- The paper demonstrates that PEFT techniques, particularly LoRA and QLoRA, significantly lower computational costs while maintaining or enhancing code generation performance.
- It compares various fine-tuning methods using datasets like CoNaLa and CodeAlpacaPy, with noticeable gains in metrics such as Exact Match and CodeBLEU.
- The study reveals that joint training with a unified LoRA adapter can match separate fine-tuning performance, thus streamlining resource usage and simplifying deployment.
Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with LLMs
Introduction
LLMs have emerged as powerful tools in automated code generation, capable of producing syntactically correct code snippets from natural language intents. However, the traditional full fine-tuning approach to adapt these models to specific tasks is hindered by substantial computational costs, particularly for models with billions of parameters. This paper investigates Parameter-Efficient Fine-Tuning (PEFT) techniques as cost-effective alternatives to enhance LLM specialization for code generation tasks. These techniques promise to maintain the benefits of task-specific fine-tuning while being computationally feasible in resource-constrained environments.
Parameter-Efficient Fine-Tuning Techniques
The study compares several PEFT techniques, including LoRA, IA3, Prompt tuning, Prefix tuning, and QLoRA, against traditional methods like In-Context Learning (ICL) and full fine-tuning. LoRA, which involves injecting low-rank trainable matrices into the attention layers, is highlighted as particularly effective, dramatically reducing the number of trainable parameters while maintaining or improving model effectiveness compared to full fine-tuning.
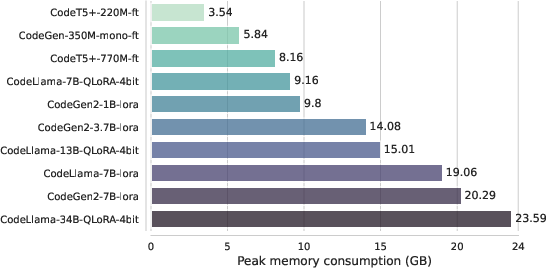
Figure 1: Peak GPU memory consumption during the fine-tuning of models using full fine-tuning (ft), LoRA, and QLoRA.
Dataset and Evaluation Metrics
The research relies on two datasets: CoNaLa, sourced from StackOverflow, and CodeAlpacaPy, a curated compilation from the CodeAlpaca dataset focused on Python code. These datasets provide ample examples for training and evaluation, representing diverse code generation scenarios. Key metrics used for evaluation include Exact Match (EM), EM@k, and CodeBLEU, which capture the precision of code generation and its alignment with the intended functionality.
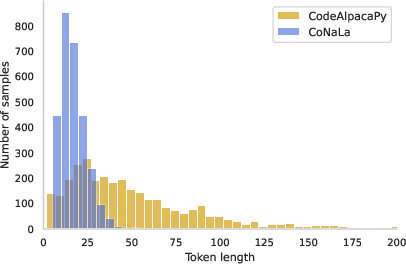
Figure 2: Token length distribution of CoNala and CodeAlpacaPy.
Results and Comparative Analysis
The experimental results demonstrate that LLMs fine-tuned with PEFT techniques significantly outperform small LLMs and the ICL approach. For instance, LLMs with LoRA exhibit a substantial improvement in EM@k, showcasing the effectiveness of parameter-efficient approaches in adapting larger models to specific datasets. The study also explores joint training using a single LoRA adapter, finding that this approach achieves comparable effectiveness to separate fine-tuning, thereby reducing complexity and storage demands during inference.
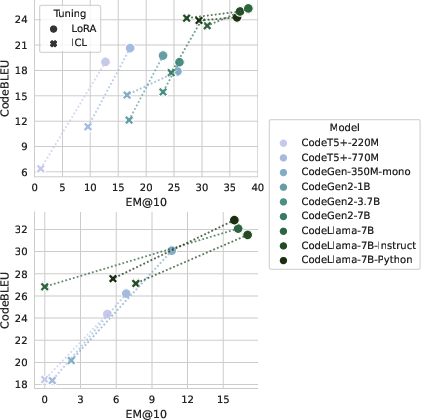
Figure 3: [RQ2] -- Comparison of the effectiveness of the models using LoRA and ICL on CoNala (top) and CodeAlpacaPy (bottom).
Resource Optimization Through QLoRA
QLoRA combines LoRA with model quantization, further reducing computational resources required for fine-tuning LLMs. The study successfully demonstrates the tuning of models as large as 34 billion parameters within a 24GB GPU memory constraint, highlighting QLoRA's ability to reduce memory consumption significantly—up to a two-fold decrease compared to LoRA—while maintaining or improving model effectiveness.
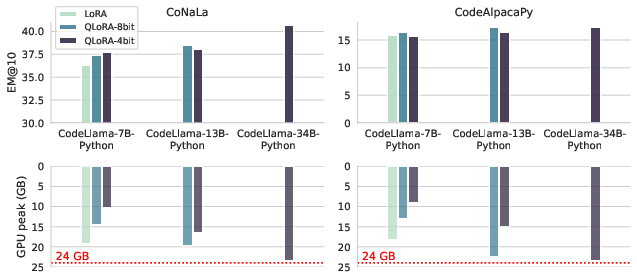
Figure 4: [RQ4] -- Performance of CodeLlama models using LoRA and QLoRA with 8-bit and 4-bit quantization. The cost of all the assessed techniques and models remains within the limit of our constrained computational budget.
Implications and Future Work
The implications of this research are profound for software engineering, particularly in contexts where computational resources are limited. By leveraging PEFT, developers and researchers can efficiently adapt LLMs to nuanced coding tasks, democratizing advanced model tuning techniques. Future work could explore PEFT applications in other software engineering domains, such as automated code review or documentation generation, and in multi-tasking or continual learning scenarios.
Conclusion
This study provides compelling evidence for the advantages of Parameter-Efficient Fine-Tuning techniques in code generation tasks with LLMs. The reduction in computational costs while maintaining high performance opens new possibilities for utilizing LLMs without necessitating extensive infrastructure. As such, PEFT techniques present a valuable direction for future research and application in artificial intelligence and software development.