Unlearning Traces the Influential Training Data of Language Models
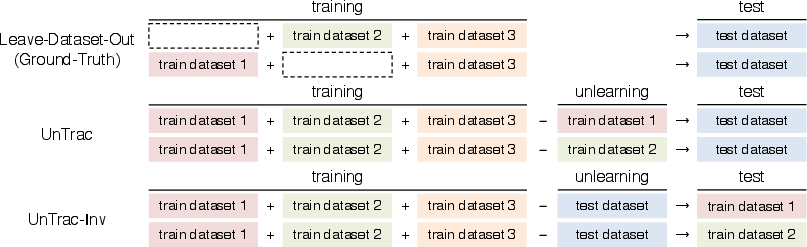
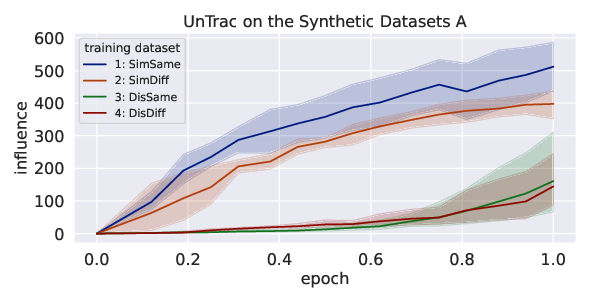
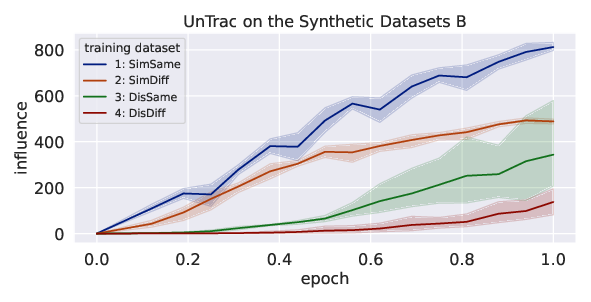
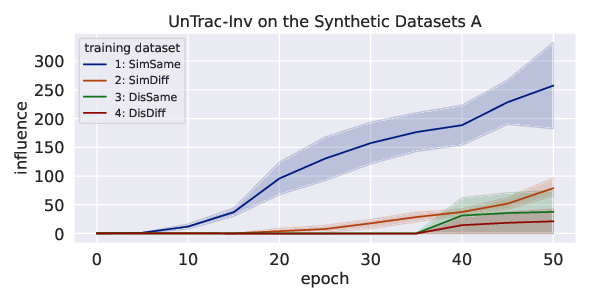
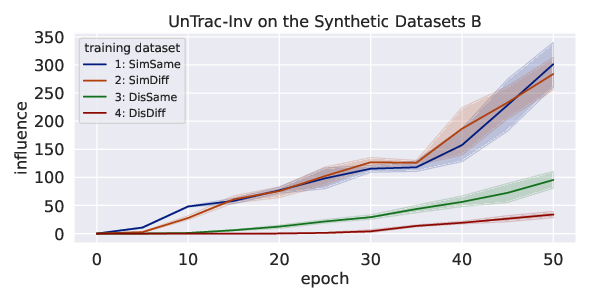
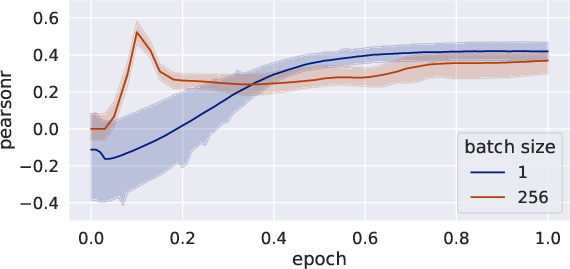
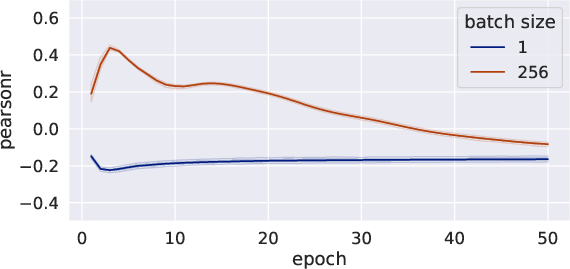
Abstract: Identifying the training datasets that influence a LLM's outputs is essential for minimizing the generation of harmful content and enhancing its performance. Ideally, we can measure the influence of each dataset by removing it from training; however, it is prohibitively expensive to retrain a model multiple times. This paper presents UnTrac: unlearning traces the influence of a training dataset on the model's performance. UnTrac is extremely simple; each training dataset is unlearned by gradient ascent, and we evaluate how much the model's predictions change after unlearning. Furthermore, we propose a more scalable approach, UnTrac-Inv, which unlearns a test dataset and evaluates the unlearned model on training datasets. UnTrac-Inv resembles UnTrac, while being efficient for massive training datasets. In the experiments, we examine if our methods can assess the influence of pretraining datasets on generating toxic, biased, and untruthful content. Our methods estimate their influence much more accurately than existing methods while requiring neither excessive memory space nor multiple checkpoints.
- Second-order stochastic optimization for machine learning in linear time. Journal of Machine Learning Research, 18(1):4148–4187.
- Relatif: Identifying explanatory training samples via relative influence. In International Conference on Artificial Intelligence and Statistics, pages 1899–1909. PMLR.
- Influence functions in deep learning are fragile. In International Conference on Learning Representations.
- On second-order group influence functions for black-box predictions. In Proceedings of the 37th International Conference on Machine Learning, pages 715–724. PMLR.
- Yinzhi Cao and Junfeng Yang. 2015. Towards making systems forget with machine unlearning. In IEEE Symposium on Security and Privacy, pages 463–480. IEEE.
- Jiaao Chen and Diyi Yang. 2023. Unlearn what you want to forget: Efficient unlearning for LLMs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12041–12052, Singapore. Association for Computational Linguistics.
- R Dennis Cook and Sanford Weisberg. 1982. Residuals and Influence in Regression. New York: Chapman and Hall.
- The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027.
- Making ai forget you: Data deletion in machine learning. Advances in neural information processing systems, 32.
- Eternal sunshine of the spotless net: Selective forgetting in deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9304–9312.
- Studying large language model generalization with influence functions. arXiv preprint arXiv:2308.03296.
- FastIF: Scalable influence functions for efficient model interpretation and debugging. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 10333–10350, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Adaptive machine unlearning. Advances in Neural Information Processing Systems, 34:16319–16330.
- Frank R Hampel. 1974. The influence curve and its role in robust estimation. Journal of the American Statistical Association, 69(346):383–393.
- Understanding in-context learning via supportive pretraining data. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12660–12673, Toronto, Canada. Association for Computational Linguistics.
- Xiaochuang Han and Yulia Tsvetkov. 2021. Influence tuning: Demoting spurious correlations via instance attribution and instance-driven updates. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4398–4409, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Explaining black box predictions and unveiling data artifacts through influence functions. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5553–5563, Online. Association for Computational Linguistics.
- ToxiGen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3309–3326, Dublin, Ireland. Association for Computational Linguistics.
- Knowledge unlearning for mitigating privacy risks in language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14389–14408, Toronto, Canada. Association for Computational Linguistics.
- Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980v9.
- Pang Wei Koh and Percy Liang. 2017. Understanding black-box predictions via influence functions. In Proceedings of the 34th International Conference on Machine Learning, pages 1885–1894. PMLR.
- On the accuracy of influence functions for measuring group effects. Advances in Neural Information Processing Systems, 32.
- The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland. Association for Computational Linguistics.
- Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Deep unlearning via randomized conditionally independent hessians. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10422–10431.
- Estimating training data influence by tracing gradient descent. Advances in Neural Information Processing Systems, 33:19920–19930.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- Theoretical and practical perspectives on what influence functions do. Advances in Neural Information Processing Systems.
- Scaling up influence functions. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 8179–8186.
- Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems, 34:18075–18086.
- Noam Shazeer and Mitchell Stern. 2018. Adafactor: Adaptive learning rates with sublinear memory cost. In Proceedings of the 35th International Conference on Machine Learning, pages 4596–4604. PMLR.
- Anders Søgaard. 2021. Revisiting methods for finding influential examples. arXiv preprint arXiv:2111.04683.
- Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2):26–31.
- Trieu H Trinh and Quoc V Le. 2018. A simple method for commonsense reasoning. arXiv preprint arXiv:1806.02847.
- Towards understanding chain-of-thought prompting: An empirical study of what matters. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2717–2739, Toronto, Canada. Association for Computational Linguistics.
- KGA: A general machine unlearning framework based on knowledge gap alignment. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13264–13276, Toronto, Canada. Association for Computational Linguistics.
- How many and which training points would need to be removed to flip this prediction? In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2571–2584, Dubrovnik, Croatia. Association for Computational Linguistics.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
- Gender bias in coreference resolution: Evaluation and debiasing methods. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 15–20, New Orleans, Louisiana. Association for Computational Linguistics.
- Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision, pages 19–27.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.