- The paper presents Punica, which introduces a novel CUDA kernel (SGMV) to concurrently serve multiple LoRA models, significantly enhancing GPU resource utilization.
- The paper employs dynamic scheduling and batching strategies to balance throughput with latency, achieving up to 12x performance improvements over traditional systems.
- The paper demonstrates that sharing backbone model weights across LoRA models reduces memory usage and computational overhead, paving the way for scalable AI deployments.
Overview of "Punica: Multi-Tenant LoRA Serving"
The paper "Punica: Multi-Tenant LoRA Serving" introduces a sophisticated system aimed at optimizing the serving of multiple Low-Rank Adaptation (LoRA) models on a shared GPU cluster. LoRA significantly reduces the trainable parameters needed to adapt pre-trained LLMs to specific domains. Punica leverages efficient CUDA kernel designs and scheduling strategies to maximize GPU resource utilization and throughput, especially in multi-tenant environments.
LoRA and Its Significance
Low-Rank Adaptation allows ML providers to efficiently fine-tune LLMs with minimal computational resources by exploiting the low-rank nature of weight differences between pre-trained and fine-tuned models. Despite offering substantial reductions in training overhead and memory consumption, the simultaneous serving of multiple LoRA models can be resource-intensive when treated as isolated entities. Pivotal to Punica's design is its ability to share the backbone model weights across different LoRA models, thereby enhancing computation and memory efficiency.
System Architecture and Design
Punica operates by consolidating multiple LoRA models within a shared infrastructure, reducing redundant memory usage and computational overhead by batching GPU operations. Its architecture leverages a new CUDA kernel, Segmented Gather Matrix-Vector Multiplication (SGMV), enabling efficient parallel computation of multiple LoRA models in a batched manner.
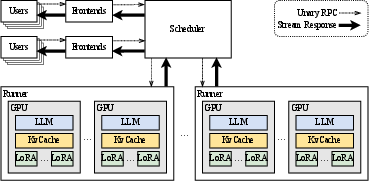
Figure 1: The system architecture of Punica.
Segmented Gather Matrix-Vector Multiplication (SGMV)
SGMV is the core innovation introduced by Punica, allowing for batched execution of various LoRA model requests, thus maximizing operational intensity and GPU utilization:
- SGMV-expand: Expands low-rank input features to high-dimensional outputs.
- SGMV-shrink: Shrinks high-dimensional input features to low-rank outputs.
Through the strategic grouping of inputs by model demands, Punica efficiently harnesses GPU capabilities to execute diverse LoRA-based operations concurrently.
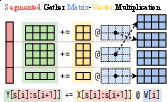
Figure 2: Semantics of SGMV.
Scheduling and Scalability
Punica employs a dynamic scheduling approach, prioritizing GPUs with higher workloads, effectively balancing throughput with latency. It strategically migrates requests to optimize resource allocation without compromising performance, enabling scalability and adaptability to fluctuating workloads. This is particularly crucial in cloud-based environments where resource allocation must be dynamically managed based on demand.
Punica significantly surpasses existing LLM serving systems in throughput, demonstrating up to 12x higher performance in multi-LoRA model settings while maintaining minimal latency penalties.
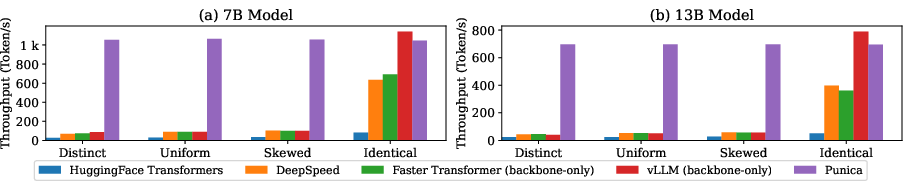
Figure 3: Single GPU text generation comparison.
Punica exhibits remarkable scalability when deployed across multiple GPUs, optimizing both memory usage and processing speed, which is critical for high-demand AI applications requiring real-time processing.
Implications and Future Directions
The implications of Punica's design are profound, enabling more efficient serving of specialized LoRA models in a multi-tenant architecture while reducing overall GPU resource demands. Future advancements may explore further optimizations in KvCache handling and potentially extend Punica's design to encompass broader sets of adaptation frameworks beyond LoRA, further enhancing its application scope in AI model serving.
Conclusion
Punica stands as an exemplary system for serving multiple LoRA models efficiently on shared GPU clusters, achieving substantial improvements in serving throughput and resource utilization. Its architectural innovations and batch processing capabilities set a new standard for memory and computation efficiency in the deployment of adapted LLMs across diverse application domains.
References
(Data available in original source)