- The paper introduces the CALM framework that composes LLMs with specialized models using cross-attention to extend capabilities.
- It demonstrates enhanced performance with 84.3% accuracy in key-value arithmetic and improved translation in 175 languages without modifying base models.
- Ablation studies confirm that CALM outperforms standard routing and fine-tuning methods, ensuring scalable, multi-domain enhancements.
LLM Augmented LLMs: Expanding Capabilities through Composition
Introduction to CALM Framework
The paper "LLM Augmented LLMs: Expanding Capabilities through Composition" introduces an innovative framework named Composition to Augment LLMs (CALM). The framework addresses the challenge of efficiently and practically enhancing pre-existing LLMs by composing them with more specialized models. It leverages cross-attention mechanisms to amalgamate and extend capabilities without the need for retraining or altering the foundational models' weights.
In essence, CALM allows for the reuse of established LLMs, incorporating additional layers of expertise provided by domain-specific augmenting models.
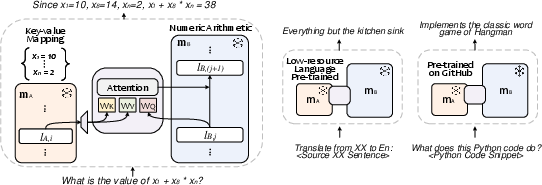
Figure 1: Overview of CALM, illustrating composition with specialized models across different domains.
Methodology
Model Setup
The CALM framework introduces cross-attention between layers of the anchor and augmenting models to facilitate representation composition. Given two models, an anchor model A and an augmenting model B, the framework keeps the weights of these models unchanged, adding only a minimal set of learnable parameters. The layers chosen for composition from both models are processed through the CALM's projection and cross-attention functions.
- Projection Layers: These layers map the output dimensions of the augmenting model to match those of the anchor model to enable attentional interactions.
- Cross-attention Mechanisms: Cross-attention layers enable the models to utilize each other's representation by attending over selected layer outputs.
The resulting composed model utilizes these mechanisms to create a joint task model that preserves and extends the capabilities of the foundational LLM while incorporating domain-specific knowledge.
Training Considerations
Training CALM involves a small amount of data reflecting the combined skills of both models—for instance, examples that require both language understanding and code execution capabilities. Importantly, the composition preserves base model strengths while introducing new task competencies without catastrophic forgetting.
Experimental Evaluation
The efficacy of CALM is demonstrated across three distinct domains:
- Key-Value Arithmetic: An anchor model capable of arithmetic is composed with a model trained to memorize key-value pairs. CALM enables solving arithmetic expressions using keys, showing an impressive 84.3% accuracy, surpassing isolated capabilities of the base models.
- Language Inclusivity: By combining an LLM pretrained on high-resource languages with a model focused on low-resource languages, CALM significantly boosts translation performance, achieving better results in 175 out of 192 languages tested.
- Code Understanding and Generation: A domain-specific code model is composed with an LLM, enhancing tasks like code completion and explanation, showing increased performance in multiple benchmarks.
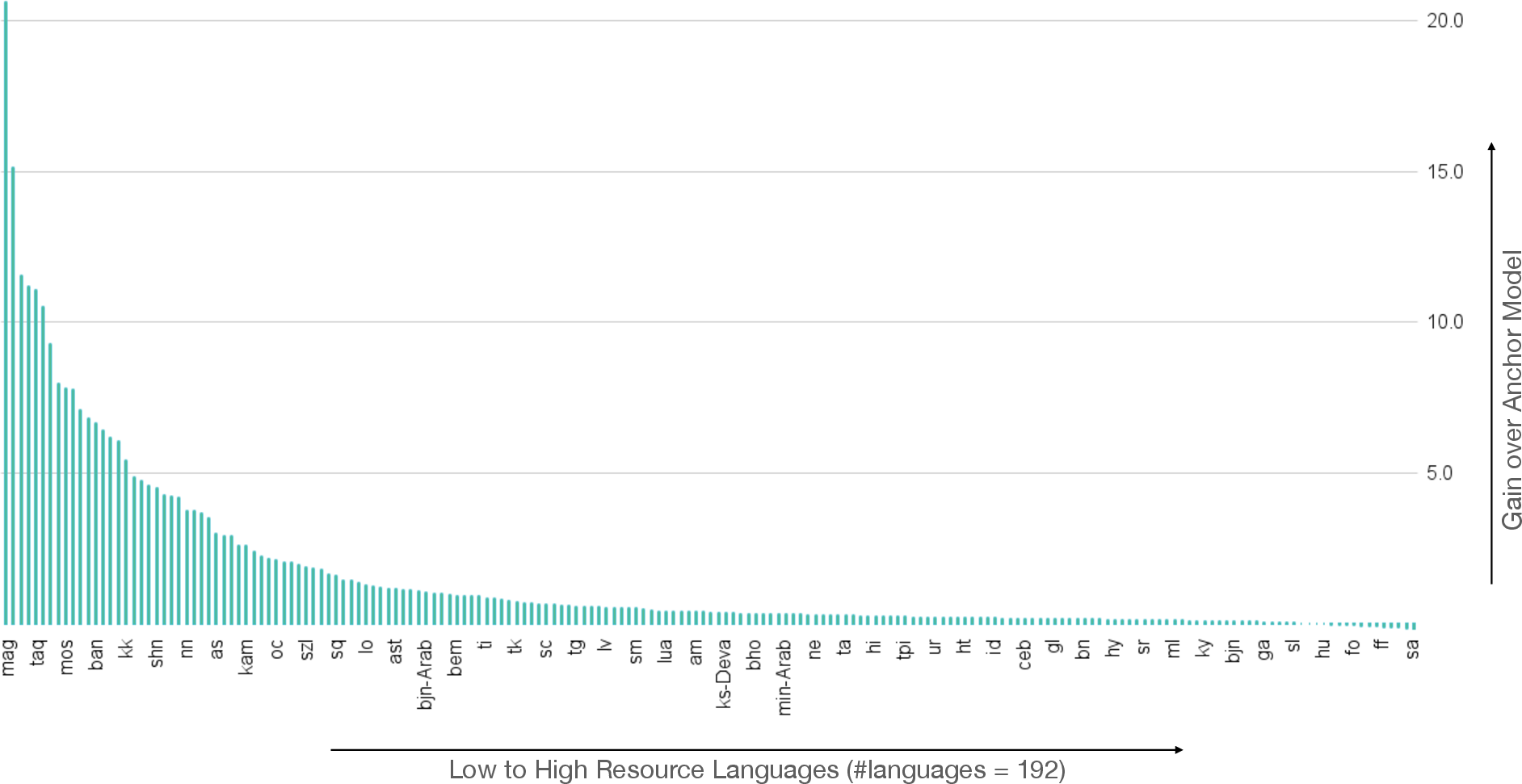
Figure 2: Gains seen by the composed model across various tasks.
Ablation Studies
Ablation studies confirm the effectiveness of CALM over other architectures like standard model routing and parameter-efficient fine-tuning (e.g., LoRA). The procedure of maintaining both base models unchanged while adding compositional capabilities demonstrates superior performance across all tested scenarios. The study highlighted the supplementary benefits in domains where model memorization and reasoning are required synergistically.
Practical Implications and Future Directions
CALM presents a compelling approach to expand LLM capabilities efficiently and economically. The framework's modular nature allows for seamless integration of multiple augmenting models, paving the way for multi-domain intelligence without compromising existing model faculties. Future work may explore the composition of several augmenting models to enrich foundational LLM capabilities further.
In summary, CALM offers a paradigm wherein existing LLMs can be augmented to tackle new tasks, maximizing utility and performance with minimal computational overhead. This facilitates adaptive and scalable AI solutions capable of leveraging domain-specific expertise on top of generalized skills encapsulated in LLMs.

