- The paper introduces a multi-agent framework combining Tree-of-Thought strategies with a Thought Validator to streamline reasoning paths.
- It employs parallel Reasoner agents that explore solution trees while a Validator discards flawed branches through a consensus approach.
- Experiments on GSM8K reveal an accuracy improvement of up to 8.8%, particularly enhancing performance on complex arithmetic tasks.
Improving LLM Reasoning with Multi-Agent Tree-of-Thought Validator Agent
This essay provides an authoritative summary of the paper "Improving LLM Reasoning with Multi-Agent Tree-of-Thought Validator Agent" (2409.11527). The paper introduces a novel approach to enhance the reasoning capabilities of LLMs through the integration of Tree of Thoughts (ToT) strategies within a multi-agent framework complemented by a Thought Validator agent.
Background and Motivation
The paper addresses the limitations of current multi-agent reasoning frameworks, where Reasoner agents tend to explore reasoning paths shallowly. ToT techniques, which simulate human-like thought processes by exploring various paths before reaching a solution, are introduced as a potential solution to navigate the expansive problem space. However, ToT alone risks generating flawed reasoning branches, which could compromise the quality and trustworthiness of final outputs. The proposed innovation is to combine multi-agent systems with ToT and introduce a Thought Validator agent that assesses and discards invalid reasoning branches.
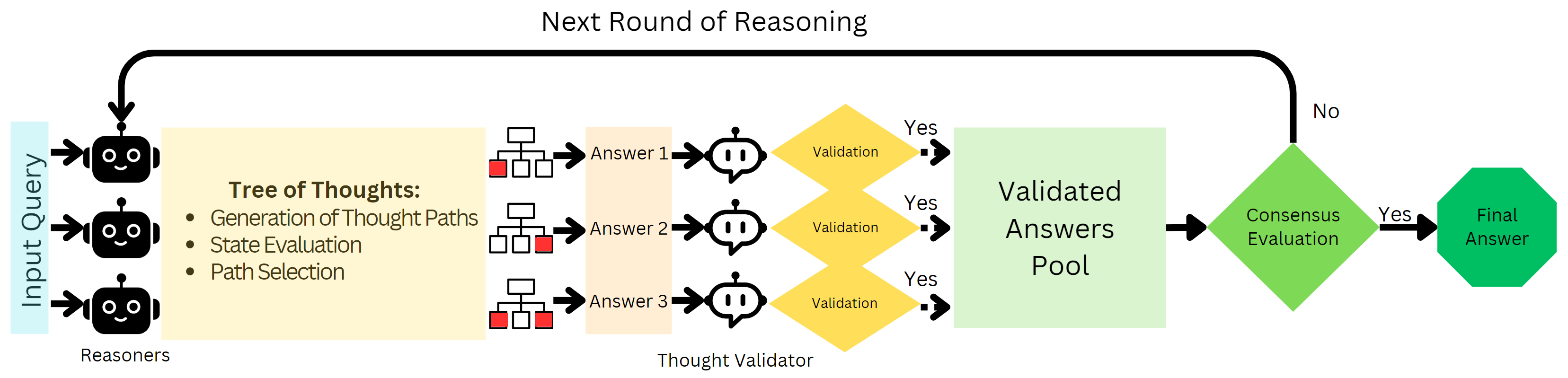
Figure 1: The process begins with a query processed by multiple Reasoner agents using the ToT strategy, followed by a validation and consensus phase handled by the Thought Validator agent.
Methodology
Multi-Agent ToT Strategy: The framework comprises multiple Reasoner agents operating in parallel, each employing the ToT strategy. This approach allows for systematic exploration across various reasoning paths. Starting with a common problem query, each agent independently generates a tree of possible solutions or reasoning steps.
- Tree of Thoughts (ToT) Structure: The paper defines the reasoning process as a tree search over states. States here represent intermediate reasoning steps and the transition from one state to another within the tree symbolizes a possible reasoning progression towards a solution.
- Evaluation and Verification: At each tree level, reasoning branches are evaluated using a state scoring mechanism. The Thought Validator agent subsequently examines the coherence, factual accuracy, and completeness of these branches. Invalid branches are discarded, ensuring only sound reasoning contributes to final decisions.
Consensus-Based Mechanism: The Thought Validator employs a consensus-based strategy where only validated, sound reasoning steps contribute to final outputs. If consensus is not achieved, new reasoning rounds are initiated, incorporating feedback from the Validator to refine subsequent explorations.
Experimental Results
The proposed method was evaluated on the challenging GSM8K dataset, achieving an average improvement of 5.6% in accuracy over standard ToT strategies across four different LLMs. Notably, the method demonstrated significant performance enhancements, particularly in complex arithmetic reasoning tasks.
- Improvement in Accuracy: The multi-agent ToT with Thought Validator significantly outperformed standalone ToT methods, showing superior accuracy across models, such as a 8.8 percentage point increase for GPT-3.5-turbo.
- Verification Role: The integration of the Thought Validator proved pivotal in maintaining high trustworthiness by effectively eliminating flawed reasoning paths, thus enhancing the reliability of final solutions.
Limitations and Future Work
While the proposed system shows enhanced reasoning capabilities, the computational overhead introduced by the multi-agent and ToT strategies is considerable. The approach demands significant computational resources, highlighting the need for optimization. Future work could explore adaptive tree structuring, allowing dynamic allocation of exploration depth based on problem complexity, potentially mitigating the computational load.
Conclusion
The integration of ToT with a multi-agent framework and Thought Validator significantly enhances the systematic reasoning capabilities of LLMs. The approach effectively balances exploration and validation, resulting in improved accuracy and trustworthiness of solutions. These advancements promise more robust AI reasoning systems, although further research is necessary to optimize computational resource requirements and validate generalizability across diverse reasoning tasks.