- The paper introduces a novel multimodal reasoning system that integrates ChatGPT with vision experts via prompt engineering, extending the model’s visual understanding.
- It employs a structured execution flow where ChatGPT delegates tasks like image captioning, OCR, and spatial analysis to specialized experts without additional training.
- Empirical comparisons show that MM-ReAct achieves competitive performance with fine-tuned models, highlighting its extensible, cost-effective design for complex visual tasks.
MM-ReAct: Prompting ChatGPT for Multimodal Reasoning and Action
Introduction
The paper introduces MM-ReAct, a system designed to facilitate multimodal reasoning and action by integrating ChatGPT with a pool of vision experts. This approach aims to address advanced vision tasks that exceed the capabilities of existing vision and vision-LLMs. The system leverages a textual prompt design to enable LLMs to process multimodal information, effectively combining ChatGPT and various vision experts without requiring additional multimodal training.
System Design
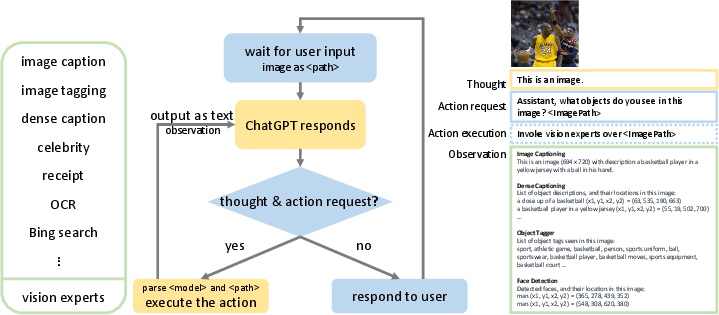
MM-ReAct's architecture consists of a flexible framework that synthesizes numerous vision experts to extend ChatGPT's capabilities in visual understanding. Key components of the system include:
Execution Flow
The execution flow of MM-ReAct is driven by coordinated reasoning and action steps. In this setup,:
- Thought Generation: ChatGPT generates reasoning texts that outline the problem-solving process, breaking down complex tasks into manageable sub-tasks.
- Action Requests: Based on the thought process, ChatGPT issues action requests to vision experts using predefined keywords, enabling precise task delegation.
- Expert Responses: Vision experts provide responses standardized as text, facilitating integration into the conversation flow managed by ChatGPT.
- Final Answer Generation: The aggregated information from various experts is used by ChatGPT to generate comprehensive responses to user queries.
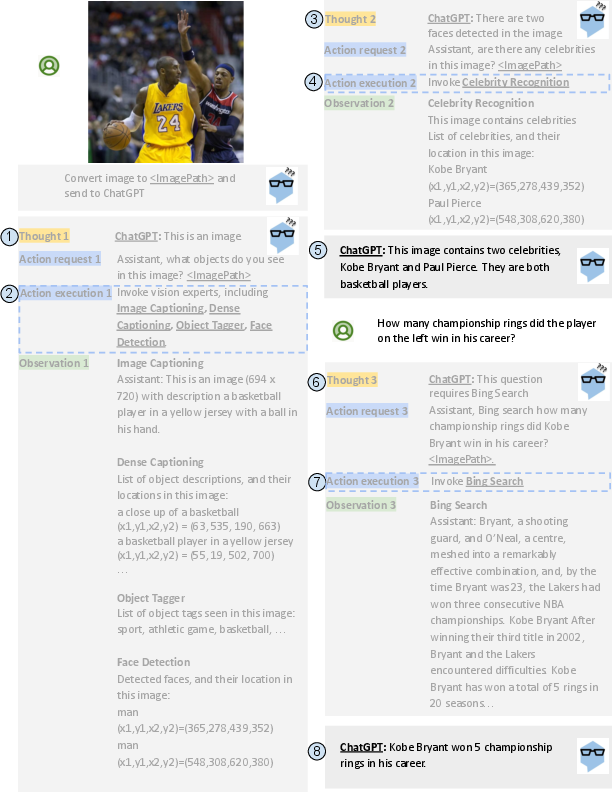
Figure 2: An example of MM-ReAct's full execution flow.
Capabilities and Applications
MM-ReAct demonstrates diverse capabilities across several complex reasoning and application scenarios. These include:
- Visual Mathematics and Text Reasoning: Successfully combining visual input with text-based reasoning for problem-solving (Figure 3).
- Visual-Conditioned Humor Understanding: Interpreting memes and jokes conditioned on visual context (Figure 4).
- Spatial and Coordinate Tasks: Performing spatial analysis, prediction, and visual planning (Figure 5).
- Multi-Image Reasoning: Integrating data from multiple visual inputs to solve more complex queries (Figure 6).
- Document and Video Analysis: Advanced document understanding, including flowcharts and tables, and summarizing events in videos (Figures 7-13).
Comparison with PaLM-E
While MM-ReAct operates without additional training by integrating existing vision experts, it shows competitive performance, with empirical results indicating that prompt-based approaches can match the capabilities of expensive joint fine-tuning processes seen in models such as PaLM-E.
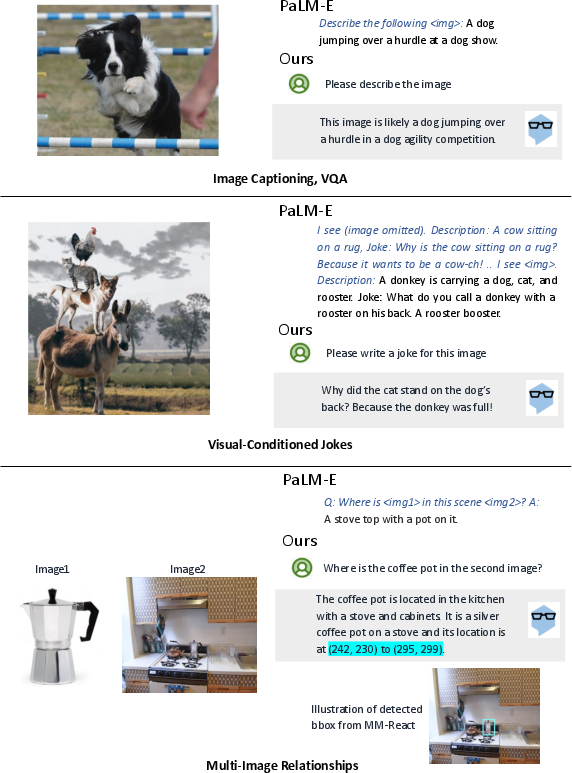
Figure 7: Comparison of MM-ReAct with PaLM-E on illustrated capabilities.
System Extensibility
MM-ReAct's design is inherently extensible, allowing integration of new LLMs, like GPT-4, and the addition of new vision tools, such as image editing models. This flexibility supports ongoing improvements in system performance without requiring retraining.

Figure 8: Case studies of MM-ReAct's extensibility.
Conclusion
MM-ReAct advances the paradigm of integrating LLMs with vision experts for multimodal reasoning and action, effectively tackling complex visual understanding tasks. The system's flexibility in expert integration and prompt engineering sets the stage for further enhancements in visual reasoning applications. Despite identified limitations such as dependency on existing vision experts and constrained context windows, MM-ReAct presents a groundbreaking step toward richer multimodal AI interactions.