- The paper introduces a novel self-evaluation guided beam search method that decomposes multi-step reasoning tasks into intermediate steps to reduce uncertainty and error buildup.
- The methodology integrates stochastic beam search with temperature-controlled randomness, balancing exploitation and exploration to enhance prediction accuracy.
- Empirical results demonstrate significant accuracy improvements on arithmetic, symbolic, and commonsense benchmarks despite added computational overhead.
Self-Evaluation Guided Beam Search for Reasoning
The paper "Self-Evaluation Guided Beam Search for Reasoning" (2305.00633) introduces a novel approach to enhance reasoning processes in LLMs by integrating self-evaluation guidance within stochastic beam search. This innovative method focuses on breaking down complex reasoning tasks into intermediate steps, which reduces uncertainty and error accumulation while facilitating more accurate predictions.
Introduction to Multi-step Reasoning Challenges
LLMs have demonstrated significant capabilities in reasoning across various tasks through techniques like few-shot prompting. However, increasing the complexity and length of reasoning chains introduces challenges such as error accumulation and uncertainty, which can hinder the final accuracy of predictions. The presented solution tackles these issues by employing self-evaluation mechanisms to guide the beam search process in multi-step reasoning tasks.
Methodology: Self-Evaluation Guided Stochastic Beam Search
The authors propose a framework that utilizes self-evaluation guided stochastic beam search to enhance LLM reasoning. This framework decomposes reasoning into intermediate steps, allowing for a more granular evaluation of each step's correctness. The process is illustrated through a decoding algorithm that balances exploitation and exploration within the reasoning space using temperature-controlled randomness.
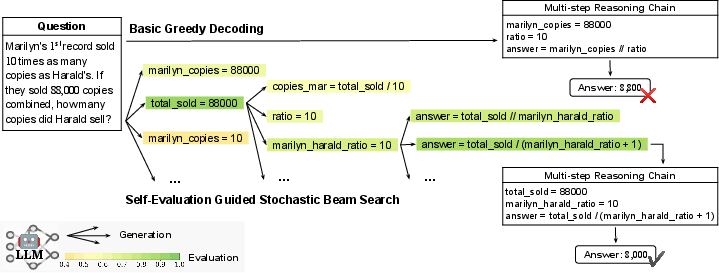
Figure 1: Self-Evaluation can calibrate the decoding direction in multi-step reasoning.
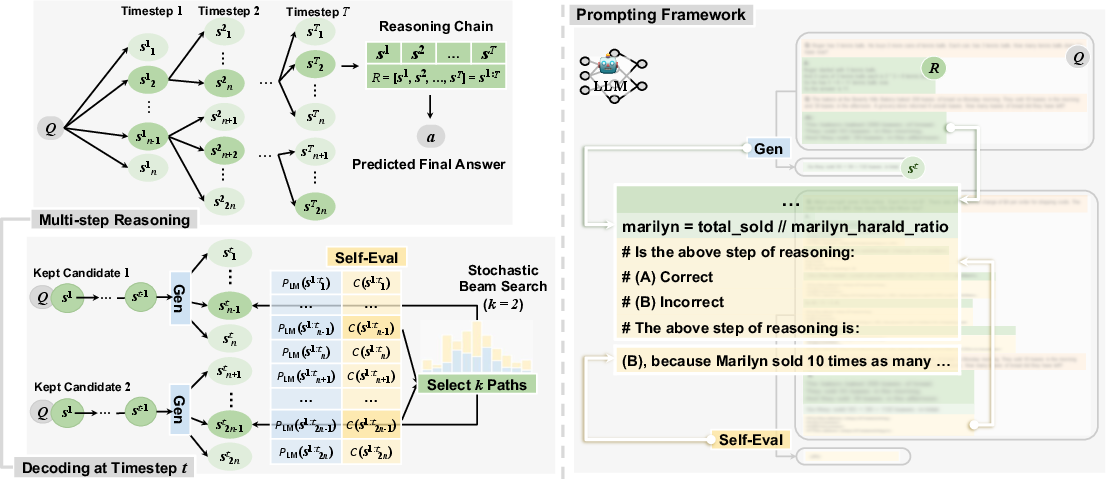
Figure 2: Our framework of self-evaluation guided stochastic beam search for multi-step reasoning.
Decoding Process with Self-Evaluation
The decoding process treats each intermediate reasoning step as a sequence of tokens, allowing for the application of beam search strategies tailored to enhance reasoning accuracy. A constraint function is introduced to evaluate the LLM's confidence in the correctness of each reasoning step. This confidence is combined with the LLM's generation probability to form a new decoding objective function.
The approach incorporates controllable randomness through stochastic beam search, balancing the quality-diversity trade-off in generating reasoning chains. The combination of self-evaluation and temperature-controlled randomness effectively improves final prediction quality across reasoning tasks.
Empirical Results
The proposed method was evaluated on benchmarks across arithmetic, symbolic, and commonsense reasoning tasks. It demonstrated significant improvements in model accuracy over baseline methods:
- Arithmetic Reasoning: On GSM8K, AQuA, and SVAMP, absolute accuracy increases of 6.34%, 9.56%, and 5.46% were observed, respectively.
- Symbolic and Commonsense Reasoning: Consistent performance gains were achieved, demonstrating the method's effectiveness in navigating complex reasoning chains.
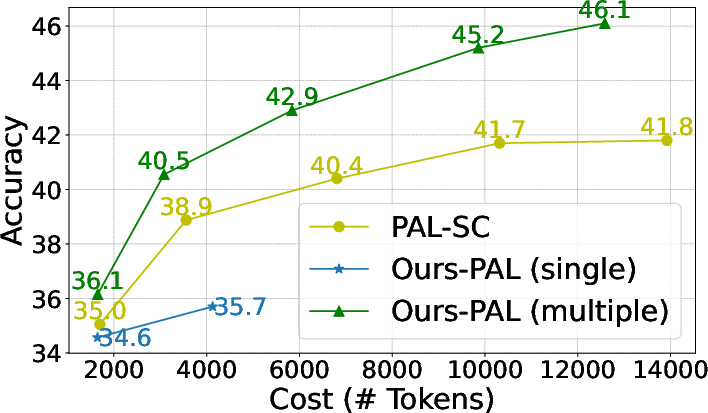
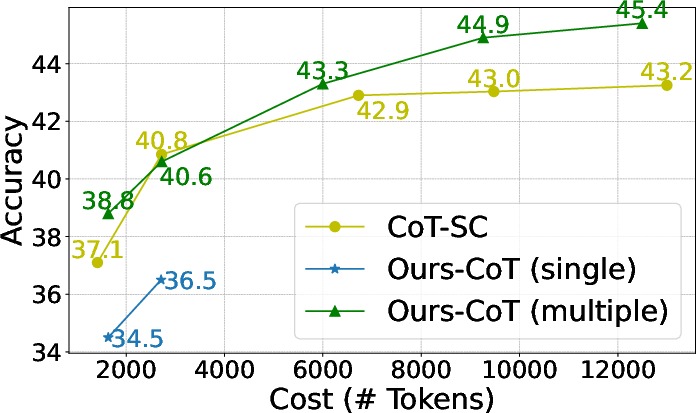


Figure 3: PAL Prompting Methods on GSM8K.
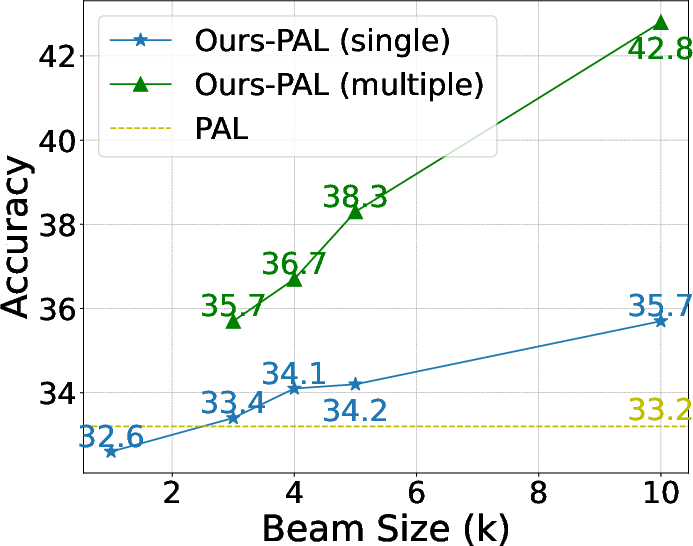
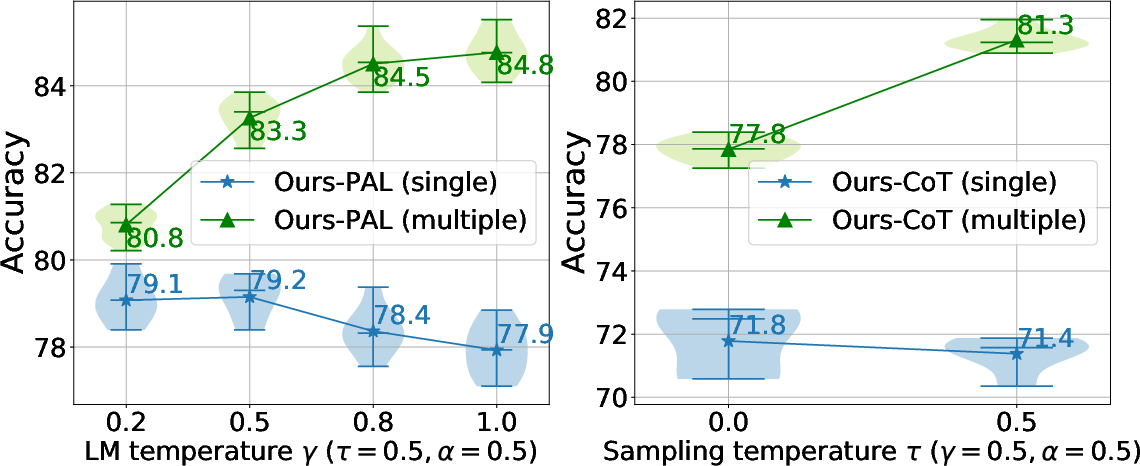
Figure 4: Effect of beam size.


Figure 5: Examples of self-evaluation score distribution of different predictions on the GSM8K dataset.
Discussion on Computational Costs and Limitations
Despite the empirical success, the method introduces an overhead of computational cost due to the additional sampling required for self-evaluation and candidate generation. However, the approach remains efficient for longer reasoning chains, where stepwise calibration proves beneficial in improving overall accuracy.
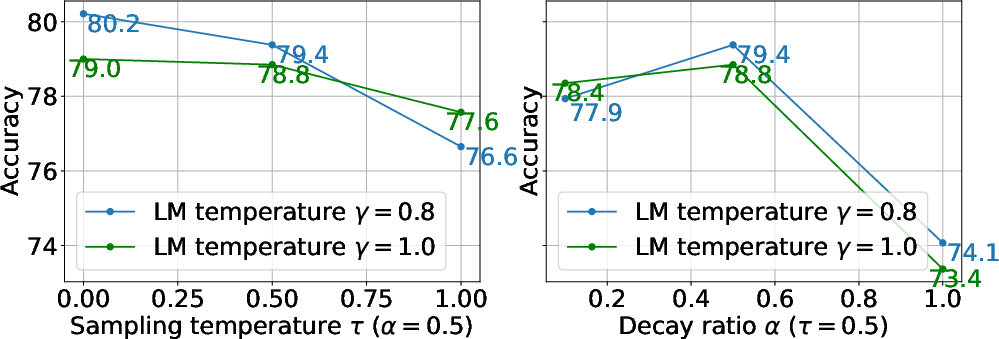
Figure 6: Accuracy curves with different sampling diversity.
Conclusion
Self-evaluation guided beam search is a promising approach to enhance reasoning in LLMs by reducing error rates in multi-step tasks. It offers insights into leveraging LLMs' self-evaluation capabilities to refine logical reasoning, applicable in various domains requiring complex reasoning and decision-making. Future advancements may explore integrating external tools for improved calibration and generalization across multi-step reasoning scenarios.