- The paper introduces SLEB, which prunes LLMs by eliminating redundant transformer blocks to speed up inference without retraining.
- It leverages cosine similarity for redundancy verification, ensuring minimal impact on model perplexity while maintaining language quality.
- Experimental results demonstrate significant speedup and robust performance, with compatibility to quantization techniques for further optimization.
The paper presents SLEB, a novel methodology for pruning LLMs by removing redundant transformer blocks. This approach aims to enhance the inference speed of LLMs while maintaining their linguistic capabilities.
Introduction to SLEB
The exponential growth in LLM parameters poses challenges in deploying these models for real-world applications due to substantial memory and computational demands. Pruning, a common technique to reduce model size, often struggles to accelerate end-to-end inference due to the complexities of managing sparsity, especially on GPU architectures optimized for dense matrices.
SLEB introduces the concept of streamlining LLMs by eliminating entire transformer blocks, which often exhibit block-level redundancy. This method enhances the inference speed of LLMs without compromising their linguistic prowess (Figure 1).
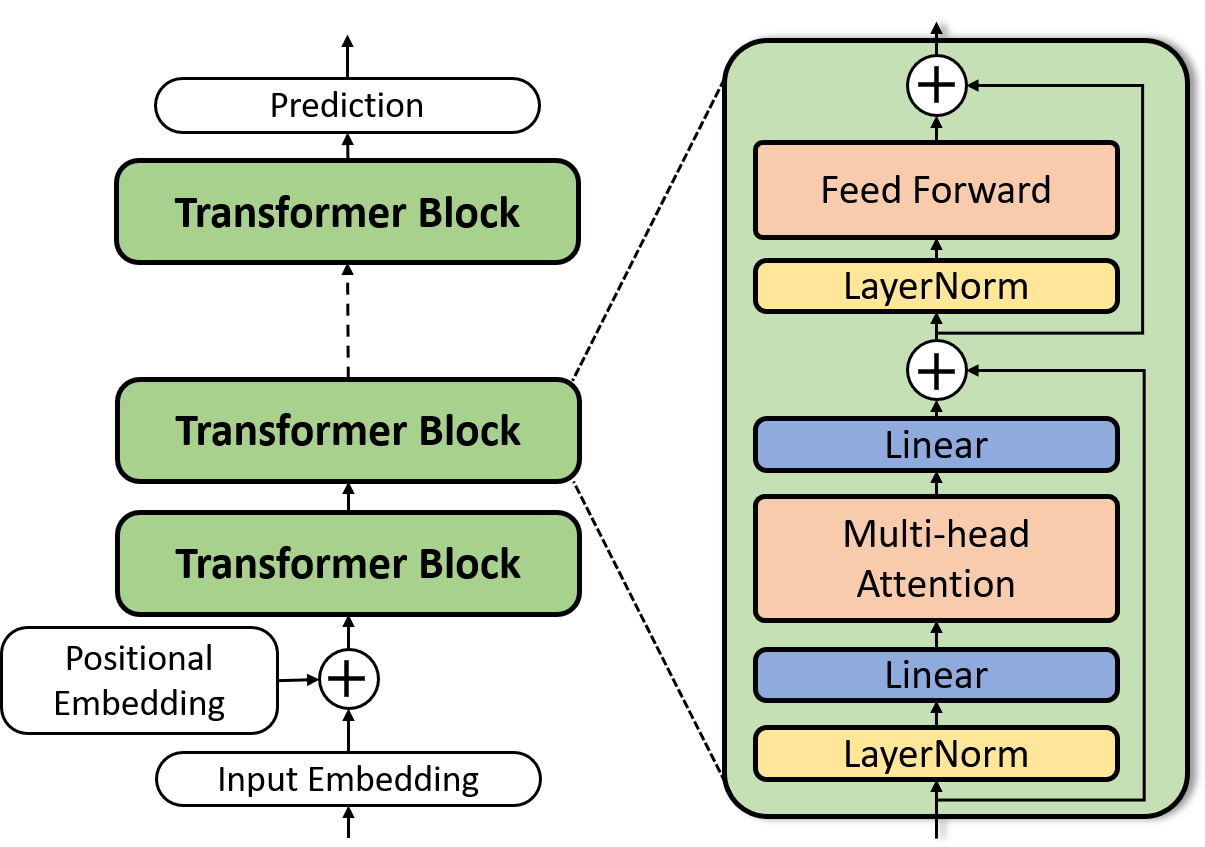
Figure 1: Typical LLM architecture.
Motivations and Challenges
Pruning Techniques
Existing pruning techniques can be categorized into unstructured and structured. Unstructured pruning often requires extremely high sparsity to achieve speedups, whereas structured pruning must contend with hardware inefficiencies, such as the dependence on the batch size and matrix dimensions for achieving optimal speed gains (Figure 2).
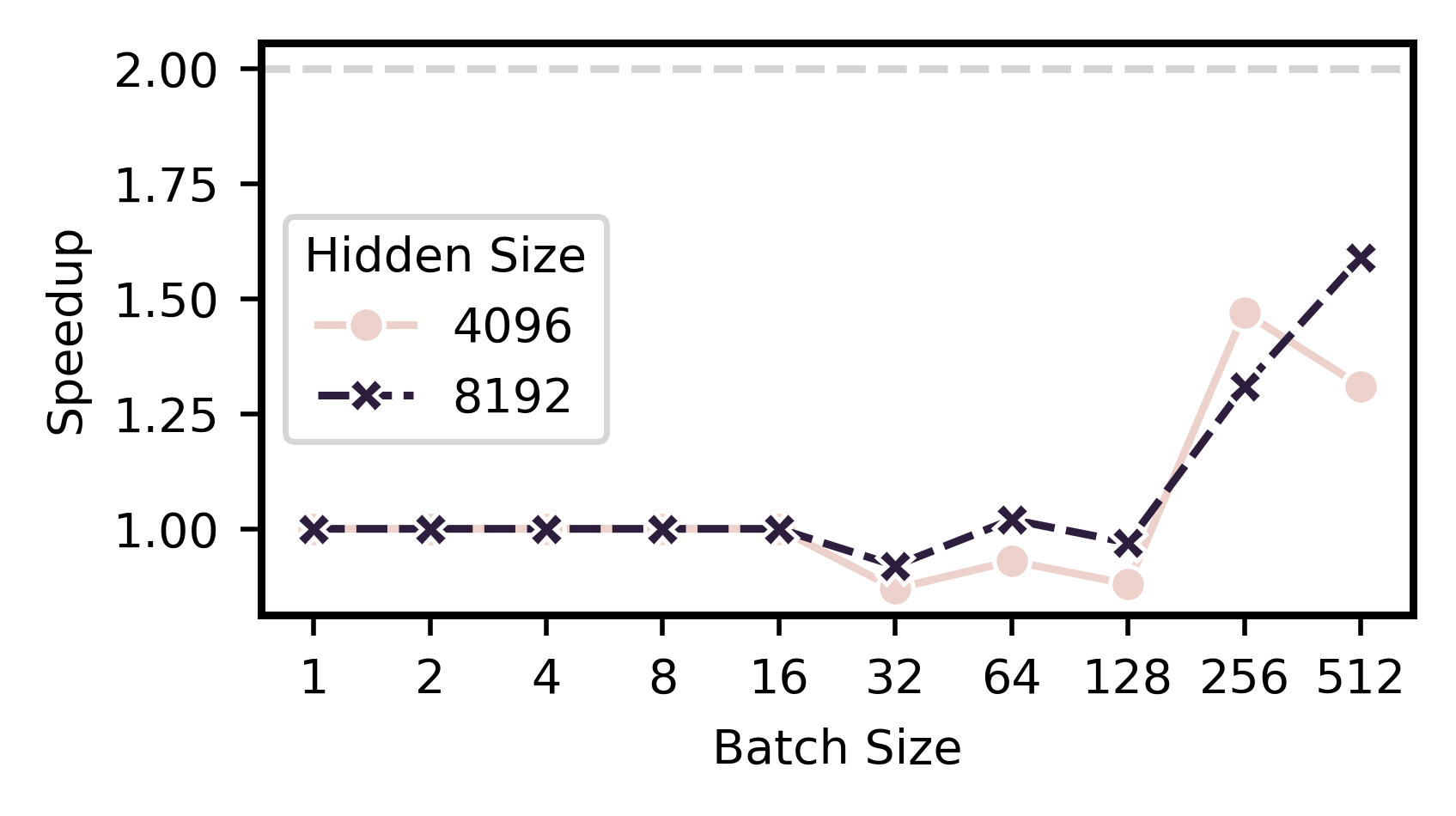
Figure 2: The speedup achieved through 2:4 pruning on matrix multiplication.
Challenges with Early Exit
Earlier approaches like early exit techniques suffer from limitations such as unfixed memory requirements, resource-intensive training, and inefficiencies in multi-batch settings. The inability to maintain consistent model performance without substantial dynamic skipping decisions poses significant challenges (Figure 3).
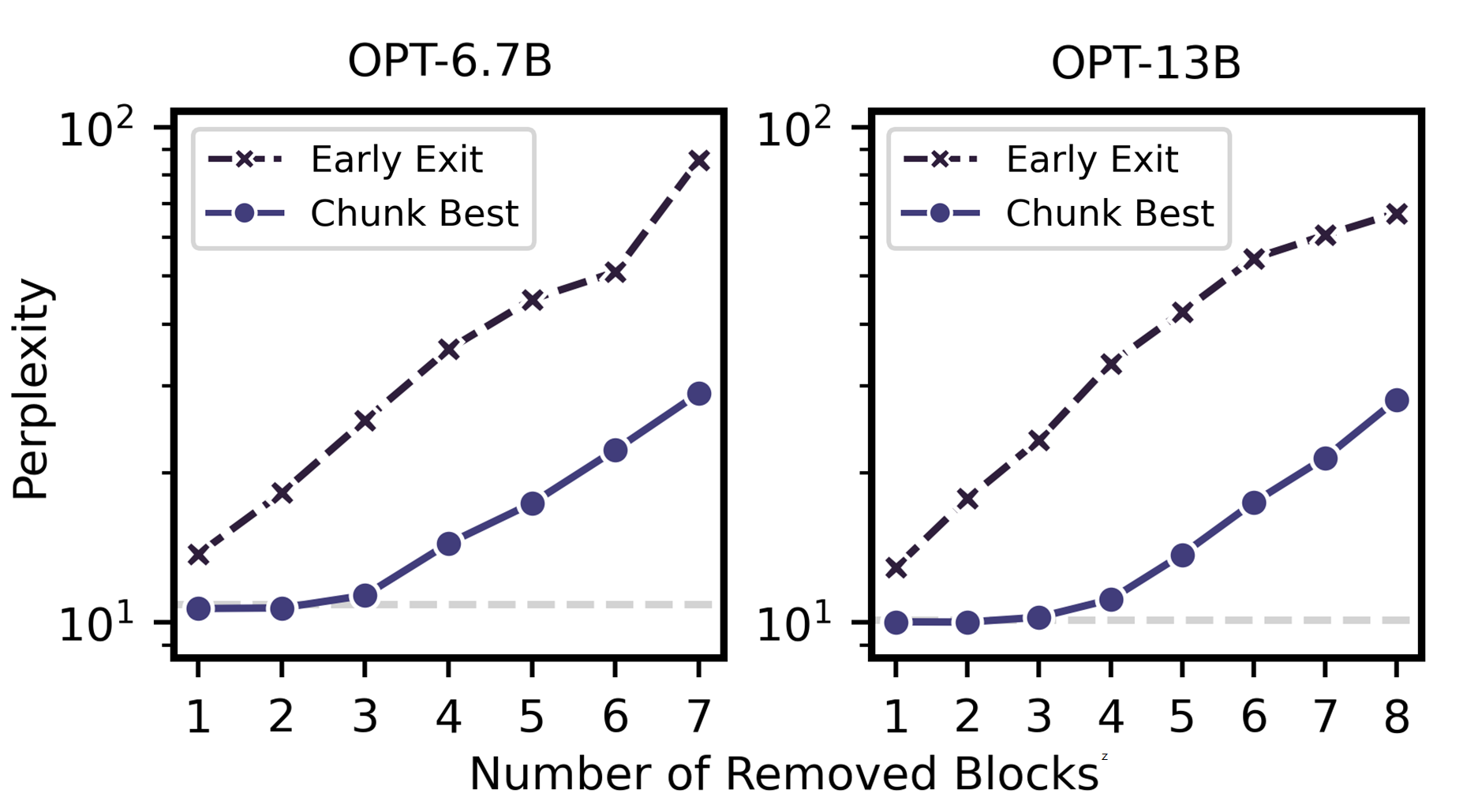
Figure 3: Perplexity comparison on WikiText-2 for LLMs after removing consecutive transformer blocks.
Proposed Approach: SLEB
Redundancy Verification
SLEB assesses redundancy by evaluating the cosine similarity across transformer block outputs, revealing high degrees of redundancy among neighboring blocks. Unlike early exit methods, SLEB's static approach does not rely on heuristic-based dynamic skipping, thus better preserving model integrity (Figure 4).
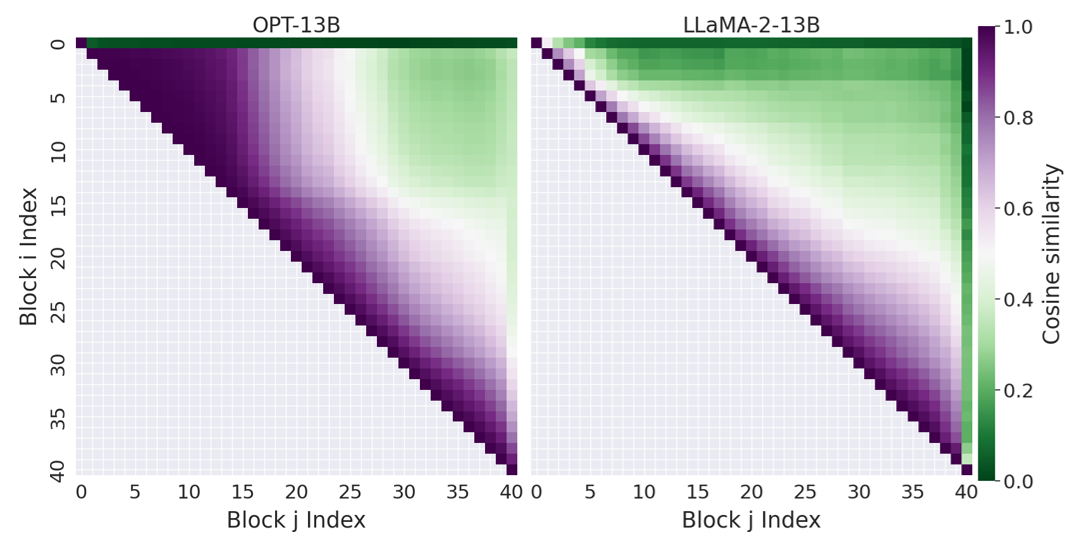
Figure 4: Cosine similarity between the outputs of two transformer blocks.
Implementation Details
SLEB removes redundant blocks iteratively, using a metric that minimizes impact on model perplexity. This metric considers the cumulative effect on transformer blocks, maintaining linguistic capabilities without additional training. The process iteratively identifies and prunes redundant blocks, allowing for significant end-to-end speed improvements.
Experimental Results
Language Modeling
SLEB's pruning achieved considerable performance retention across tested models, maintaining perplexity scores competitive with non-pruned baselines (Table 1). This indicates robustness at the transformer block level, effectively preserving language capabilities.
| Model |
Sparsity |
Perplexity (C4) |
| OPT-6.7B |
10% |
13.84 |
| OPT-13B |
20% |
12.54 |
| LLaMA-70B |
20% |
7.31 |
Table 1: Perplexity results on C4 dataset for models pruned with SLEB.
Deployment Speedup
SLEB consistently improved inference latency and throughput across various LLMs, demonstrating scalability and effectiveness in real-world deployment scenarios. It achieved superior speedups compared to state-of-the-art pruning methods, which often depend on case-specific matrix sizes and tensor hardware support.
Compatibility with Quantization
The approach also complements post-training quantization techniques like AWQ, enabling further compression while preserving linguistic nuances. This compatibility supports additional memory savings and speeding up of LLMs through 4-bit weight quantization.
Conclusion
SLEB presents a significant advance in LLM optimization by systematically identifying and removing redundant transformer blocks. By addressing the limitations of previous methods, SLEB enhances model deployment in practical settings, achieving increased inference speedup and reduced computational resource requirements without compromising the model's language understanding capabilities. The methodology holds promise for applications requiring efficient deployment of large-scale LLMs.

