LM-Cocktail: Resilient Tuning of Language Models via Model Merging
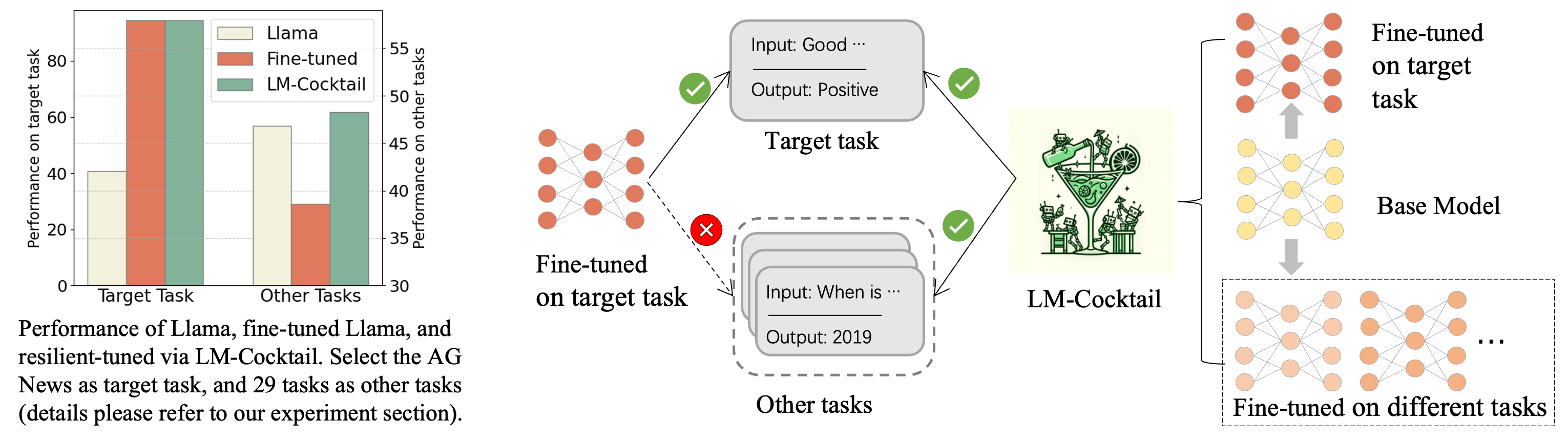
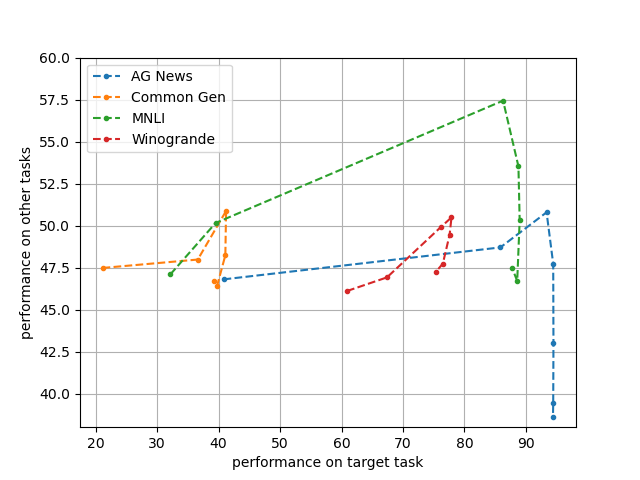
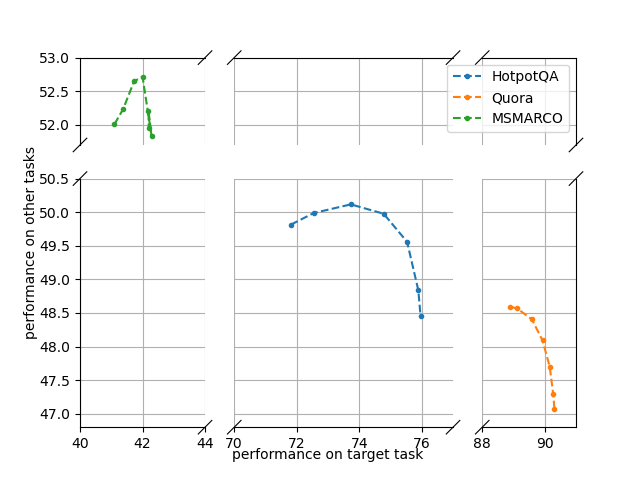
Abstract: The pre-trained LLMs are continually fine-tuned to better support downstream applications. However, this operation may result in significant performance degeneration on general tasks beyond the targeted domain. To overcome this problem, we propose LM-Cocktail which enables the fine-tuned model to stay resilient in general perspectives. Our method is conducted in the form of model merging, where the fine-tuned LLM is merged with the pre-trained base model or the peer models from other domains through weighted average. Despite simplicity, LM-Cocktail is surprisingly effective: the resulted model is able to achieve a strong empirical performance in the whole scope of general tasks while preserving a superior capacity in its targeted domain. We conduct comprehensive experiments with LLama and BGE model on popular benchmarks, including FLAN, MMLU, MTEB, whose results validate the efficacy of our proposed method. The code and checkpoints are available at https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Recall and learn: Fine-tuning deep pretrained language models with less forgetting. arXiv preprint arXiv:2004.12651.
- Uprise: Universal prompt retrieval for improving zero-shot evaluation.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv preprint arXiv:2002.06305.
- An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211.
- The elements of statistical learning: data mining, inference, and prediction, volume 2. Springer.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
- Lorahub: Efficient cross-task generalization via dynamic lora composition.
- Editing models with task arithmetic. arXiv preprint arXiv:2212.04089.
- Patching open-vocabulary models by interpolating weights. In Advances in Neural Information Processing Systems.
- Dataless knowledge fusion by merging weights of language models. arXiv preprint arXiv:2212.09849.
- Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526.
- Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30.
- Zhizhong Li and Derek Hoiem. 2017. Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947.
- Versatile black-box optimization. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference, pages 620–628.
- Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747.
- Michael S Matena and Colin Raffel. 2022. Merging models with fisher-weighted averaging. In Advances in Neural Information Processing Systems.
- Mteb: Massive text embedding benchmark. arXiv preprint arXiv:2210.07316.
- Model fusion of heterogeneous neural networks via cross-layer alignment. arXiv preprint arXiv:2110.15538.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift. Advances in neural information processing systems, 32.
- What to pre-train on? efficient intermediate task selection. arXiv preprint arXiv:2104.08247.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
- Encoder based lifelong learning. In Proceedings of the IEEE international conference on computer vision, pages 1320–1328.
- icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010.
- Experience replay for continual learning. Advances in Neural Information Processing Systems, 32.
- Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Continual learning with deep generative replay. Advances in neural information processing systems, 30.
- Large language models encode clinical knowledge. arXiv preprint arXiv:2212.13138.
- Multitask pre-training of modular prompt for chinese few-shot learning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11156–11172.
- Overcoming catastrophic forgetting during domain adaptation of neural machine translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2062–2068.
- Llama 2: Open foundation and fine-tuned chat models.
- Spot: Better frozen model adaptation through soft prompt transfer. arXiv preprint arXiv:2110.07904.
- Learning to retrieve in-context examples for large language models.
- Finetuned language models are zero-shot learners. In International Conference on Learning Representations.
- Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
- Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 23965–23998. PMLR.
- Robust fine-tuning of zero-shot models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7959–7971.
- pi-tuning: Transferring multimodal foundation models with optimal multi-task interpolation. In International Conference on Machine Learning, pages 37713–37727. PMLR.
- C-pack: Packaged resources to advance general chinese embedding.
- Resolving interference when merging models. arXiv preprint arXiv:2306.01708.
- Language models are super mario: Absorbing abilities from homologous models as a free lunch. arXiv preprint arXiv:2311.03099.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

