Incoherent Probability Judgments in Large Language Models
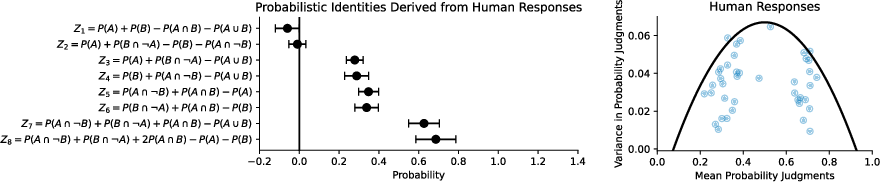
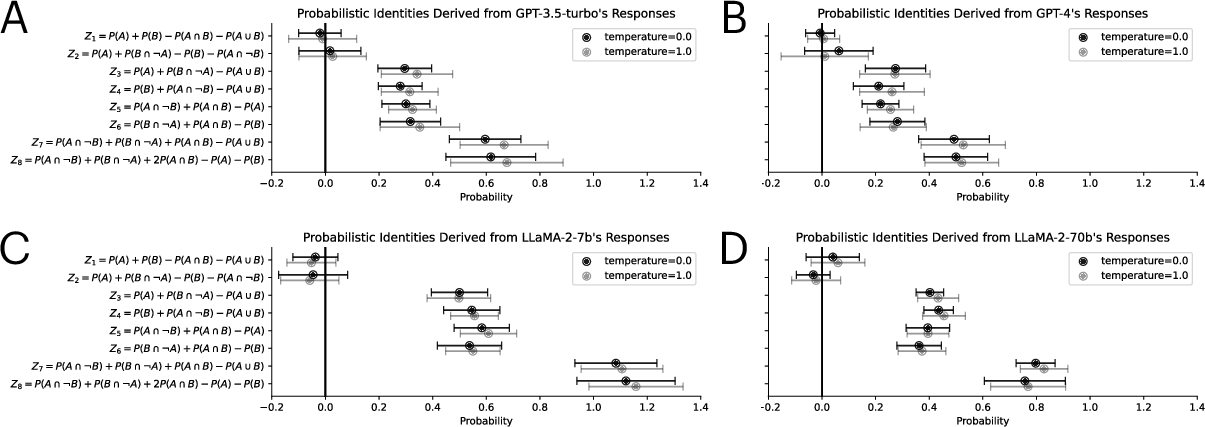
Abstract: Autoregressive LLMs trained for next-word prediction have demonstrated remarkable proficiency at producing coherent text. But are they equally adept at forming coherent probability judgments? We use probabilistic identities and repeated judgments to assess the coherence of probability judgments made by LLMs. Our results show that the judgments produced by these models are often incoherent, displaying human-like systematic deviations from the rules of probability theory. Moreover, when prompted to judge the same event, the mean-variance relationship of probability judgments produced by LLMs shows an inverted-U-shaped like that seen in humans. We propose that these deviations from rationality can be explained by linking autoregressive LLMs to implicit Bayesian inference and drawing parallels with the Bayesian Sampler model of human probability judgments.
- “GPT-4 Technical Report” In arXiv preprint arXiv:2303.08774, 2023
- “Using cognitive psychology to understand GPT-3” In Proceedings of the National Academy of Sciences 120.6 National Acad Sciences, 2023, pp. e2218523120
- “Sparks of artificial general intelligence: Early experiments with GPT-4” In arXiv preprint arXiv:2303.12712, 2023
- “Probabilistic biases meet the Bayesian brain” In Current Directions in Psychological Science 29.5 Sage Publications Sage CA: Los Angeles, CA, 2020, pp. 506–512
- “Surprisingly rational: probability theory plus noise explains biases in judgment.” In Psychological Review 121.3 American Psychological Association, 2014, pp. 463–480
- “Heuristic decision making” In Annual Review of Psychology 62 Annual Reviews, 2011, pp. 451–482
- “Bayes in the age of intelligent machines” In arXiv preprint arXiv:2311.10206, 2023
- John J Horton “Large language models as simulated economic agents: What can we learn from homo silicus?”, 2023
- “Calibrating predictive model estimates to support personalized medicine” In Journal of the American Medical Informatics Association 19.2 BMJ Group, 2012, pp. 263–274
- “Subjective probability: A judgment of representativeness” In Cognitive Psychology 3.3 Elsevier, 1972, pp. 430–454
- “Bruno: A deep recurrent model for exchangeable data” In Advances in Neural Information Processing Systems 31, 2018
- Ananya Kumar, Percy S Liang and Tengyu Ma “Verified uncertainty calibration” In Advances in Neural Information Processing Systems 32, 2019
- “An objective justification of Bayesianism I: Measuring inaccuracy” In Philosophy of Science 77.2 Cambridge University Press, 2010, pp. 201–235
- “Holistic evaluation of language models” In arXiv preprint arXiv:2211.09110, 2022
- “Testing different stochastic specificationsof risky choice” In Economica 65.260 Wiley Online Library, 1998, pp. 581–598
- “Embers of autoregression: Understanding large language models through the problem they are trained to solve” In arXiv preprint arXiv:2309.13638, 2023
- Joshua B Miller and Andrew Gelman “Laplace’s Theories of Cognitive Illusions, Heuristics and Biases” In Statistical Science 35.2, 2020, pp. 159–170
- “An experimental measurement of utility” In Journal of Political Economy 59.5 The University of Chicago Press, 1951, pp. 371–404
- “Language models are unsupervised multitask learners” In OpenAI blog 1.8, 2019, pp. 9
- Vaishnavi Shrivastava, Percy Liang and Ananya Kumar “Llamas Know What GPTs Don’t Show: Surrogate Models for Confidence Estimation” In arXiv preprint arXiv:2311.08877, 2023
- “A unified explanation of variability and bias in human probability judgments: How computational noise explains the mean–variance signature” In Journal of Experimental Psychology. General American Psychological Association (APA), 2023, pp. 2842–2860
- “Llama 2: Open foundation and fine-tuned chat models” In arXiv preprint arXiv:2307.09288, 2023
- “Attention is all you need” In Advances in Neural Information Processing systems 30, 2017
- “An explanation of in-context learning as implicit Bayesian inference” In arXiv preprint arXiv:2111.02080, 2021
- “Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers” In Icml 1, 2001, pp. 609–616
- “Deep de Finetti: Recovering Topic Distributions from Large Language Models” In arXiv preprint arXiv:2312.14226, 2023
- Jian-Qiao Zhu, Adam N Sanborn and Nick Chater “The Bayesian sampler: Generic Bayesian inference causes incoherence in human probability judgments.” In Psychological Review 127.5 American Psychological Association, 2020, pp. 719
- “Clarifying the relationship between coherence and accuracy in probability judgments” In Cognition 223 Elsevier, 2022, pp. 105022
- “The autocorrelated Bayesian sampler: A rational process for probability judgments, estimates, confidence intervals, choices, confidence judgments, and response times.” In Psychological Review American Psychological Association, 2023

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

