- The paper presents a detailed taxonomy of hallucinations, introducing the Hallucination Vulnerability Index to measure LLM error severity.
- It employs both black-box and gray-box strategies to mitigate errors, using targeted word replacement and factuality checks.
- Findings indicate that larger, less refined LLMs are more prone to hallucination, underscoring the need for enhanced training protocols.
The Troubling Emergence of Hallucination in LLMs
Introduction to Hallucination in LLMs
The advent of LLMs such as GPT, DALL-E, and Stable Diffusion has been accompanied by significant challenges, notably the phenomenon known as "hallucination". Hallucinations refer to the generation of content by LLMs that is factually incorrect or unsubstantiated, resulting in outputs that deviate from real facts. This paper presents a comprehensive analysis of hallucination within LLMs, including a detailed taxonomy of hallucination types, the introduction of a Hallucination Vulnerability Index (HVI), and the proposal of mitigation strategies.
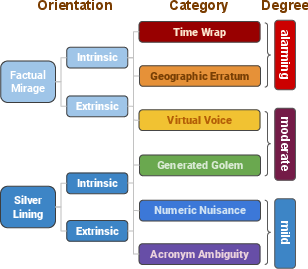
Figure 1: Hallucination: orientation, category, and degree (decreasing level of difficulty from top to bottom).
Taxonomy of Hallucination
The taxonomy proposed in the paper categorizes hallucinations into two primary orientations: Factual Mirage (FM) and Silver Lining (SL), each further divided into intrinsic and extrinsic sub-categories. Additionally, six specific types of hallucination are identified: Acronym Ambiguity, Numeric Nuisance, Generated Golem, Virtual Voice, Geographic Erratum, and Time Wrap.
Factual Mirage
Factual Mirage occurs when LLMs distort factually correct prompts. An intrinsic Factual Mirage includes adding tangential facts to an otherwise accurate response, while an extrinsic Factual Mirage refers to outputs that contradict the factual accuracy of the prompt.
Silver Lining
Silver Lining describes scenarios where LLMs respond convincingly to factually incorrect prompts. This includes intrinsic cases, where the model’s response lacks a convincing narrative, and extrinsic instances where it generates a detailed but incorrect story.
Hallucination Vulnerability Index (HVI)
The HVI is introduced as a quantifiable metric allowing the assessment and ranking of LLMs based on their susceptibility to generating hallucinations. The formula for HVI incorporates the frequency and severity of hallucinations, using damping factors to adjust for varying levels of distortion within generated content. The index provides a comparative analysis across different models, offering critical insights for policymakers and researchers.
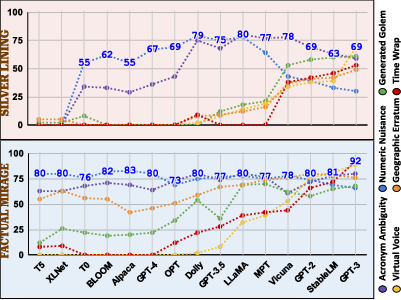
Figure 2: HVI for different hallucination categories across various LLMs.
Mitigation Strategies
Two primary strategies for mitigating hallucinations are presented:
- High Entropy Word Spotting and Replacement (ENTROPY\textsubscript{BB}): This black-box approach utilizes open-source LLMs to identify high entropy words within hallucinated text, replacing them with alternatives from other LLMs with a lower HVI. This method effectively reduces hallucinations related to Acronym Ambiguity and Numeric Nuisance.
- Factuality Check of Sentences (FACTUALITY\textsubscript{GB}): As a gray-box approach, this method employs textual entailment techniques to validate AI-generated text against external factual databases, identifying content that requires human review.
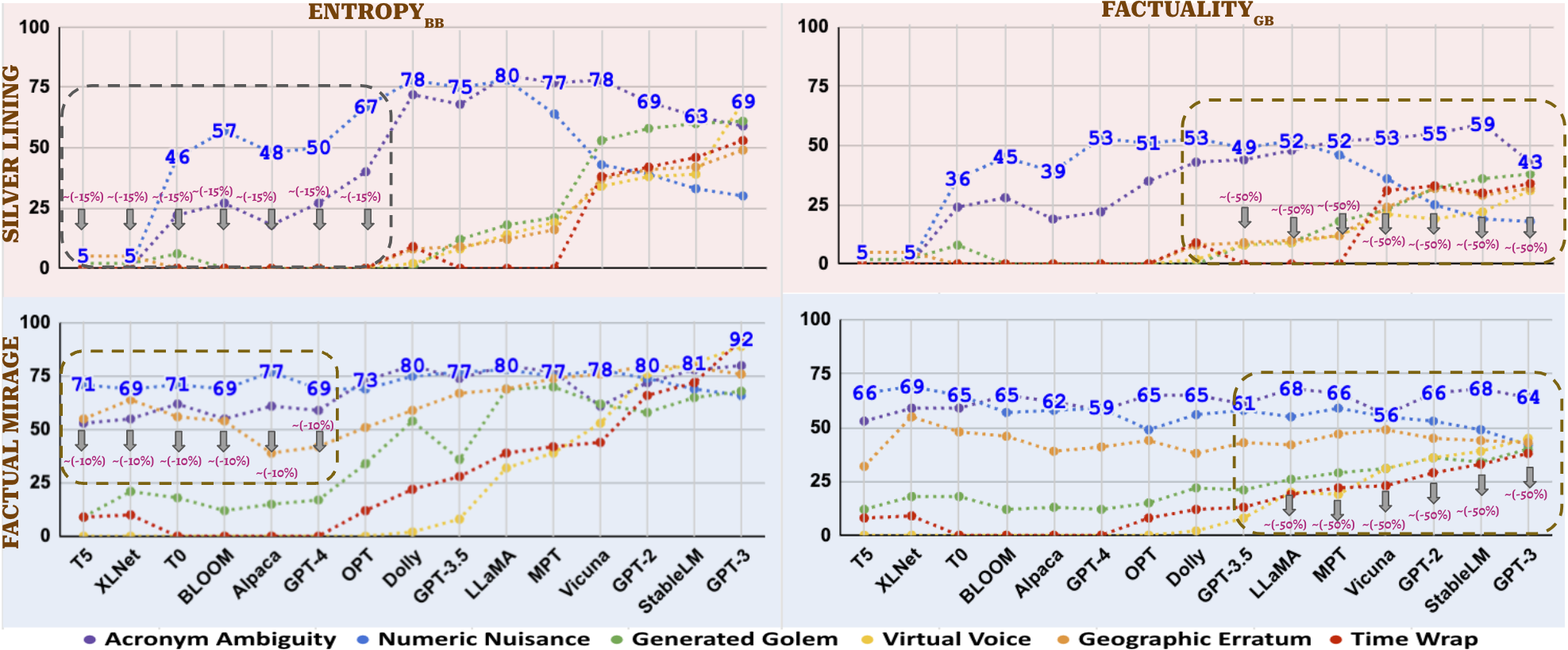
Figure 3: A hallucination example pre- and post-mitigation.
Discussion
The findings underscore the complexity of fully mitigating hallucinations due to the inherent challenges within LLM architectures and the variability in their outputs. Larger LLMs without reinforcement learning from human feedback have shown a greater propensity for hallucination, highlighting an area for further refinement in model training processes.
Conclusion
The paper provides a foundational framework for understanding and addressing hallucination in LLMs, presenting both a robust taxonomy and practical tools like the HVI and mitigation strategies. The work underscores the importance of continued research into refining LLMs to ensure higher fidelity in generated content, alongside supportive regulatory measures informed by these insights. Future research is encouraged to advance hybrid mitigation methods, leveraging combined strengths of black-box and gray-box approaches.

