- The paper presents a single visual model that eliminates traditional sequence modeling for efficient scene text recognition.
- The paper employs a novel progressive patch embedding and mixing blocks for capturing both local and global text features.
- The paper demonstrates that SVTR variants deliver competitive accuracy and high inference speed, especially in multilingual scenarios.
SVTR: Scene Text Recognition with a Single Visual Model
The paper "SVTR: Scene Text Recognition with a Single Visual Model" introduces a novel approach to scene text recognition by employing a single visual model, SVTR, that foregoes the typical sequence modeling step traditionally used in this domain. This research presents a method that enhances efficiency while maintaining competitive accuracy across multiple languages.
Introduction
Scene text recognition is a domain that involves extracting text from natural images, which can pose challenges due to text deformation, varying fonts, and complex backgrounds. Historically, this task has relied on hybrid models combining convolutional neural networks (CNNs) and recurrent neural networks (RNNs), or more recently, encoder-decoder models. SVTR departs from these paradigms by utilizing a single visual model approach that focuses solely on feature extraction via a revised patch-wise tokenization method.
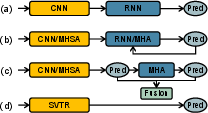
Figure 1: Various model architectures, including the proposed SVTR model (d), which focuses on efficiency and cross-lingual versatility using a single visual model.
Model Architecture
SVTR leverages a three-phase network architecture that progressively reduces the height of input features through a series of mixing blocks, specifically designed to capture both local and contextual information within text images.
- Patch Embedding: SVTR divides input text images into small patches representing character components. Notably, it employs a progressive patch embedding scheme that enhances feature fusion and achieves slight improvements over traditional strategies like linear projection.
- Mixing Blocks: The architecture integrates two critical enhancements through global and local mixing blocks, capitalizing on self-attention mechanisms to uncover intra-character and inter-character dependencies efficiently.
- Merging and Combining: Merging operations at various stages reduce the feature map's height while maintaining width and increasing channel dimensions, optimizing computational efficiency and maintaining the integrity of feature representations.
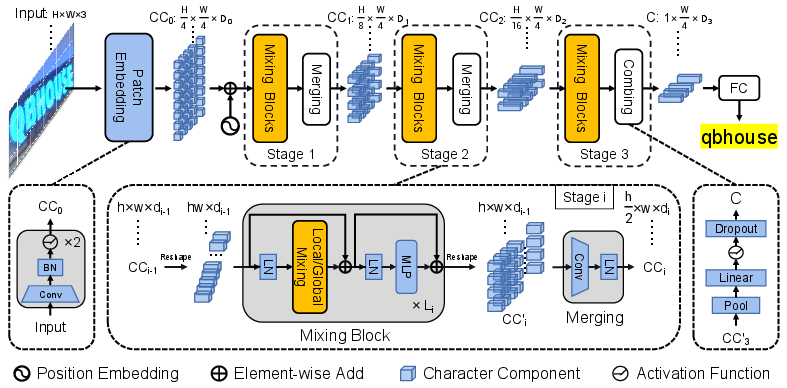
Figure 2: Overall architecture of SVTR, illustrating its three-stage network with height-decreasing operations and final linear prediction.
SVTR is evaluated against multiple benchmarks, showing considerable improvements especially in terms of recognition speed and cross-lingual capabilities. The Large variant (SVTR-L) achieves competitive accuracy compared to state-of-the-art methods, while the Tiny variant (SVTR-T) excels in speed and resource efficiency, catering to applications with hardware constraints.
In particular, SVTR demonstrated a significant edge in recognizing Chinese text, attributed to its robust handling of stroke-based patterns and multi-grained character perception.
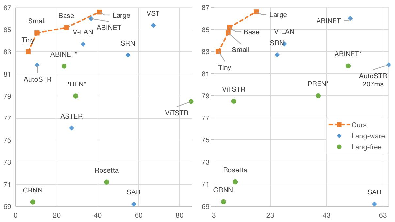
Figure 3: Plots comparing accuracy against model parameters and inference speed, highlighting SVTR's efficiency on the IC15 dataset.
Visualization and Analysis
Attention maps from SVTR highlight its ability to capture relevant text features at multiple levels, ranging from sub-character strokes to entire character and cross-character dependencies. This comprehensive feature extraction is pivotal in its superior performance, evidencing that a carefully designed visual model can rival more complex approaches involving LLMs.

Figure 4: Visualization of SVTR-T attention maps, demonstrating its multi-grained character feature perception capabilities.
Conclusion
SVTR effectively challenges the conventional dual-block approach in scene text recognition by presenting a singular focus on a visual model optimized for efficiency without sacrificing accuracy. Its architecture and methodology present a versatile solution that could stimulate further advances in real-world text recognition applications, especially in environments with resource limitations.
These advancements provide avenues for future investigations into scaling such models, exploring more efficient self-attention mechanisms, and expanding to more complex multi-lingual scenarios. The paper highlights SVTR's potential as both a practical and innovative tool in the text recognition landscape.