- The paper introduces SelfCheck, a novel zero-shot verification method enabling LLMs to detect and correct their own reasoning errors.
- It employs a structured four-step pipeline—target extraction, information collection, step regeneration, and result comparison—to enhance step accuracy.
- Evaluation on GSM8K, MathQA, and MATH datasets demonstrates improved performance over standard voting schemes with more reliable confidence measures.
SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning
In the domain of automated reasoning and verification, the paper "SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning" proposes a novel methodology for enhancing the accuracy and reliability of LLMs by using them to verify their own outputs. The paper introduces a verification scheme named SelfCheck, designed to identify errors in step-by-step reasoning without relying on external datasets or specialized training.
Introduction to SelfCheck
SelfCheck is developed to address the inadequacies of LLMs when faced with complex problems requiring multi-step reasoning. Existing LLM approaches, such as Chain-of-Thought (CoT) prompting, have been effective in generating stepwise solutions but often lack the capability to detect and correct their mistakes in reasoning steps quantitatively. SelfCheck aims to fill this gap by introducing a zero-shot verification mechanism leveraging the LLM itself for error detection and correction.
The primary innovation of SelfCheck lies in its structured pipeline which decomposes the verification process into manageable stages. Instead of a direct verification which LLMs struggle with, SelfCheck applies four distinct steps: target extraction, information collection, step regeneration, and result comparison.
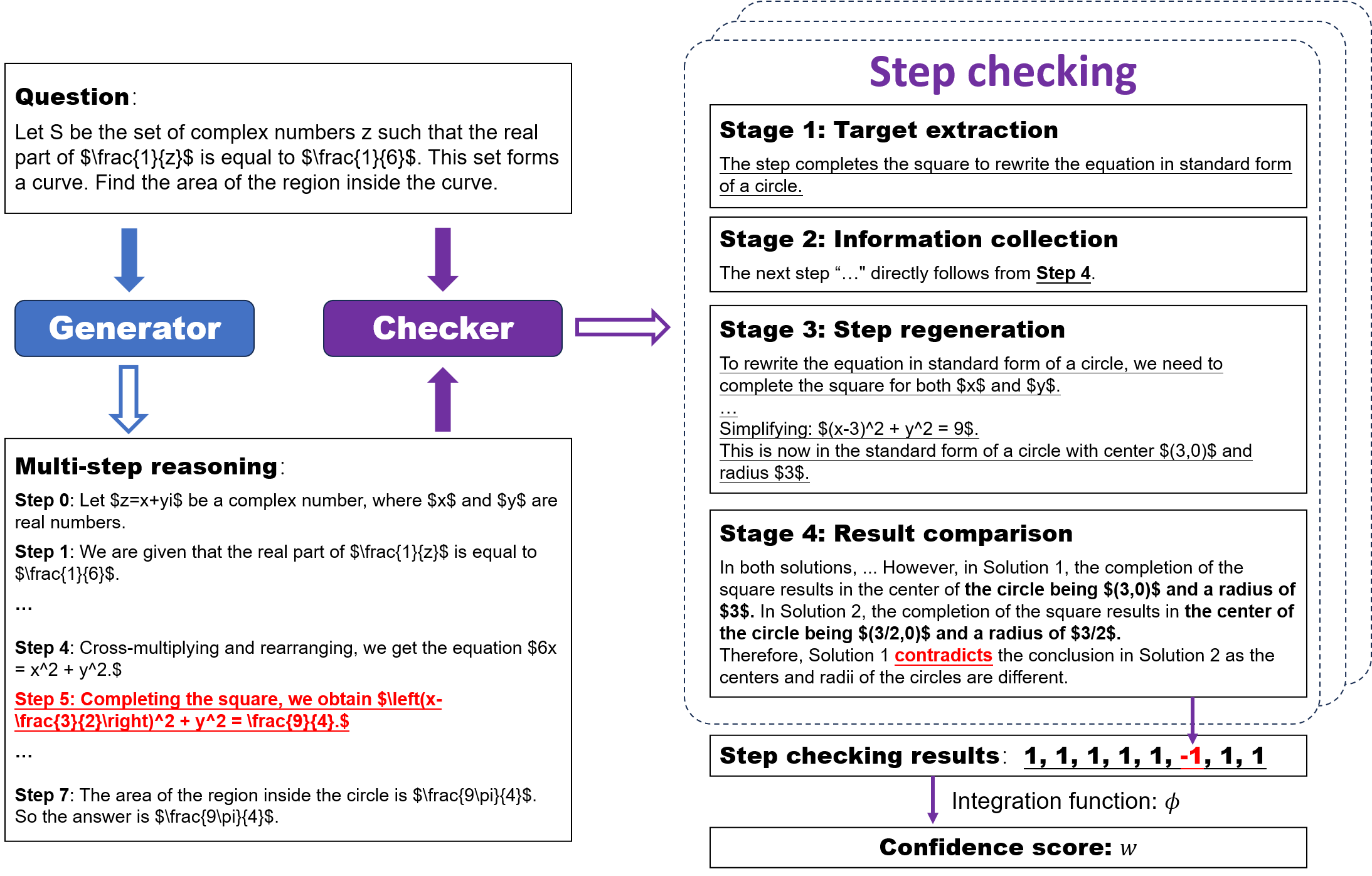
Figure 1: Example of using SelfCheck, focusing on the checking of a particular step (Step 5), including extraction, collection, regeneration, and comparison stages.
Step Verification Methodology
Target extraction isolates the goal of each reasoning step, prompting the LLM to succinctly define what the step intends to achieve. Information collection further fine-tunes the context by identifying only the relevant aspects of preceding steps or question data that contribute directly to this target.
Step Regeneration
In the step regeneration phase, the LLM is tasked with achieving the identified target independently using the gathered context, effectively regenerating the step's conclusion. This stage leverages the generative capabilities of the LLM, reducing biases and ensuring independence from the original output.
Result Comparison
The final comparison involves checking the consistency between the regenerated results and the original step. This process is critical as it determines whether the step is supported, contradicted, or unrelated to the regenerated outputs.
Evaluation and Results
The effectiveness of SelfCheck was validated using the GSM8K, MathQA, and MATH datasets. The system demonstrated improved accuracies through weighted voting mechanisms, outperforming simple majority voting and proving its utility across various complexity levels.
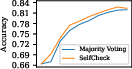
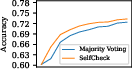
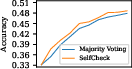
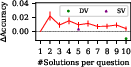
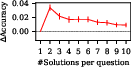
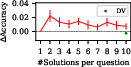
Figure 2: The upper plots show the accuracies of SelfCheck and majority voting with GPT-3.5 for various solution counts; the lower plots indicate accuracy changes.
The verification capabilities of SelfCheck were assessed through threshold-based confidence classification, revealing a substantial increase in solution correctness upon filtering out low-confidence results.
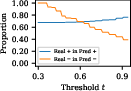
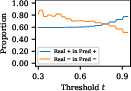
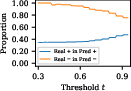
Figure 3: Proportions of correct solutions in predicted correct solutions across datasets GSM8K, MathQA, and MATH when thresholds are raised.
Comparative Analysis and Ablations
SelfCheck's architecture, especially its multi-stage verification design, was verified through ablation studies that showed its superiority over single-stage and direct error-checking methods. The explorations confirmed that decomposing the verification into well-defined stages yields better results than attempting holistic step evaluation.
Conclusion
SelfCheck introduces an effective methodology for self-contained reasoning verification within LLMs. By minimizing dependencies on external data, SelfCheck maintains versatility across domains. The paper’s experimentation confirms that the approach not only increases prediction accuracy but also provides more reliable confidence measures for individual solutions, showcasing significant advancements in automated reasoning and verification technologies.

