- The paper introduces a tiling strategy that divides attention computation into intra-block and inter-block operations to achieve linear complexity.
- It demonstrates that by optimizing GPU memory transfers, training speed stays constant as sequence length increases while reducing memory usage.
- Experimental results with TransNormerLLM show that Lightning Attention-2 outperforms previous methods like FlashAttention-2 in speed and efficiency.
Lightning Attention-2: Enabling Unlimited Sequence Lengths in LLMs
The paper "Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in LLMs" (2401.04658) introduces Lightning Attention-2, an efficient attention mechanism designed to address the computational challenges posed by long sequences in LLMs. By leveraging a tiling strategy and separating intra-block and inter-block computations, Lightning Attention-2 achieves linear complexity, theoretically enabling the processing of unlimited sequence lengths while maintaining constant training speed and memory consumption.
Addressing the Limitations of Linear Attention
While linear attention mechanisms offer a promising alternative to traditional softmax attention with their ability to process tokens in linear computational complexities, realizing their theoretical advantages in practice has been difficult. The primary obstacle lies in the cumulative summation (cumsum) required by linear attention kernels in causal settings, hindering the achievement of theoretical training speeds. Lightning Attention-2 addresses this issue by employing a "divide and conquer" strategy.
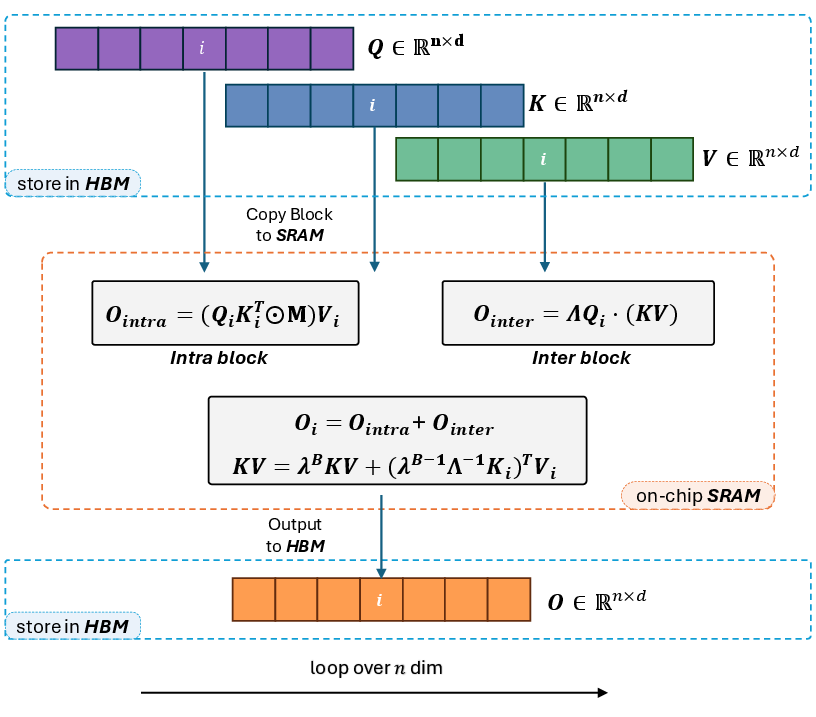
Figure 1: Structural framework of Lightning Attention-2 detailing the algorithmic schematic with tiling blocks of matrices being transferred from HBM to SRAM.
Specifically, the attention calculation is divided into intra-block and inter-block components. Intra-blocks utilize conventional attention computation for QKV products, while inter-blocks leverage linear attention kernel tricks. Tiling techniques are applied in both forward and backward procedures to optimize GPU hardware utilization. This approach enables Lightning Attention-2 to train LLMs with unlimited sequence lengths without incurring additional costs, maintaining constant computational speed with increasing sequence length under fixed memory consumption.
Algorithmic Implementation and Optimization
The core innovation of Lightning Attention-2 lies in its tiling methodology, which strategically leverages the memory bandwidth differences between HBM and SRAM within GPUs. During each iteration, the input matrices Qi,Ki,Vi are segmented into blocks and transferred to SRAM for computation. The intra- and inter-block operations are then processed separately, with intra-blocks using left product and inter-blocks using right product. This optimizes the computational and memory efficiencies associated with right product, enhancing overall execution speed. The intermediate activation KV is iteratively saved and accumulated within SRAM. Finally, the outputs of intra-blocks and inter-blocks are summed within SRAM, and the results are written back to HBM.
The forward pass of Lightning Attention-2 can be expressed as:
Ot+1=[(Qt+1Kt+1⊤)⊙M]Vt+1+ΛQt+1(KVt)
where M is a mask and Λ is a diagonal matrix containing decay rates.
The backward pass involves a reverse process with similar tiling and separation of intra- and inter-block computations.
Experimental Evaluation and Results
The authors conducted comprehensive experiments to evaluate the performance, speed, and memory utilization of Lightning Attention-2. They integrated it into the TransNormerLLM model and utilized the Metaseq framework. The experiments were performed on a GPU cluster featuring 128 A100 80G GPUs.
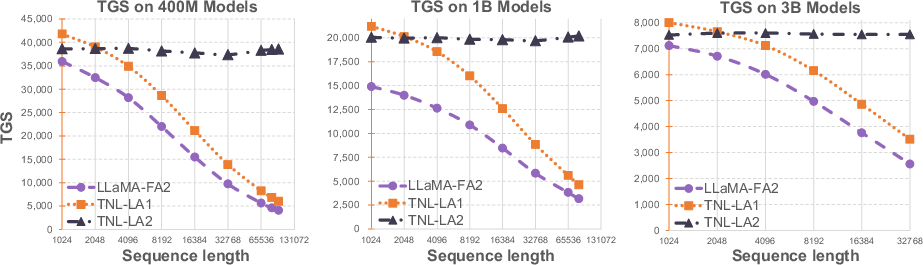
Figure 2: Comparative illustration of training speed, Token per GPU per Second (TGS) for LLaMA with FlashAttention-2, TransNormerLLM with Lightning Attention-1 and TransNormerLLM with Lightning Attention-2.
The results demonstrate that Lightning Attention-2 achieves superior computational speed and reduced memory footprint compared to FlashAttention-2 and Lightning Attention-1. As shown in Figure 2, Lightning Attention-2 maintains a consistent training speed regardless of input sequence length, while other attention mechanisms experience a significant decline in performance as sequence length increases.
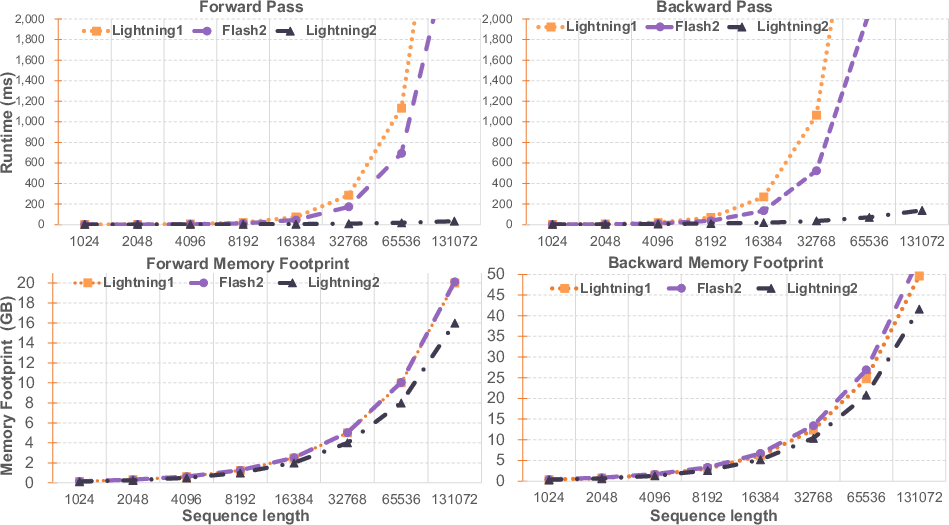
Figure 3: Comparative Analysis of Speed and Memory Usage, showing runtime in milliseconds and memory utilization for forward and backward passes.
Furthermore, Figure 3 illustrates the runtime for forward and backward propagation, demonstrating that Lightning Attention-2 exhibits linear growth, in contrast to the quadratic growth of baseline methods. The language modeling performance of TransNormerLLM-0.4B with Lightning Attention-2 was also evaluated, revealing a marginal performance difference compared to Lightning Attention-1.
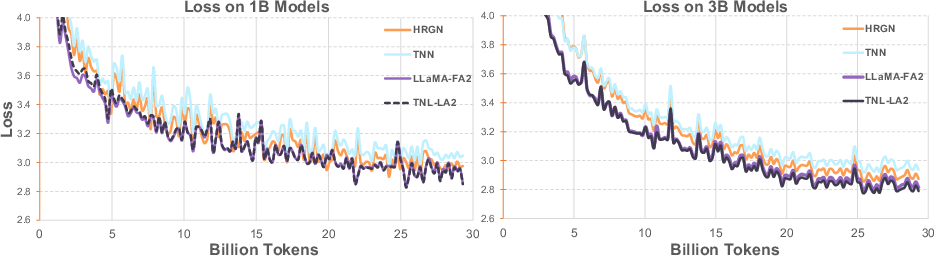
Figure 4: Performance Comparison of HGRN, TNN, LLaMA with FlashAttention2 and TransNormerLLM with Lightning Attention-2.
Additionally, the TNL-LA2 model achieved marginally lower loss compared to other models under review in both 1B and 3B parameters, as shown in Figure 4.
Implications and Future Directions
Lightning Attention-2 represents a significant advancement in managing long sequences in LLMs. The findings suggest that Lightning Attention-2 offers a significant advancement in managing unlimited sequence lengths in LLMs. It allows for training LLMs from scratch with long sequence lengths without additional cost. Its ability to maintain consistent training speeds and reduce memory footprint has profound implications for various applications requiring the processing of long sequences. The authors plan to introduce sequence parallelism in conjunction with Lightning Attention-2, further improving the ability to train on extremely long sequences.
Conclusion
The introduction of Lightning Attention-2 offers a practical solution for handling unlimited sequence lengths in LLMs. By addressing the limitations of existing linear attention algorithms, Lightning Attention-2 paves the way for more efficient and scalable LLMs, particularly in applications that demand the processing of extensive textual data. This work contributes to the ongoing efforts to enhance the efficiency and scalability of LLMs, pushing the boundaries of what is computationally feasible.