- The paper presents FIT-RAG, which optimizes retrieval-augmented generation by scoring documents for factual content alongside LLM preferences.
- It employs a bi-label document scorer and a self-knowledge recognizer to effectively balance accuracy and token efficiency.
- Experimental results show up to 27.5% improvement in accuracy and nearly 50% token reduction on benchmarks like TriviaQA and NQ.
The paper "FIT-RAG: Black-Box RAG with Factual Information and Token Reduction" introduces a framework designed to optimize the integration of retrieval-augmented generation (RAG) systems with LLMs treated as black-box entities. This approach endeavors to balance the effectiveness and efficiency of RAG systems by incorporating factual information and reducing token usage.
Introduction to Black-Box RAG
Traditional RAG systems fine-tune the retrieval component to align with LLMs' preference, while treating LLMs as black-boxes, which remains unmodified. This adaptation becomes critical considering the prohibitive computational cost and impracticality of fine-tuning LLMs with billions of parameters for knowledge updates.
A significant issue with existing black-box RAG methods is their reliance on documents preferred by LLMs but which may lack relevant factual knowledge. This leads to two main challenges: the potential misinformation and excessive token usage, where concatenating entire documents inflates token counts unnecessarily.

Figure 1: Examples illustrating LLM preferred retrieved documents that do not contain relevant factual information.
FIT-RAG Overview
FIT-RAG addresses the aforementioned challenges through a novel architecture encompassing:
- Similarity-Based Retrieval: Initial candidate documents retrieval using vector-based similarity.
- Bi-Label Document Scorer: Scoring documents based on factual content (Has_Answer) and LLM preference (LLM_Prefer), addressing both factual relevance and LLM alignment.
- Bi-Faceted Self-Knowledge Recognizer: Determines if external knowledge is essential, discerning LLM self-knowledge through long-tail knowledge indicators and neighboring queries.
- Sub-Document-Level Token Reducer: Efficient token use by selecting sub-documents that meet content requirements, thus reducing excessive token input.
- Prompt Construction: Designing tailored prompt templates for scenarios requiring or not requiring RAG.
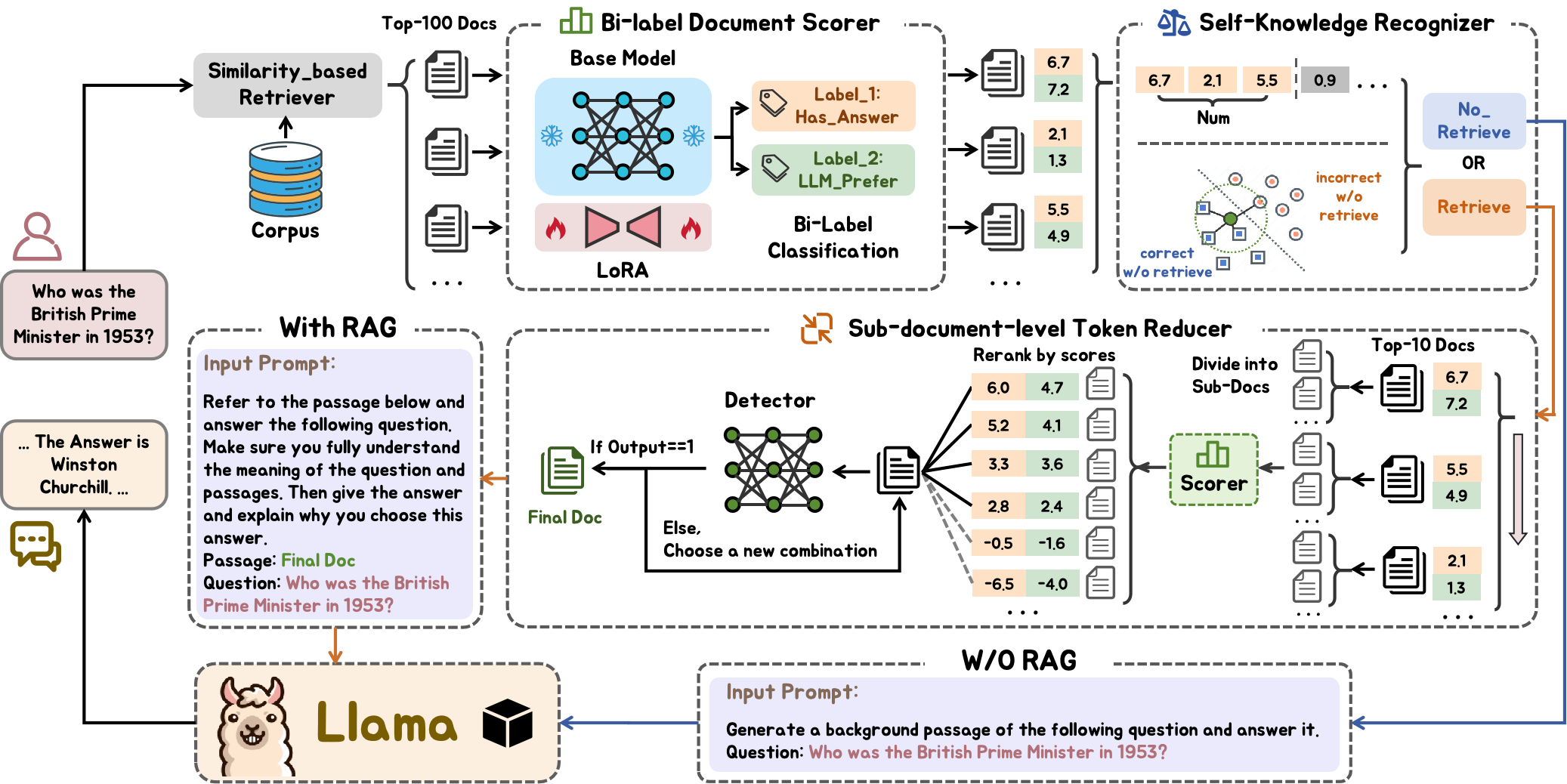
Figure 2: The overview of FIT-RAG.
Bi-Label Document Scorer
One core innovation is the bi-label document scorer, which evaluates documents by simultaneously considering two attributes: capacity to provide factual answers and their usefulness to LLMs. This dual-labelling framework is trained with a data-imbalance-aware learning approach to address uneven distribution in document scores, leveraging hypergradient descent.
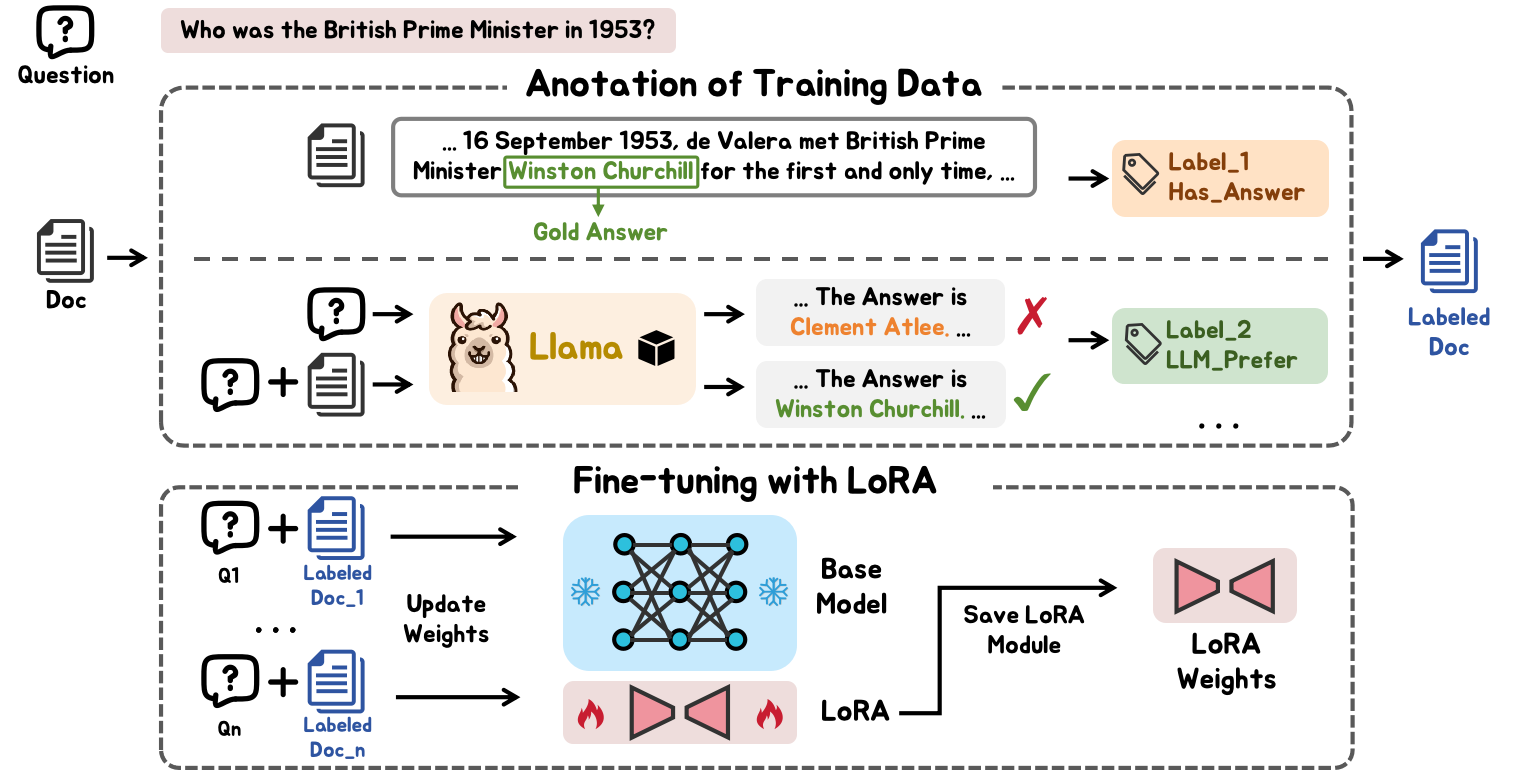
Figure 3: The training process of the Bi-Label Document Scorer.
Bi-Faceted Self-Knowledge Recognizer
This component assesses whether retrieval is necessary by evaluating potential LLM self-knowledge through long-tail relevance and neighbor analysis. Questions not related to updated or long-tail knowledge, determined through metrics utilizing Wikipedia page views, allow omission of unnecessary retrieval, conserving resources.
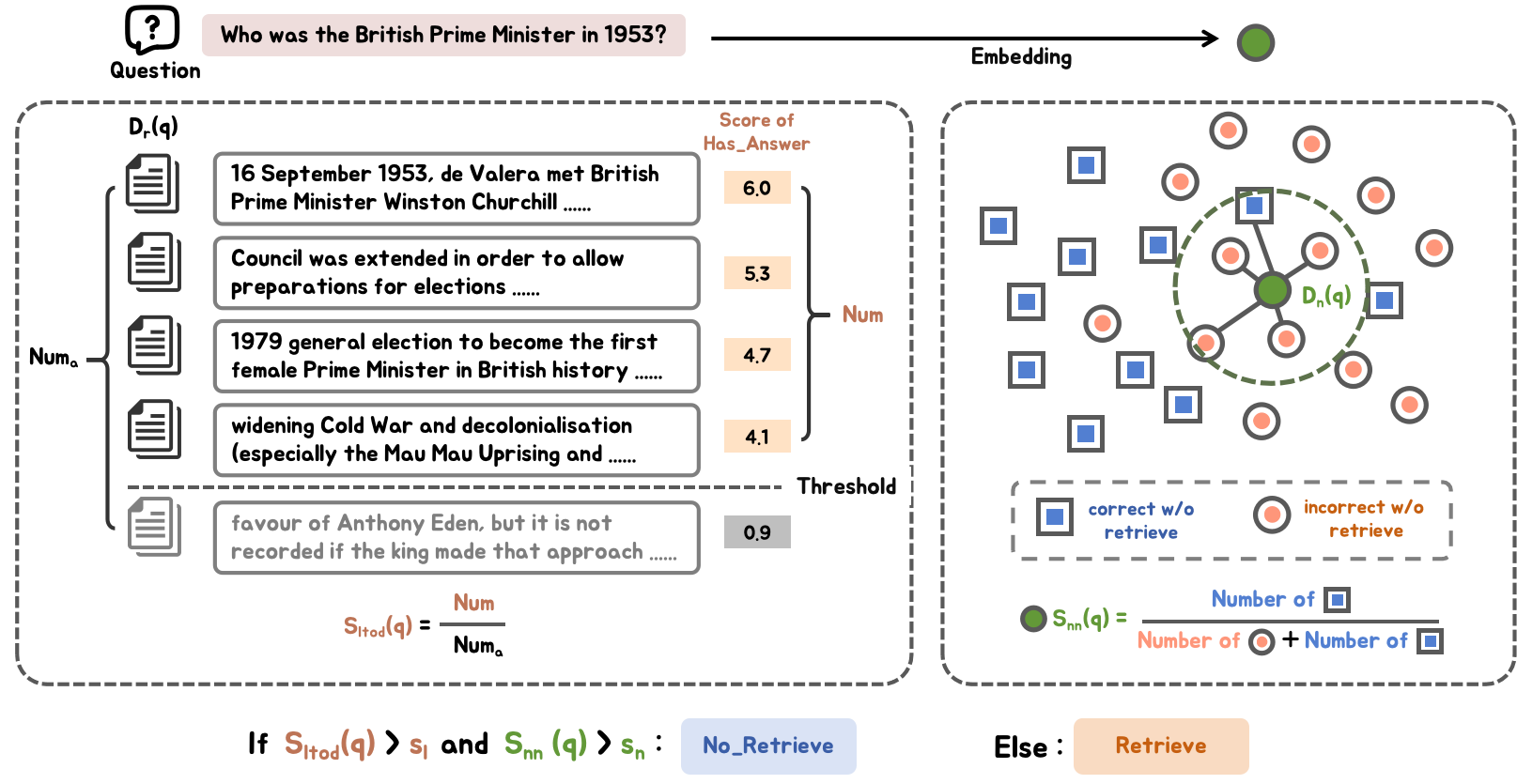
Figure 4: The inference process of Bi-faceted Self-Knowledge Recognizer.
Token Efficiency through Sub-Document-Level Reduction
By dividing documents into sub-sections, FIT-RAG minimizes token usage without sacrificing detail. The system employs a shortlist of high-relevance sub-documents, determined through a ranked selection process, that is then filtered to create optimal augmentation sub-sets for the LLM.
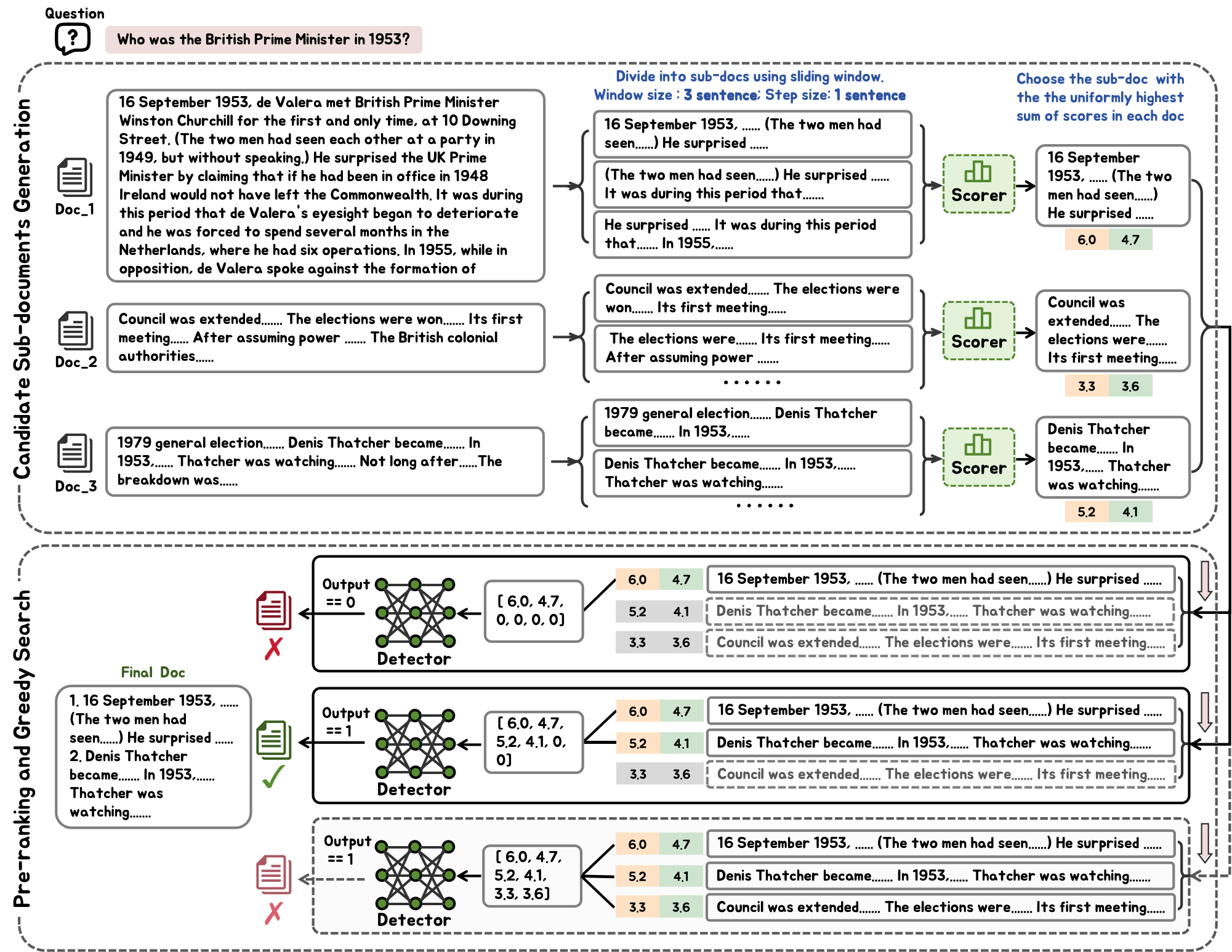
Figure 5: The inference process of Sub-document-level Token Reducer.
This technique proves essential for maintaining efficiency, upholding performance metrics without inundating the LLM prompt with unnecessary tokens.
Experimental validation demonstrates the efficacy of FIT-RAG, achieving improvements in factual accuracy and response quality across datasets like TriviaQA, NQ, and PopQA. Accuracy gains of up to 27.5% were recorded over baseline models, alongside roughly halved token usage.
Conclusions
FIT-RAG presents a practical framework for harnessing the power of LLMs without the substantiation and drawbacks of extensive fine-tuning. By offering a method that maximizes informative content through controlled token use, FIT-RAG holds potential for applications demanding real-time processing with constrained computational resources. Future directions may explore broadening this approach to encompass multi-modal data or further optimizing retrieval mechanisms.