Graph-oriented Instruction Tuning of Large Language Models for Generic Graph Mining
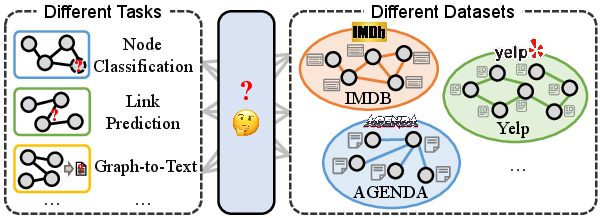
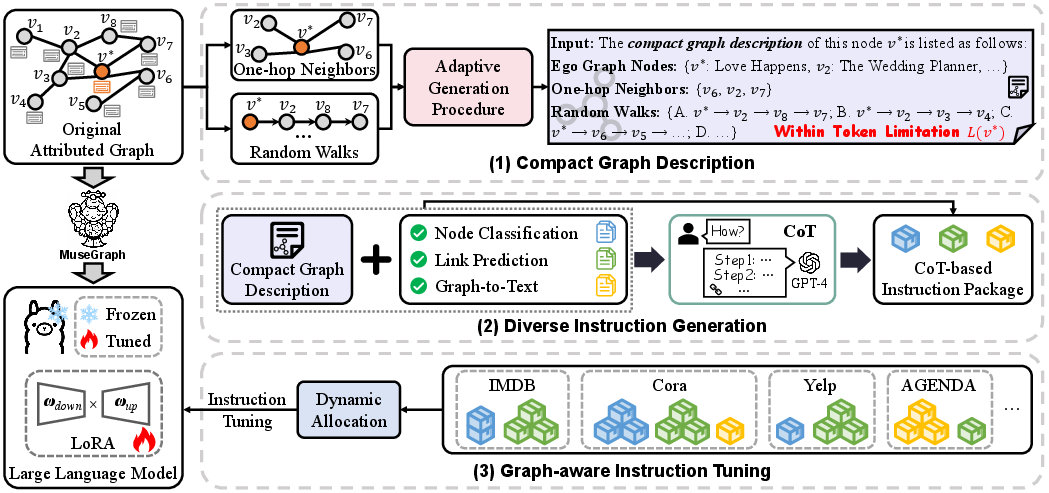
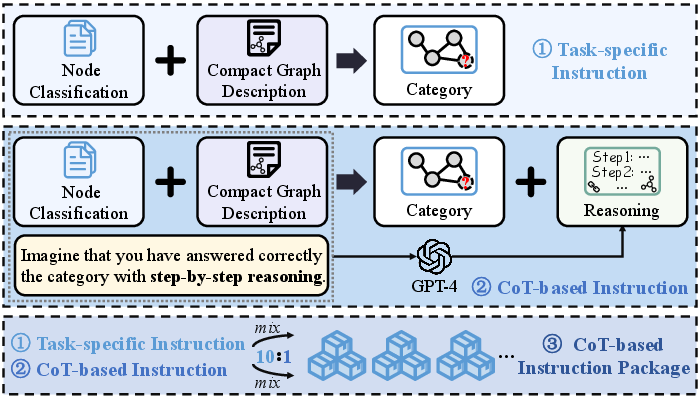
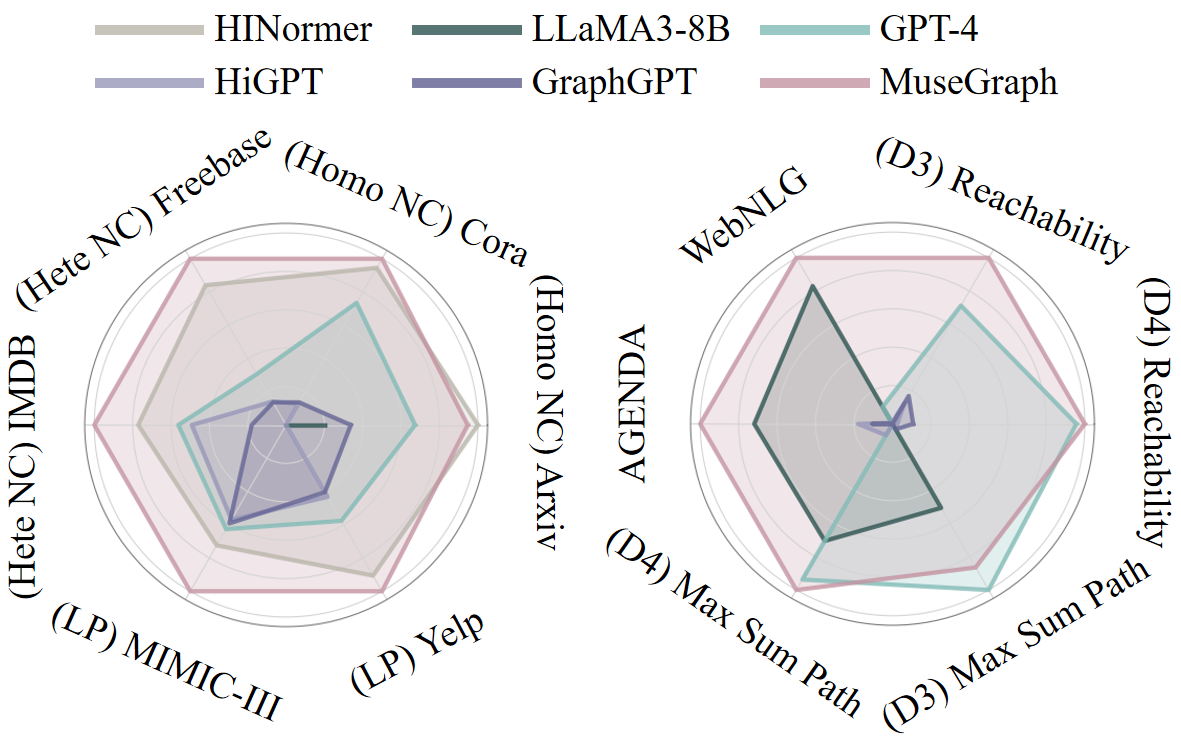
Abstract: Graphs with abundant attributes are essential in modeling interconnected entities and enhancing predictions across various real-world applications. Traditional Graph Neural Networks (GNNs) often require re-training for different graph tasks and datasets. Although the emergence of LLMs has introduced new paradigms in natural language processing, their potential for generic graph mining, training a single model to simultaneously handle diverse tasks and datasets, remains under-explored. To this end, our novel framework MuseGraph, seamlessly integrates the strengths of GNNs and LLMs into one foundation model for graph mining across tasks and datasets. This framework first features a compact graph description to encapsulate key graph information within language token limitations. Then, we propose a diverse instruction generation mechanism with Chain-of-Thought (CoT)-based instruction packages to distill the reasoning capabilities from advanced LLMs like GPT-4. Finally, we design a graph-aware instruction tuning strategy to facilitate mutual enhancement across multiple tasks and datasets while preventing catastrophic forgetting of LLMs' generative abilities. Our experimental results demonstrate significant improvements in five graph tasks and ten datasets, showcasing the potential of our MuseGraph in enhancing the accuracy of graph-oriented downstream tasks while improving the generation abilities of LLMs.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Dbpedia: A nucleus for a web of open data, in ‘the semantic web’, vol. 4825 of lecture notes in computer science, 2007.
- S. Banerjee and A. Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005.
- A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE Trans. Knowl. Data Eng., 30(9):1616–1637, 2018.
- Exploring the potential of large language models (llms) in learning on graphs. arXiv preprint arXiv:2307.03393, 2023.
- Label-free node classification on graphs with large language models (llms). arXiv preprint arXiv:2310.04668, 2023.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2023.
- T. Cooray and N.-M. Cheung. Graph-wise common latent factor extraction for unsupervised graph representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 6420–6428, 2022.
- Adaptive graph encoder for attributed graph embedding. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 976–985, 2020.
- Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023.
- metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 135–144, 2017.
- Hyperbolic geometric graph representation learning for hierarchy-imbalance node classification. In Proceedings of the ACM Web Conference 2023, pages 460–468, 2023.
- Creating training corpora for nlg micro-planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 179–188. Association for Computational Linguistics, 2017.
- A. Grover and J. Leskovec. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 855–864, 2016.
- Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking. arXiv preprint arXiv:2305.15066, 2023.
- Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017.
- Representation learning on graphs: Methods and applications. IEEE Data Eng. Bull., 40(3):52–74, 2017.
- Explanations as features: Llm-based features for text-attributed graphs. arXiv preprint arXiv:2305.19523, 2023.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020.
- Gpt-gnn: Generative pre-training of graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1857–1867, 2020.
- Prodigy: Enabling in-context learning over graphs. arXiv preprint arXiv:2305.12600, 2023.
- S. Ivanov and E. Burnaev. Anonymous walk embeddings. In International conference on machine learning, pages 2186–2195. PMLR, 2018.
- Pre-training on large-scale heterogeneous graph. In Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, pages 756–766, 2021.
- Instruct and extract: Instruction tuning for on-demand information extraction. arXiv preprint arXiv:2310.16040, 2023.
- Mimic-iii, a freely accessible critical care database. Scientific data, 2016.
- T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017.
- Text generation from knowledge graphs with graph transformers. arXiv preprint arXiv:1904.02342, 2019.
- Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
- Training graph neural networks with 1000 layers. In International conference on machine learning, pages 6437–6449. PMLR, 2021.
- A survey of graph meets large language model: Progress and future directions, 2024.
- C.-Y. Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.
- One for all: Towards training one graph model for all classification tasks. ICLR, 2024.
- Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. arXiv preprint arXiv:1808.09602, 2018.
- Hinormer: Representation learning on heterogeneous information networks with graph transformer. In Proceedings of the ACM Web Conference 2023, pages 599–610, 2023.
- Automating the construction of internet portals with machine learning. Information Retrieval, 3:127–163, 2000.
- M. McCloskey and N. J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989.
- S. Micali and Z. A. Zhu. Reconstructing markov processes from independent and anonymous experiments. Discrete Applied Mathematics, 200:108–122, 2016.
- On the stability of fine-tuning bert: Misconceptions, explanations, and strong baselines. In International Conference on Learning Representations, 2020.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 701–710, 2014.
- M. Popović. chrf++: words helping character n-grams. In Proceedings of the second conference on machine translation, pages 612–618, 2017.
- Can large language models empower molecular property prediction? arXiv preprint arXiv:2307.07443, 2023.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Modeling global and local node contexts for text generation from knowledge graphs. Transactions of the Association for Computational Linguistics, 8:589–604, 2020.
- Distilling reasoning capabilities into smaller language models. In Findings of the Association for Computational Linguistics: ACL 2023, pages 7059–7073, 2023.
- Gppt: Graph pre-training and prompt tuning to generalize graph neural networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1717–1727, 2022.
- All in one: Multi-task prompting for graph neural networks. Proceedings of the 29rd ACM SIGKDD international conference on knowledge discovery and data mining, 2023.
- Walklm: A uniform language model fine-tuning framework for attributed graph embedding. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Graphgpt: Graph instruction tuning for large language models. arXiv preprint arXiv:2310.13023, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Graph attention networks. stat, 1050(20):10–48550, 2017.
- Deep Graph Infomax. In International Conference on Learning Representations, 2019.
- S. Vijay and A. Priyanshu. Nerda-con: Extending ner models for continual learning–integrating distinct tasks and updating distribution shifts. International Conference on Machine Learning, 2022.
- Can language models solve graph problems in natural language?, 2024.
- Microsoft academic graph: When experts are not enough. Quantitative Science Studies, 1(1):396–413, 2020.
- A survey on heterogeneous graph embedding: Methods, techniques, applications and sources. IEEE Trans. Big Data, 9(2):415–436, 2023.
- Heterogeneous graph attention network. In The world wide web conference, pages 2022–2032, 2019.
- How far can camels go? exploring the state of instruction tuning on open resources. arXiv preprint arXiv:2306.04751, 2023.
- Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560, 2022.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Difformer: Scalable (graph) transformers induced by energy constrained diffusion. arXiv preprint arXiv:2301.09474, 2023.
- Nodeformer: A scalable graph structure learning transformer for node classification. Advances in Neural Information Processing Systems, 35:27387–27401, 2022.
- A comprehensive survey on graph neural networks. IEEE Trans. Neural Networks Learn. Syst., 32(1):4–24, 2021.
- Badchain: Backdoor chain-of-thought prompting for large language models. ICLR, 2024.
- Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305, 2023.
- Geometric knowledge distillation: Topology compression for graph neural networks. Advances in Neural Information Processing Systems, 35:29761–29775, 2022.
- Relation learning on social networks with multi-modal graph edge variational autoencoders. In Proceedings of the 13th International Conference on Web Search and Data Mining, pages 699–707, 2020.
- Natural language is all a graph needs. arXiv preprint arXiv:2308.07134, 2023.
- S. Yuan and M. Färber. Evaluating generative models for graph-to-text generation. arXiv preprint arXiv:2307.14712, 2023.
- M. Zhang and Y. Chen. Link prediction based on graph neural networks. Advances in neural information processing systems, 31, 2018.
- Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512, 2023.
- Graph-less neural networks: Teaching old mlps new tricks via distillation. arXiv preprint arXiv:2110.08727, 2021.
- Structure pretraining and prompt tuning for knowledge graph transfer. In Proceedings of the ACM Web Conference 2023, pages 2581–2590, 2023.
- Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning. bioRxiv, pages 2023–05, 2023.
- Graph neural networks: A review of methods and applications. AI open, 1:57–81, 2020.
- Transfer learning of graph neural networks with ego-graph information maximization. Advances in Neural Information Processing Systems, 34:1766–1779, 2021.
- Graph contrastive learning with adaptive augmentation. In Proceedings of the Web Conference 2021, pages 2069–2080, 2021.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.