Can AI Assistants Know What They Don't Know?
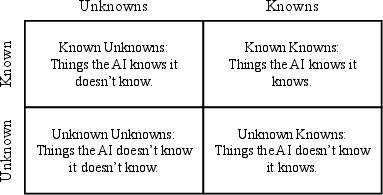
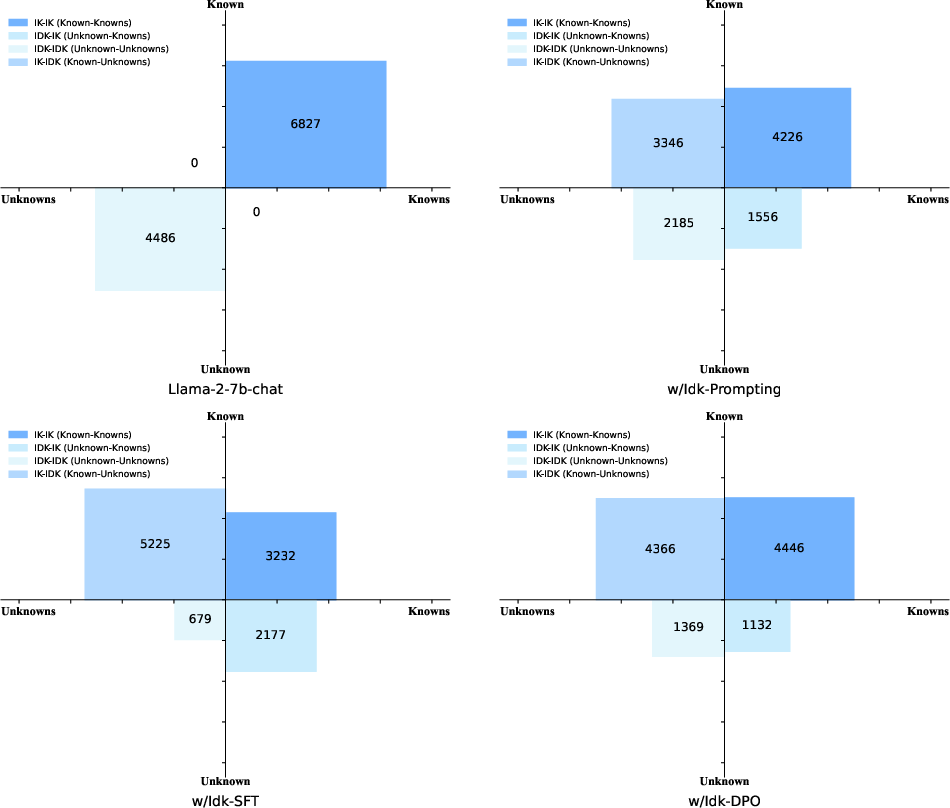
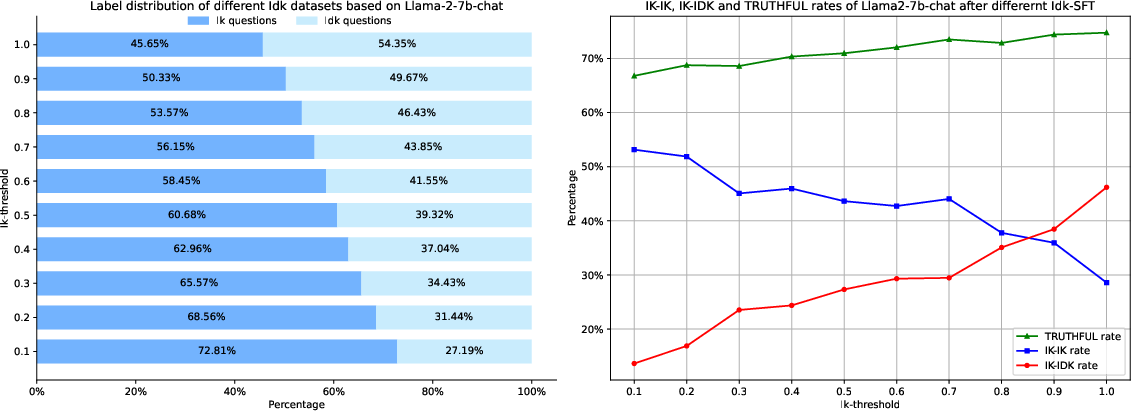
Abstract: Recently, AI assistants based on LLMs show surprising performance in many tasks, such as dialogue, solving math problems, writing code, and using tools. Although LLMs possess intensive world knowledge, they still make factual errors when facing some knowledge intensive tasks, like open-domain question answering. These untruthful responses from the AI assistant may cause significant risks in practical applications. We believe that an AI assistant's refusal to answer questions it does not know is a crucial method for reducing hallucinations and making the assistant truthful. Therefore, in this paper, we ask the question "Can AI assistants know what they don't know and express them through natural language?" To answer this question, we construct a model-specific "I don't know" (Idk) dataset for an assistant, which contains its known and unknown questions, based on existing open-domain question answering datasets. Then we align the assistant with its corresponding Idk dataset and observe whether it can refuse to answer its unknown questions after alignment. Experimental results show that after alignment with Idk datasets, the assistant can refuse to answer most its unknown questions. For questions they attempt to answer, the accuracy is significantly higher than before the alignment.
- Anonymous. INSIDE: LLMs’ internal states retain the power of hallucination detection. In Submitted to The Twelfth International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Zj12nzlQbz. under review.
- Anthropic. Introducing claude, 2023. URL https://www.anthropic.com/index/introducing-claude.
- Self-rag: Learning to retrieve, generate, and critique through self-reflection. CoRR, abs/2310.11511, 2023. doi: 10.48550/ARXIV.2310.11511. URL https://doi.org/10.48550/arXiv.2310.11511.
- A general language assistant as a laboratory for alignment. CoRR, abs/2112.00861, 2021. URL https://arxiv.org/abs/2112.00861.
- Training a helpful and harmless assistant with reinforcement learning from human feedback. CoRR, abs/2204.05862, 2022. doi: 10.48550/ARXIV.2204.05862. URL https://doi.org/10.48550/arXiv.2204.05862.
- Baichuan. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305, 2023. URL https://arxiv.org/abs/2309.10305.
- Language models are few-shot learners. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
- Discovering latent knowledge in language models without supervision. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=ETKGuby0hcs.
- Evaluating hallucinations in chinese large language models. CoRR, abs/2310.03368, 2023. doi: 10.48550/ARXIV.2310.03368. URL https://doi.org/10.48550/arXiv.2310.03368.
- Palm: Scaling language modeling with pathways. J. Mach. Learn. Res., 24:240:1–240:113, 2023. URL http://jmlr.org/papers/v24/22-1144.html.
- Deep reinforcement learning from human preferences. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 4299–4307, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html.
- Dola: Decoding by contrasting layers improves factuality in large language models. CoRR, abs/2309.03883, 2023. doi: 10.48550/ARXIV.2309.03883. URL https://doi.org/10.48550/arXiv.2309.03883.
- Scaling instruction-finetuned language models. CoRR, abs/2210.11416, 2022. doi: 10.48550/ARXIV.2210.11416. URL https://doi.org/10.48550/arXiv.2210.11416.
- Truthful AI: developing and governing AI that does not lie. CoRR, abs/2110.06674, 2021. URL https://arxiv.org/abs/2110.06674.
- Mistral 7b. CoRR, abs/2310.06825, 2023. doi: 10.48550/ARXIV.2310.06825. URL https://doi.org/10.48550/arXiv.2310.06825.
- Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min-Yen Kan (eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pp. 1601–1611. Association for Computational Linguistics, 2017. doi: 10.18653/V1/P17-1147. URL https://doi.org/10.18653/v1/P17-1147.
- Language models (mostly) know what they know. CoRR, abs/2207.05221, 2022. doi: 10.48550/ARXIV.2207.05221. URL https://doi.org/10.48550/arXiv.2207.05221.
- Natural questions: a benchmark for question answering research. Trans. Assoc. Comput. Linguistics, 7:452–466, 2019. doi: 10.1162/TACL_A_00276. URL https://doi.org/10.1162/tacl_a_00276.
- Inference-time intervention: Eliciting truthful answers from a language model. CoRR, abs/2306.03341, 2023. doi: 10.48550/ARXIV.2306.03341. URL https://doi.org/10.48550/arXiv.2306.03341.
- Truthfulqa: Measuring how models mimic human falsehoods. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pp. 3214–3252. Association for Computational Linguistics, 2022a. doi: 10.18653/v1/2022.acl-long.229. URL https://doi.org/10.18653/v1/2022.acl-long.229.
- Teaching models to express their uncertainty in words. Trans. Mach. Learn. Res., 2022, 2022b. URL https://openreview.net/forum?id=8s8K2UZGTZ.
- The flan collection: Designing data and methods for effective instruction tuning, 2023.
- Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pp. 9004–9017. Association for Computational Linguistics, 2023. URL https://aclanthology.org/2023.emnlp-main.557.
- OpenAI. Introducing chatgpt, 2022. URL https://openai.com/blog/chatgpt.
- Training language models to follow instructions with human feedback. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.
- Qwen-Team. Qwen technical report. 2023. URL https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf.
- Direct preference optimization: Your language model is secretly a reward model. CoRR, abs/2305.18290, 2023. doi: 10.48550/ARXIV.2305.18290. URL https://doi.org/10.48550/arXiv.2305.18290.
- Investigating the factual knowledge boundary of large language models with retrieval augmentation. CoRR, abs/2307.11019, 2023. doi: 10.48550/ARXIV.2307.11019. URL https://doi.org/10.48550/arXiv.2307.11019.
- Multitask prompted training enables zero-shot task generalization. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=9Vrb9D0WI4.
- Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017. URL http://arxiv.org/abs/1707.06347.
- Retrieval augmentation reduces hallucination in conversation. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 16-20 November, 2021, pp. 3784–3803. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.findings-emnlp.320. URL https://doi.org/10.18653/v1/2021.findings-emnlp.320.
- Learning to summarize from human feedback. CoRR, abs/2009.01325, 2020. URL https://arxiv.org/abs/2009.01325.
- Moss: Training conversational language models from synthetic data. 2023.
- Fine-tuning language models for factuality. CoRR, abs/2311.08401, 2023. doi: 10.48550/ARXIV.2311.08401. URL https://doi.org/10.48550/arXiv.2311.08401.
- Llama: Open and efficient foundation language models. CoRR, abs/2302.13971, 2023. doi: 10.48550/arXiv.2302.13971. URL https://doi.org/10.48550/arXiv.2302.13971.
- Evaluating open-qa evaluation, 2023a. URL https://arxiv.org/abs/2305.12421.
- Survey on factuality in large language models: Knowledge, retrieval and domain-specificity. CoRR, abs/2310.07521, 2023b. doi: 10.48550/ARXIV.2310.07521. URL https://doi.org/10.48550/arXiv.2310.07521.
- Self-instruct: Aligning language models with self-generated instructions. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 13484–13508. Association for Computational Linguistics, 2023c. doi: 10.18653/V1/2023.ACL-LONG.754. URL https://doi.org/10.18653/v1/2023.acl-long.754.
- Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022a. URL https://openreview.net/forum?id=gEZrGCozdqR.
- Emergent abilities of large language models. Trans. Mach. Learn. Res., 2022, 2022b. URL https://openreview.net/forum?id=yzkSU5zdwD.
- ALCUNA: large language models meet new knowledge. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pp. 1397–1414. Association for Computational Linguistics, 2023a. URL https://aclanthology.org/2023.emnlp-main.87.
- Do large language models know what they don’t know? In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 8653–8665. Association for Computational Linguistics, 2023b. doi: 10.18653/v1/2023.findings-acl.551. URL https://doi.org/10.18653/v1/2023.findings-acl.551.
- GLM-130B: an open bilingual pre-trained model. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=-Aw0rrrPUF.
- The wisdom of hindsight makes language models better instruction followers. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 41414–41428. PMLR, 2023a. URL https://proceedings.mlr.press/v202/zhang23ab.html.
- Siren’s song in the AI ocean: A survey on hallucination in large language models. CoRR, abs/2309.01219, 2023b. doi: 10.48550/ARXIV.2309.01219. URL https://doi.org/10.48550/arXiv.2309.01219.
- Knowing what llms DO NOT know: A simple yet effective self-detection method. CoRR, abs/2310.17918, 2023. doi: 10.48550/ARXIV.2310.17918. URL https://doi.org/10.48550/arXiv.2310.17918.
- Representation engineering: A top-down approach to AI transparency. CoRR, abs/2310.01405, 2023. doi: 10.48550/ARXIV.2310.01405. URL https://doi.org/10.48550/arXiv.2310.01405.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.