Are Large Language Models Good at Utility Judgments?
Abstract: Retrieval-augmented generation (RAG) is considered to be a promising approach to alleviate the hallucination issue of LLMs, and it has received widespread attention from researchers recently. Due to the limitation in the semantic understanding of retrieval models, the success of RAG heavily lies on the ability of LLMs to identify passages with utility. Recent efforts have explored the ability of LLMs to assess the relevance of passages in retrieval, but there has been limited work on evaluating the utility of passages in supporting question answering. In this work, we conduct a comprehensive study about the capabilities of LLMs in utility evaluation for open-domain QA. Specifically, we introduce a benchmarking procedure and collection of candidate passages with different characteristics, facilitating a series of experiments with five representative LLMs. Our experiments reveal that: (i) well-instructed LLMs can distinguish between relevance and utility, and that LLMs are highly receptive to newly generated counterfactual passages. Moreover, (ii) we scrutinize key factors that affect utility judgments in the instruction design. And finally, (iii) to verify the efficacy of utility judgments in practical retrieval augmentation applications, we delve into LLMs' QA capabilities using the evidence judged with utility and direct dense retrieval results. (iv) We propose a k-sampling, listwise approach to reduce the dependency of LLMs on the sequence of input passages, thereby facilitating subsequent answer generation. We believe that the way we formalize and study the problem along with our findings contributes to a critical assessment of retrieval-augmented LLMs. Our code and benchmark can be found at \url{https://github.com/ict-bigdatalab/utility_judgments}.
- Ahmad Aghaebrahimian. 2018. Linguistically-based Deep Unstructured Question Answering. CoNLL, 433–443.
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://vicuna.lmsys.org (Accessed 14 April 2023).
- Nick Craswell. 2009. Mean Reciprocal Rank. Encyclopedia of database systems 1703 (2009).
- Perspectives on Large Language Models for Relevance Judgment. In SIGIR. 39–50.
- RIGHT: Retrieval-Augmented Generation for Mainstream Hashtag Recommendation. In European Conference on Information Retrieval. Springer, 39–55.
- Reformatted Alignment. arXiv preprint arXiv:2402.12219 (2024). https://arxiv.org/abs/2402.12219
- ANTIQUE: A Non-factoid Question Answering Benchmark. In ECIR 2020. Springer, 166–173.
- DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION. In ICLR.
- M. Honnibal. 2017-06-23. spaCy. (2017-06-23). https://spacy.io/
- Large Language Models are Zero-shot Rankers for Recommender Systems. arXiv preprint arXiv:2305.08845 (2023).
- Gautier Izacard and Edouard Grave. 2021. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. EACL (2021).
- Few-shot Learning with Retrieval Augmented Language Models. arXiv preprint arXiv:2208.03299 (2022).
- Kalervo Järvelin and Jaana Kekäläinen. 2017. IR Evaluation Methods for Retrieving Highly Relevant Focuments. In SIGIR, Vol. 51. 243–250.
- LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion. ACL (2023).
- Large Language Models are Zero-shot Reasoners. NeurIPS 35 (2022), 22199–22213.
- Natural Questions: A Benchmark for Question Answering Research. TACL 7 (2019), 453–466.
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 33 (2020), 9459–9474.
- Self-alignment with instruction backtranslation. arXiv preprint arXiv:2308.06259 (2023).
- Chin-Yew Lin. 2004. Rouge: A Package for Automatic Evaluation of Summaries. In Text summarization branches out. 74–81.
- WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences. KDD (2023).
- Black-box Adversarial Attacks against Dense Retrieval Models: A Multi-view Contrastive Learning Method. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1647–1656.
- Topic-oriented Adversarial Attacks against Black-box Neural Ranking Models. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1700–1709.
- Entity-based Knowledge Conflicts in Question Answering. EMNLP (2021).
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. ACL (2022).
- When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-parametric Memories. In ACL. 9802–9822.
- MS MARCO: A Human Generated Machine Reading Comprehension Dataset. choice 2640 (2016), 660.
- When Do LLMs Need Retrieval Augmentation? Mitigating LLMs’ Overconfidence Helps Retrieval Augmentation. arXiv preprint arXiv:2402.11457 (2024).
- Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085 (2019).
- OpenAI. 2022. Introducing ChatGPT. (2022). openai.com/blog/chatgpt.
- Bleu: a Method for Automatic Evaluation of Machine Translation. In ACL. 311–318.
- Pouya Pezeshkpour and Estevam Hruschka. 2023. Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483 (2023).
- RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models. arXiv preprint arXiv:2309.15088 (2023).
- Large Language Models are Effective Text Rankers with Pairwise Ranking prompting. arXiv preprint arXiv:2306.17563 (2023).
- In-Context Retrieval-Augmented Language Models. TACL (2023).
- RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking. EMNLP (2021).
- Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval Augmentation. arXiv preprint arXiv:2307.11019 (2023).
- Tefko Saracevic. 2016. The Notion of Relevance in Information Science: Everybody knows what relevance is. But, what is it really? Morgan & Claypool Publishers.
- A study of information seeking and retrieving. I. Background and methodology. Journal of the American Society for Information science 39, 3 (1988), 161–176.
- REPLUG: Retrieval-augmented Black-box Language Models. arXiv preprint arXiv:2301.12652 (2023).
- Retrieval Augmentation Reduces Hallucination in Conversation. arXiv preprint arXiv:2104.07567 (2021).
- Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent. EMNLP (2023).
- Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288 (2023).
- Cort: A new baseline for comparative opinion classification by dual prompts. In Findings of the Association for Computational Linguistics: EMNLP 2022. 7064–7075.
- Chain-of-thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 35 (2022), 24824–24837.
- Are Neural Ranking Models Robust? TOIS 41, 2 (2022), 1–36.
- Adaptive Chameleon or Stubborn Sloth: Unraveling the Behavior of Large Language Models in Knowledge Conflicts. arXiv preprint arXiv:2305.13300 (2023).
- Factual and Informative Review Generation for Explainable Recommendation. In AAAI, Vol. 37. 13816–13824.
- HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. ACL (2018).
- Generate Rather than Retrieve: Large Language Models are Strong Context Generators. ICLR (2023).
- Retrieval-enhanced Machine Learning. In SIGIR. 2875–2886.
- Optimizing Dense Retrieval Model Training with Hard Negatives. In SIGIR. 1503–1512.
- From Relevance to Utility: Evidence Retrieval with Feedback for Fact Verification. EMNLP Findings (2023).
- Hybrid Retrieval-Augmented Generation for Real-time Composition Assistance. arXiv preprint arXiv:2308.04215 (2023).
- Beyond Yes and No: Improving Zero-shot LLM Rankers via Scoring Fine-grained Relevance Labels. arXiv preprint arXiv:2310.14122 (2023).
- A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models. arXiv preprint arXiv:2310.09497 (2023).

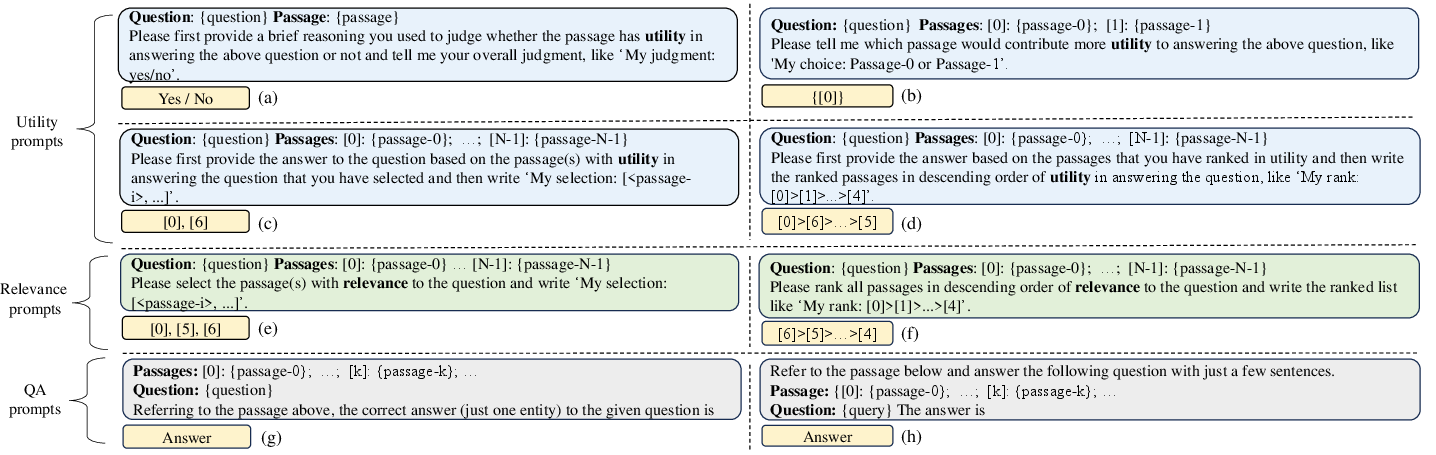
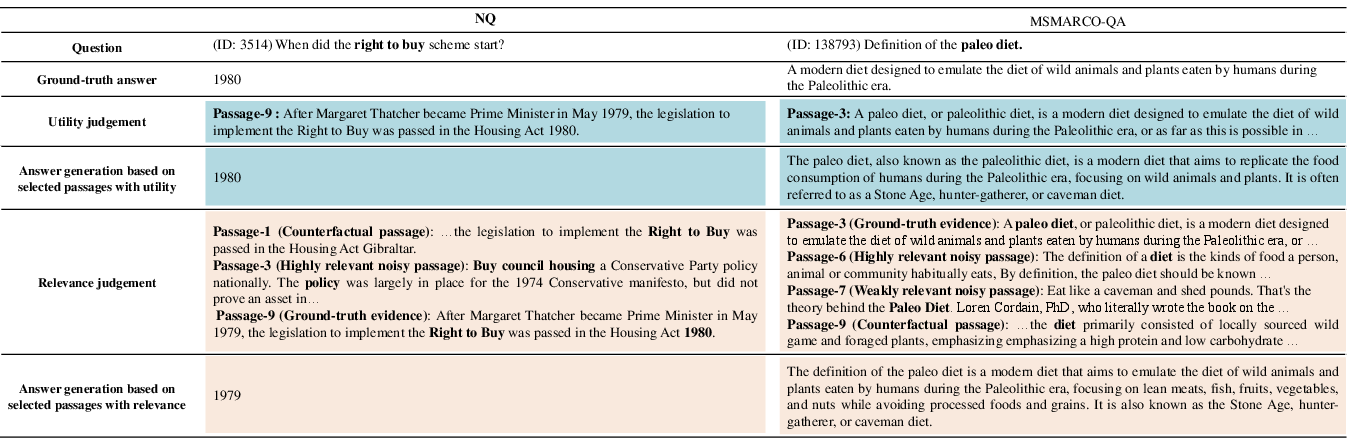
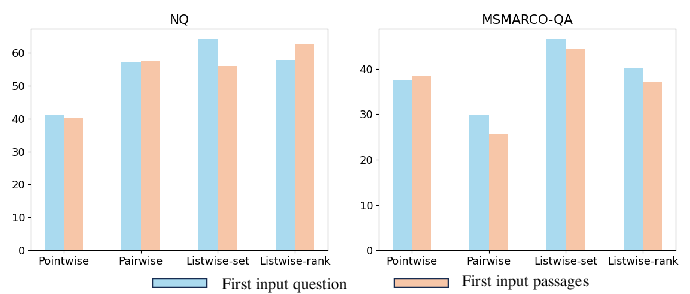
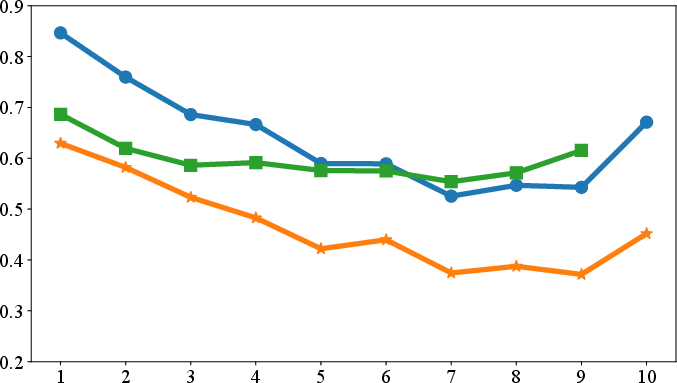
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

