GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment
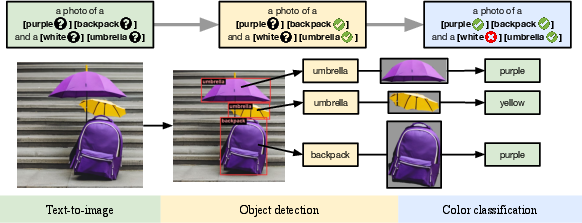
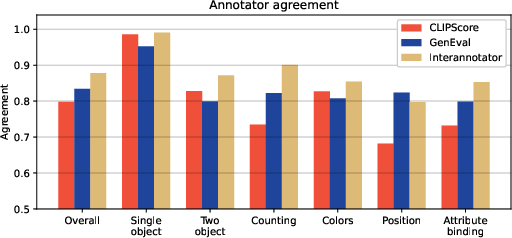
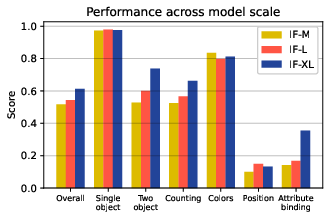
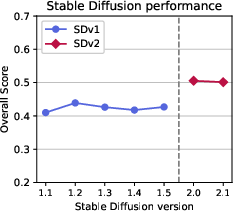
Abstract: Recent breakthroughs in diffusion models, multimodal pretraining, and efficient finetuning have led to an explosion of text-to-image generative models. Given human evaluation is expensive and difficult to scale, automated methods are critical for evaluating the increasingly large number of new models. However, most current automated evaluation metrics like FID or CLIPScore only offer a holistic measure of image quality or image-text alignment, and are unsuited for fine-grained or instance-level analysis. In this paper, we introduce GenEval, an object-focused framework to evaluate compositional image properties such as object co-occurrence, position, count, and color. We show that current object detection models can be leveraged to evaluate text-to-image models on a variety of generation tasks with strong human agreement, and that other discriminative vision models can be linked to this pipeline to further verify properties like object color. We then evaluate several open-source text-to-image models and analyze their relative generative capabilities on our benchmark. We find that recent models demonstrate significant improvement on these tasks, though they are still lacking in complex capabilities such as spatial relations and attribute binding. Finally, we demonstrate how GenEval might be used to help discover existing failure modes, in order to inform development of the next generation of text-to-image models. Our code to run the GenEval framework is publicly available at https://github.com/djghosh13/geneval.
- URL https://openai.com/dall-e-2.
- URL https://www.midjourney.com/.
- Romain Beaumont. Clip retrieval: Easily compute clip embeddings and build a clip retrieval system with them. https://github.com/rom1504/clip-retrieval, 2022.
- Basic color terms: Their universality and evolution. CLSI Publ., 2000.
- MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019.
- X-iqe: explainable image quality evaluation for text-to-image generation with visual large language models, 2023.
- Masked-attention mask transformer for universal image segmentation. 2022.
- Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2818–2829, 2023.
- Dall-eval: Probing the reasoning skills and social biases of text-to-image generative transformers. 2022.
- Dall·e mini, 7 2021. URL https://github.com/borisdayma/dalle-mini.
- Deep-Floyd. Deep-floyd/if. URL https://github.com/deep-floyd/IF.
- Eva-02: A visual representation for neon genesis. arXiv preprint arXiv:2303.11331, 2023.
- Training-free structured diffusion guidance for compositional text-to-image synthesis. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=PUIqjT4rzq7.
- Benchmarking spatial relationships in text-to-image generation, 2022.
- CLIPScore: a reference-free evaluation metric for image captioning. In EMNLP, 2021.
- Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 6629–6640, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- Semantic object accuracy for generative text-to-image synthesis. IEEE transactions on pattern analysis and machine intelligence, 44(3):1552–1565, 2020.
- Inferring semantic layout for hierarchical text-to-image synthesis. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7986–7994, 2018.
- Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. arXiv preprint arXiv:2303.11897, 2023.
- Scaling up gans for text-to-image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- Pick-a-pic: An open dataset of user preferences for text-to-image generation, 2023.
- Kuprel. Kuprel/min-dalle: Min(dall·e) is a fast, minimal port of dall·e mini to pytorch. URL https://github.com/kuprel/min-dalle.
- Microsoft COCO: common objects in context. CoRR, abs/1405.0312, 2014. URL http://arxiv.org/abs/1405.0312.
- Llmscore: Unveiling the power of large language models in text-to-image synthesis evaluation, 2023.
- Generating images from captions with attention. In ICLR, 2016.
- Simple open-vocabulary object detection with vision transformers. arXiv preprint arXiv:2205.06230, 2022.
- Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, pp. 311–318, USA, 2002. Association for Computational Linguistics. doi: 10.3115/1073083.1073135. URL https://doi.org/10.3115/1073083.1073135.
- Benchmark for compositional text-to-image synthesis. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 2021. URL https://openreview.net/forum?id=bKBhQhPeKaF.
- Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020. URL http://jmlr.org/papers/v21/20-074.html.
- Zero-shot text-to-image generation. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 8821–8831. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/ramesh21a.html.
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Generative adversarial text to image synthesis. CoRR, abs/1605.05396, 2016. URL http://arxiv.org/abs/1605.05396.
- High-resolution image synthesis with latent diffusion models, 2021.
- Photorealistic text-to-image diffusion models with deep language understanding, 2022.
- Improved techniques for training gans. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, pp. 2234–2242, Red Hook, NY, USA, 2016. Curran Associates Inc. ISBN 9781510838819.
- LAION-5b: An open large-scale dataset for training next generation image-text models. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022. URL https://openreview.net/forum?id=M3Y74vmsMcY.
- Cider: Consensus-based image description evaluation. CoRR, abs/1411.5726, 2014. URL http://arxiv.org/abs/1411.5726.
- Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis, 2023.
- Imagereward: Learning and evaluating human preferences for text-to-image generation, 2023.
- Attngan: Fine-grained text to image generation with attentional generative adversarial networks. CoRR, abs/1711.10485, 2017. URL http://arxiv.org/abs/1711.10485.
- Scaling autoregressive models for content-rich text-to-image generation. Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=AFDcYJKhND. Featured Certification.
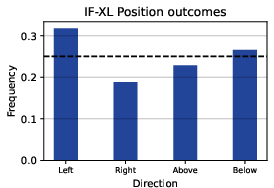
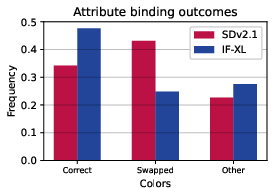
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.