 1136–1149, 2022.
- W. Shao, L. He, and P. S. Yu, “Multiple incomplete views clustering via weighted nonnegative matrix factorization with l 2, 1 regularization,” in Proceedings of the 2015th European Conference on Machine Learning and Knowledge Discovery in Databases-Volume Part I, 2015, pp. 318–334.
- H. Zhao, H. Liu, and Y. Fu, “Incomplete multi-modal visual data grouping,” in Proceedings of the International Joint Conference on Artificial Intelligence, 2016, pp. 2392–2398.
- W. Shao, L. He, C.-t. Lu, and S. Y. Philip, “Online multi-view clustering with incomplete views,” in IEEE International conference on big data (Big Data). IEEE, 2016, pp. 1012–1017.
- H. Wang, L. Zong, B. Liu, Y. Yang, and W. Zhou, “Spectral perturbation meets incomplete multi-view data,” in Proceedings of the International Joint Conference on Artificial Intelligence, 2019, pp. 3677–3683.
- H. Gao, Y. Peng, and S. Jian, “Incomplete multi-view clustering,” in IFIP TC 12 International Conference on Intelligent Information Processing VIII. Springer, 2016, pp. 245–255.
- W. Zhou, H. Wang, and Y. Yang, “Consensus graph learning for incomplete multi-view clustering,” in Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining. Springer, 2019, pp. 529–540.
- D. Williams and L. Carin, “Analytical kernel matrix completion with incomplete multi-view data,” in International Conference on Machine Learning Workshop on Learning with Multiple Views, 2005, pp. 80–86.
- A. Trivedi, P. Rai, H. Daumé III, and S. L. DuVall, “Multiview clustering with incomplete views,” in Annual Conference on Neural Information Processing Systems Workshop on Machine Learning for Social Computing, 2010, pp. 1–8.
- S. Bhadra, S. Kaski, and J. Rousu, “Multi-view kernel completion,” Machine Learning, vol. 106, no. 5, pp. 713–739, 2017.
- Y. Yang, D.-C. Zhan, X.-R. Sheng, and Y. Jiang, “Semi-supervised multi-modal learning with incomplete modalities.” in IJCAI, 2018, pp. 2998–3004.
- X. Liu, X. Zhu, M. Li, L. Wang, E. Zhu, T. Liu, M. Kloft, D. Shen, J. Yin, and W. Gao, “Multiple kernel k𝑘kitalic_k k-means with incomplete kernels,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 5, pp. 1191–1204, 2019.
- Y. Ye, X. Liu, Q. Liu, and J. Yin, “Consensus kernel k-means clustering for incomplete multiview data,” Computational Intelligence and Neuroscience, vol. 2017, pp. 1–11, 2017.
- X. Zhu, X. Liu, M. Li, E. Zhu, L. Liu, Z. Cai, J. Yin, and W. Gao, “Localized incomplete multiple kernel k-means,” in International Joint Conference on Artificial Intelligence, 2018, pp. 3271–3277.
- X. Liu, “Incomplete multiple kernel alignment maximization for clustering,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- J. Wen, K. Yan, Z. Zhang, Y. Xu, J. Wang, L. Fei, and B. Zhang, “Adaptive graph completion based incomplete multi-view clustering,” IEEE Transactions on Multimedia, vol. 23, pp. 2493–2504, 2021.
- C. Shang, A. Palmer, J. Sun, K.-S. Chen, J. Lu, and J. Bi, “Vigan: Missing view imputation with generative adversarial networks,” in EEE International Conference on Big Data. IEEE, 2017, pp. 766–775.
- Q. Wang, Z. Ding, Z. Tao, Q. Gao, and Y. Fu, “Partial multi-view clustering via consistent gan,” in IEEE International Conference on Data Mining. IEEE, 2018, pp. 1290–1295.
- C. Xu, Z. Guan, W. Zhao, H. Wu, Y. Niu, and B. Ling, “Adversarial incomplete multi-view clustering,” in International Joint Conference on Artificial Intelligence, 2019, pp. 3933–3939.
- N. Arya and S. Saha, “Generative incomplete multi-view prognosis predictor for breast cancer: Gimpp,” IEEE/ACM Transactions on Computational Biology and Bioinformatics, vol. 19, no. 4, pp. 2252–2263, 2021.
- L. Tran, X. Liu, J. Zhou, and R. Jin, “Missing modalities imputation via cascaded residual autoencoder,” in IEEE conference on computer vision and pattern recognition, 2017, pp. 1405–1414.
- C. Liu, J. Wen, Z. Wu, X. Luo, C. Huang, and Y. Xu, “Information recovery-driven deep incomplete multiview clustering network,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–11, 2023.
- H. Tang and Y. Liu, “Deep safe incomplete multi-view clustering: Theorem and algorithm,” in International Conference on Machine Learning. PMLR, 2022, pp. 21 090–21 110.
- Y. Lin, Y. Gou, X. Liu, J. Bai, J. Lv, and X. Peng, “Dual contrastive prediction for incomplete multi-view representation learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- J. Wen, Z. Zhang, Y. Xu, B. Zhang, L. Fei, and H. Liu, “Unified embedding alignment with missing views inferring for incomplete multi-view clustering,” in AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 5393–5400.
- J. Yin and S. Sun, “Incomplete multi-view clustering with reconstructed views,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- J. Wen, Z. Zhang, Z. Zhang, L. Zhu, L. Fei, B. Zhang, and Y. Xu, “Unified tensor framework for incomplete multi-view clustering and missing-view inferring,” in AAAI conference on artificial intelligence, vol. 35, no. 11, 2021, pp. 10 273–10 281.
- M. Xie, Z. Han, C. Zhang, Y. Bai, and Q. Hu, “Exploring and exploiting uncertainty for incomplete multi-view classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 873–19 882.
- Y. Lin, Y. Gou, Z. Liu, B. Li, J. Lv, and X. Peng, “Completer: Incomplete multi-view clustering via contrastive prediction,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 174–11 183.
- W. Dong and S. Sun, “Partial multiview representation learning with cross-view generation,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- M. Yang, Y. Li, P. Hu, J. Bai, J. Lv, and X. Peng, “Robust multi-view clustering with incomplete information,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 1055–1069, 2022.
- H. Li, Y. Li, M. Yang, P. Hu, D. Peng, and X. Peng, “Incomplete multi-view clustering via prototype-based imputation,” arXiv preprint arXiv:2301.11045, 2023.
- Y. Ren, X. Chen, J. Xu, J. Pu, Y. Huang, X. Pu, C. Zhu, X. Zhu, Z. Hao, and L. He, “A novel federated multi-view clustering method for unaligned and incomplete data fusion,” Information Fusion, vol. 108, p. 102357, 2024.
- S.-Y. Li, Y. Jiang, and Z.-H. Zhou, “Partial multi-view clustering,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2014, pp. 1968–1974.
- N. Xu, Y. Guo, X. Zheng, Q. Wang, and X. Luo, “Partial multi-view subspace clustering,” in Proceedings of the ACM International conference on multimedia, 2018, pp. 1794–1801.
- T. Zhou, M. Liu, K.-H. Thung, and D. Shen, “Latent representation learning for alzheimer’s disease diagnosis with incomplete multi-modality neuroimaging and genetic data,” IEEE Transactions on Medical Imaging, vol. 38, no. 10, pp. 2411–2422, 2019.
- M. Hu and S. Chen, “Doubly aligned incomplete multi-view clustering,” in Proceedings of the International Joint Conference on Artificial Intelligence, 2018, pp. 2262–2268.
- ——, “One-pass incomplete multi-view clustering,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 3838–3845.
- C. Liu, Z. Wu, J. Wen, Y. Xu, and C. Huang, “Localized sparse incomplete multi-view clustering,” IEEE Transactions on Multimedia, vol. 25, pp. 5539–5551, 2023.
- J. Wen, Z. Zhang, Z. Zhang, L. Fei, and M. Wang, “Generalized incomplete multiview clustering with flexible locality structure diffusion,” IEEE Transactions on Cybernetics, vol. 51, no. 1, pp. 101–114, 2020.
- S. Deng, J. Wen, C. Liu, K. Yan, G. Xu, and Y. Xu, “Projective incomplete multi-view clustering,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- X. Li and S. Chen, “A concise yet effective model for non-aligned incomplete multi-view and missing multi-label learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 5918–5932, 2021.
- C. Zhang, E. Adeli, Z. Wu, G. Li, W. Lin, and D. Shen, “Infant brain development prediction with latent partial multi-view representation learning,” IEEE transactions on medical imaging, vol. 38, no. 4, pp. 909–918, 2018.
- J. Wen, Y. Xu, and H. Liu, “Incomplete multiview spectral clustering with adaptive graph learning,” IEEE Transactions on Cybernetics, vol. 50, no. 4, pp. 1418–1429, 2020.
- J. Wu, W. Zhuge, H. Tao, C. Hou, and Z. Zhang, “Incomplete multi-view clustering via structured graph learning,” in Pacific Rim International Conference on Artificial Intelligence. Springer, 2018, pp. 98–112.
- J. Wen, C. Liu, G. Xu, Z. Wu, C. Huang, L. Fei, and Y. Xu, “Highly confident local structure based consensus graph learning for incomplete multi-view clustering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 712–15 721.
- S. Xiang, L. Yuan, W. Fan, Y. Wang, P. M. Thompson, and J. Ye, “Multi-source learning with block-wise missing data for alzheimer’s disease prediction,” in Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, 2013, pp. 185–193.
- M. Liu, J. Zhang, P.-T. Yap, and D. Shen, “View-aligned hypergraph learning for alzheimer’s disease diagnosis with incomplete multi-modality data,” Medical image analysis, vol. 36, pp. 123–134, 2017.
- X. Liu, X. Zhu, M. Li, L. Wang, C. Tang, J. Yin, D. Shen, H. Wang, and W. Gao, “Late fusion incomplete multi-view clustering,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 10, pp. 2410–2423, 2018.
- X. Liu, M. Li, C. Tang, J. Xia, J. Xiong, L. Liu, M. Kloft, and E. Zhu, “Efficient and effective regularized incomplete multi-view clustering,” IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 8, pp. 2634–2646, 2020.
- Y. Zhang, X. Liu, S. Wang, J. Liu, S. Dai, and E. Zhu, “One-stage incomplete multi-view clustering via late fusion,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 2717–2725.
- L. Zhao, Z. Chen, Y. Yang, Z. J. Wang, and V. C. Leung, “Incomplete multi-view clustering via deep semantic mapping,” Neurocomputing, vol. 275, pp. 1053–1062, 2018.
- J. Wen, Z. Zhang, Z. Zhang, Z. Wu, L. Fei, Y. Xu, and B. Zhang, “Dimc-net: Deep incomplete multi-view clustering network,” in Proceedings of the 28th ACM international conference on multimedia, 2020, pp. 3753–3761.
- J. Wen, Z. Zhang, Y. Xu, B. Zhang, and G. S. Xie, “Cdimc-net: Cognitive deep incomplete multi-view clustering network,” in International Joint Conference on Artificial Intelligence, 2020.
- J. Wen, Z. Wu, Z. Zhang, L. Fei, B. Zhang, and Y. Xu, “Structural deep incomplete multi-view clustering network,” in Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 2021, pp. 3538–3542.
- C. Liu, J. Wen, X. Luo, C. Huang, Z. Wu, and Y. Xu, “Dicnet: Deep instance-level contrastive network for double incomplete multi-view multi-label classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 7, 2023, pp. 8807–8815.
- J. Xu, C. Li, Y. Ren, L. Peng, Y. Mo, X. Shi, and X. Zhu, “Deep incomplete multi-view clustering via mining cluster complementarity,” in AAAI Conference on Artificial Intelligence, vol. 36, no. 8, 2022, pp. 8761–8769.
- C. Zhang, Z. Han, H. Fu, J. T. Zhou, Q. Hu et al., “Cpm-nets: Cross partial multi-view networks,” in Advances in Neural Information Processing Systems, vol. 32, 2019.
- J. Wen, C. Liu, S. Deng, Y. Liu, L. Fei, K. Yan, and Y. Xu, “Deep double incomplete multi-view multi-label learning with incomplete labels and missing views,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
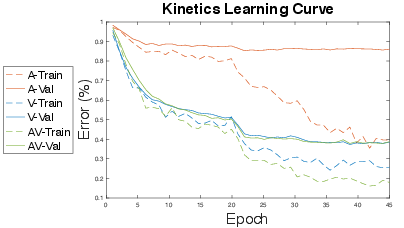
- W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev et al., “The kinetics human action video dataset,” arXiv preprint arXiv:1705.06950, 2017.
- Y. Wang, W. Huang, F. Sun, T. Xu, Y. Rong, and J. Huang, “Deep multimodal fusion by channel exchanging,” Advances in Neural Information Processing Systems, vol. 33, pp. 4835–4845, 2020.
- C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6202–6211.
- Y. Sun, S. Mai, and H. Hu, “Learning to balance the learning rates between various modalities via adaptive tracking factor,” IEEE Signal Processing Letters, vol. 28, pp. 1650–1654, 2021.
- F. Xiao, Y. J. Lee, K. Grauman, J. Malik, and C. Feichtenhofer, “Audiovisual slowfast networks for video recognition,” arXiv preprint arXiv:2001.08740, 2020.
- Y. Zhou and S.-N. Lim, “Joint audio-visual deepfake detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 800–14 809.
- L. Yang, Z. Wu, J. Hong, and J. Long, “Mcl: A contrastive learning method for multimodal data fusion in violence detection,” IEEE Signal Processing Letters, 2022.
- C. Du, J. Teng, T. Li, Y. Liu, T. Yuan, Y. Wang, Y. Yuan, and H. Zhao, “On uni-modal feature learning in supervised multi-modal learning,” arXiv preprint arXiv:2305.01233, 2023.
- S. Liu, L. Li, J. Song, Y. Yang, and X. Zeng, “Multimodal pre-training with self-distillation for product understanding in e-commerce,” in Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, 2023, pp. 1039–1047.
- R. Xu, R. Feng, S.-X. Zhang, and D. Hu, “Mmcosine: Multi-modal cosine loss towards balanced audio-visual fine-grained learning,” arXiv preprint arXiv:2303.05338, 2023.
- Z. Yang, Y. Wei, C. Liang, and D. Hu, “Quantifying and enhancing multi-modal robustness with modality preference,” in The Twelfth International Conference on Learning Representations, 2024.
- Y. Fan, W. Xu, H. Wang, J. Wang, and S. Guo, “Pmr: Prototypical modal rebalance for multimodal learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 20 029–20 038.
- T. Sun, Z. Qian, P. Li, and Q. Zhu, “Graph interactive network with adaptive gradient for multi-modal rumor detection,” in Proceedings of the 2023 ACM International Conference on Multimedia Retrieval, 2023, pp. 316–324.
- J. Fu, J. Gao, and C. Xu, “Multimodal imbalance-aware gradient modulation for weakly-supervised audio-visual video parsing,” arXiv preprint arXiv:2307.02041, 2023.
- Y. He, L. Sun, Z. Lian, B. Liu, J. Tao, M. Wang, and Y. Cheng, “Multimodal temporal attention in sentiment analysis,” in Proceedings of the 3rd International on Multimodal Sentiment Analysis Workshop and Challenge, 2022, pp. 61–66.
- S. Su, J. Zhu, L. Gao, and J. Song, “Utilizing greedy nature for multimodal conditional image synthesis in transformers,” IEEE Transactions on Multimedia, 2023.
- B. Lin, Z. Lin, Y. Guo, Y. Zhang, J. Zou, and S. Fan, “Variational probabilistic fusion network for rgb-t semantic segmentation,” arXiv preprint arXiv:2307.08536, 2023.
- Y. Zhou, X. Liang, S. Zheng, H. Xuan, and T. Kumada, “Adaptive mask co-optimization for modal dependence in multimodal learning,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- Y. Wei, R. Feng, Z. Wang, and D. Hu, “Enhancing multimodal cooperation via sample-level modality valuation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “Vggsound: A large-scale audio-visual dataset,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 721–725.
- H. Ma, Q. Zhang, C. Zhang, B. Wu, H. Fu, J. T. Zhou, and Q. Hu, “Calibrating multimodal learning,” 2023.
- D. Guan, Y. Cao, J. Yang, Y. Cao, and M. Y. Yang, “Fusion of multispectral data through illumination-aware deep neural networks for pedestrian detection,” Information Fusion, vol. 50, pp. 148–157, 2019.
- K. Zhou, L. Chen, and X. Cao, “Improving multispectral pedestrian detection by addressing modality imbalance problems,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16. Springer, 2020, pp. 787–803.
- H. Li and X.-J. Wu, “Densefuse: A fusion approach to infrared and visible images,” IEEE Transactions on Image Processing, vol. 28, no. 5, pp. 2614–2623, 2018.
- R. Panda, C.-F. R. Chen, Q. Fan, X. Sun, K. Saenko, A. Oliva, and R. Feris, “Adamml: Adaptive multi-modal learning for efficient video recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 7576–7585.
- X. Zheng, C. Tang, Z. Wan, C. Hu, and W. Zhang, “Multi-level confidence learning for trustworthy multimodal classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 11 381–11 389.
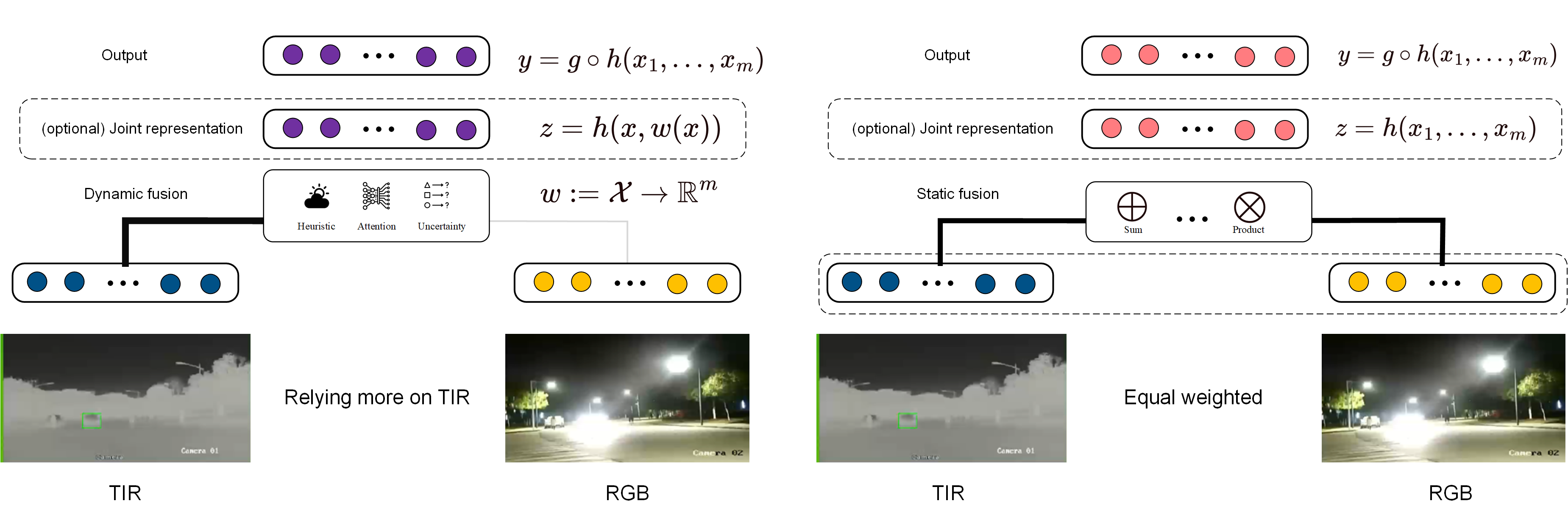
- Z. Xue and R. Marculescu, “Dynamic multimodal fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2574–2583.
- L. Sun, B. Liu, J. Tao, and Z. Lian, “Multimodal cross-and self-attention network for speech emotion recognition,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 4275–4279.
- Y. Cao, J. Bin, J. Hamari, E. Blasch, and Z. Liu, “Multimodal object detection by channel switching and spatial attention,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 403–411.
- H. R. V. Joze, A. Shaban, M. L. Iuzzolino, and K. Koishida, “Mmtm: Multimodal transfer module for cnn fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 289–13 299.
- A. Nagrani, S. Yang, A. Arnab, A. Jansen, C. Schmid, and C. Sun, “Attention bottlenecks for multimodal fusion,” Advances in Neural Information Processing Systems, vol. 34, pp. 14 200–14 213, 2021.
- R. Girdhar, M. Singh, N. Ravi, L. van der Maaten, A. Joulin, and I. Misra, “Omnivore: A single model for many visual modalities,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 102–16 112.
- Y. Wang, X. Chen, L. Cao, W. Huang, F. Sun, and Y. Wang, “Multimodal token fusion for vision transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 186–12 195.
- J. Tian, W. Cheung, N. Glaser, Y.-C. Liu, and Z. Kira, “Uno: Uncertainty-aware noisy-or multimodal fusion for unanticipated input degradation,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 5716–5723.
- Q. Zhang, H. Wu, C. Zhang, Q. Hu, H. Fu, J. T. Zhou, and X. Peng, “Provable dynamic fusion for low-quality multimodal data,” arXiv preprint arXiv:2306.02050, 2023.
- Y.-T. Chen, J. Shi, Z. Ye, C. Mertz, D. Ramanan, and S. Kong, “Multimodal object detection via probabilistic ensembling,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IX. Springer, 2022, pp. 139–158.
- Z. Han, C. Zhang, H. Fu, and J. T. Zhou, “Trusted multi-view classification,” arXiv preprint arXiv:2102.02051, 2021.
- Q. Li, C. Zhang, Q. Hu, H. Fu, and P. Zhu, “Confidence-aware fusion using dempster-shafer theory for multispectral pedestrian detection,” IEEE Transactions on Multimedia, 2022.
- M. Feng, K. Xu, N. Wu, W. Huang, Y. Bai, C. Wang, and H. Wang, “Trusted multi-scale classification framework for whole slide image,” arXiv preprint arXiv:2207.05290, 2022.
- W. Liu, X. Yue, Y. Chen, and T. Denoeux, “Trusted multi-view deep learning with opinion aggregation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, 2022, pp. 7585–7593.
- Y. Geng, Z. Han, C. Zhang, and Q. Hu, “Uncertainty-aware multi-view representation learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 9, 2021, pp. 7545–7553.
- M. K. Tellamekala, S. Amiriparian, B. W. Schuller, E. André, T. Giesbrecht, and M. Valstar, “Cold fusion: Calibrated and ordinal latent distribution fusion for uncertainty-aware multimodal emotion recognition,” arXiv preprint arXiv:2206.05833, 2022.
- H. Ma, Z. Han, C. Zhang, H. Fu, J. T. Zhou, and Q. Hu, “Trustworthy multimodal regression with mixture of normal-inverse gamma distributions,” Advances in Neural Information Processing Systems, vol. 34, pp. 6881–6893, 2021.
- Z. Han, F. Yang, J. Huang, C. Zhang, and J. Yao, “Multimodal dynamics: Dynamical fusion for trustworthy multimodal classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 707–20 717.
- M. C. Jung, H. Zhao, J. Dipnall, B. Gabbe, and L. Du, “Uncertainty estimation for multi-view data: The power of seeing the whole picture,” Advances in Neural Information Processing Systems, vol. 35, pp. 6517–6530, 2022.
- D. Hazarika, S. Gorantla, S. Poria, and R. Zimmermann, “Self-attentive feature-level fusion for multimodal emotion detection,” in 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR). IEEE, 2018, pp. 196–201.
- Q. Li, C. Zhang, Q. Hu, P. Zhu, H. Fu, and L. Chen, “Stabilizing multispectral pedestrian detection with evidential hybrid fusion,” IEEE Transactions on Circuits and Systems for Video Technology, 2023.
- S. Chen, X. Yang, Y. Chen, H. Yu, and H. Cai, “Uncertainty-based fusion netwok for automatic skin lesion diagnosis,” in 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 2022, pp. 1487–1492.
- C. Xu, J. Si, Z. Guan, W. Zhao, Y. Wu, and X. Gao, “Reliable conflictive multi-view learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2024, pp. 16 129–16 137.
- D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” arXiv preprint arXiv:1610.02136, 2016.
- C. Corbière, N. Thome, A. Bar-Hen, M. Cord, and P. Pérez, “Addressing failure prediction by learning model confidence,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- Y. Huang, C. Du, Z. Xue, X. Chen, H. Zhao, and L. Huang, “What makes multi-modal learning better than single (provably),” Advances in Neural Information Processing Systems, vol. 34, pp. 10 944–10 956, 2021.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.