- The paper presents a hierarchical reinforcement learning controller that integrates a central pattern generator and PD controller to enable multiple gait patterns.
- It employs a PPO-based training strategy with cost functions designed to reduce velocity errors, energy consumption, and joint inefficiencies.
- Experimental results demonstrate improved velocity tracking and energy efficiency in intermediate velocity ranges compared to single-gait systems.
Learning Multiple Gaits of Quadruped Robots Using Hierarchical Reinforcement Learning
Introduction
The development of a velocity command tracking controller for quadruped robots is a significant challenge due to the complex interactions and environmental contact dynamics involved. This paper proposes a hierarchical reinforcement learning-based controller that addresses the limitations of single-policy end-to-end trained systems, which often default to a single gait pattern regardless of velocity commands. By using a structured two-policy system emulating central pattern generators (CPGs) and local feedback controllers, this research aims to enable quadruped robots to optimally select and transition between multiple gaits to improve energy efficiency and velocity tracking accuracy.
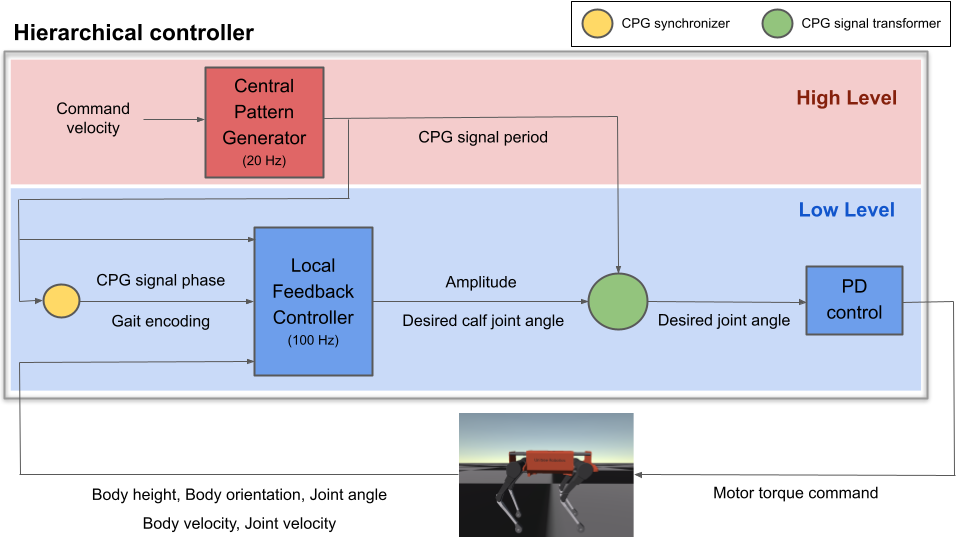
Figure 1: Proposed hierarchical controller for quadruped robot.
Historically, the locomotion control of robots has been approached via model-based analytic control, data-driven control with reference motions, and data-driven control without reference motions. Model-based approaches often struggle with robustness and scalability due to the inaccuracies in physical modeling and real-time computation limitations. The advent of reinforcement learning techniques has addressed some obstacles by using data-driven methodologies. However, these typically rely on reference movements that can be suboptimal due to conflicts in derivatives and reference motion gradients, limiting the system's adaptability to more generalized locomotive tasks.
Hierarchical Controller Framework
The proposed controller consists of a high-level CPG and a low-level PD controller, designed to dynamically adapt between gaits corresponding to velocity ranges similar to biological systems. The CPG is parameterized using sinusoidal functions to emulate the rhythmic gait patterns and is trained to output gait parameters such as period and phase based on velocity inputs. Concurrently, the local feedback controller receives signal adjustments and environmental feedback to fine-tune motor outputs, juxtaposing neural-inspired rhythmic behavior over a simple PD control loop.
The hierarchical design facilitates multiple degrees of freedom (8 DOF focused on thigh and calf joints), but can be adapted or modularized for more complex systems involving hip joints. This two-tier system alleviates challenges associated with single-policy models by leveraging the biological underpinnings of gait phasing and period adjustments.
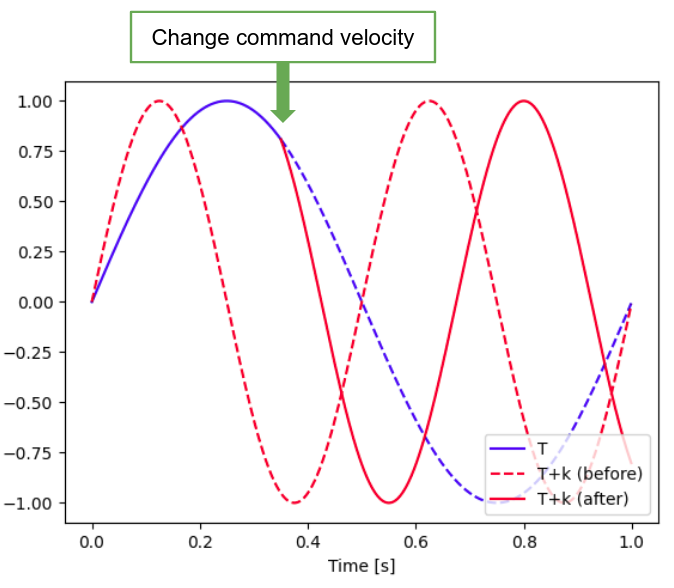
Figure 2: Effect of CPG signal synchronizer (T: current time, k: period of the high level controller).
Training and Cost Functions
Utilizing a PPO-based reinforcement learning strategy, the training facilitates cost functions centered on reducing angular and linear velocity errors, torque, and joint-speed inefficiencies. Gradual introduction of cost scaling aids in avoiding premature convergence to a suboptimal static state, instead promoting a progressive exploration of the gait strategy space.
Key metrics analyzed during training include energy consumption and velocity tracking errors, each normalized across various command velocities to discern optimal gait patterns.
Experimental Validation
Validation experiments concentrated on determining the existence of optimal gaits given specific velocity commands and assessing whether the hierarchical controller supports these multimodal patterns. The experiments tested for distinct gait patterns—trot, pace, and bound—across velocity ranges, confirming the expected trend of lower energy usage and improved velocity tracking accuracy within the intermediate velocity region for multiple gaits.

Figure 3: Single gait learned using our hierarchical controller.
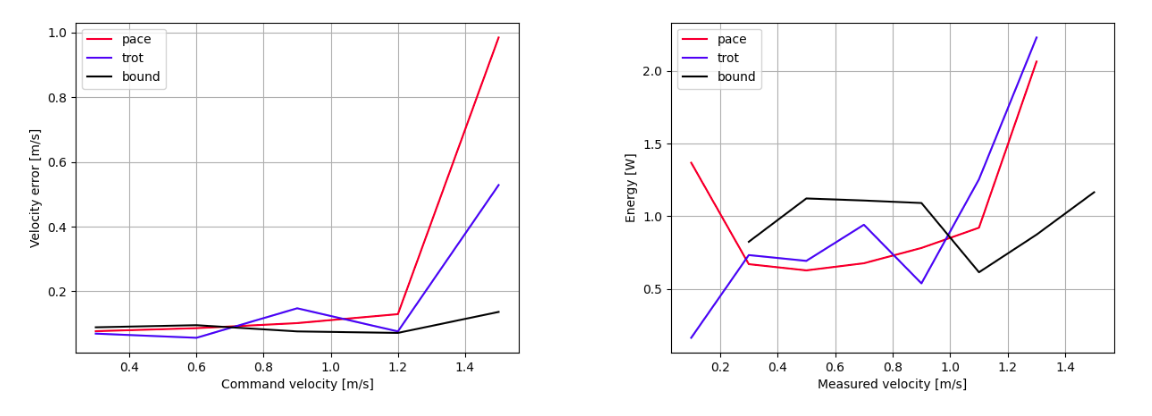
Figure 4: Velocity tracking error (left) and Energy consumption (right) for each gait.
The experiments conclusively demonstrate that the hierarchical controller serves as an efficient multiple-gait system outperforming a single-gait baseline in terms of energy efficiency across specific velocity segments. However, challenges persist in terms of abrupt CPG signal changes and gait transition smoothing, which currently degrade tracking accuracy during transitions.
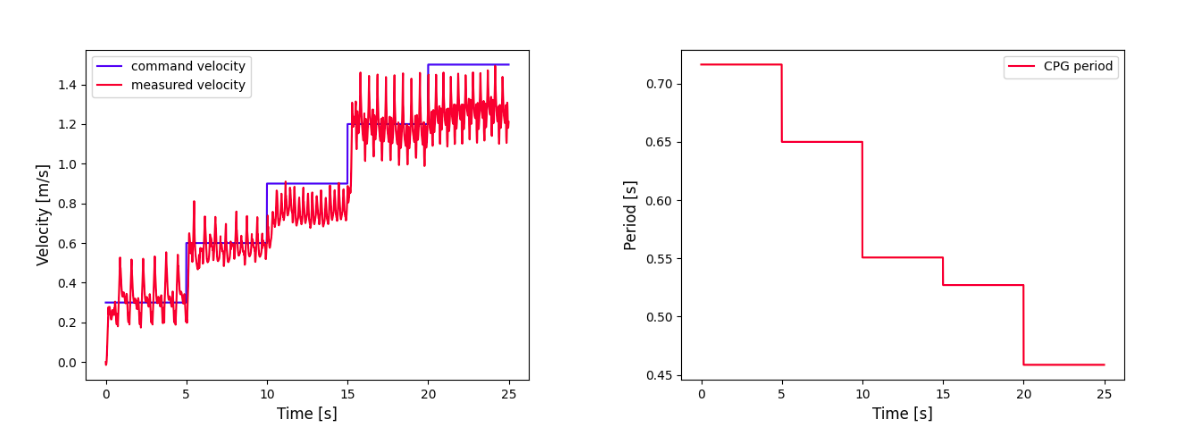
Figure 5: Velocity tracking result (left) and CPG signal period (right) of multiple gait controller.
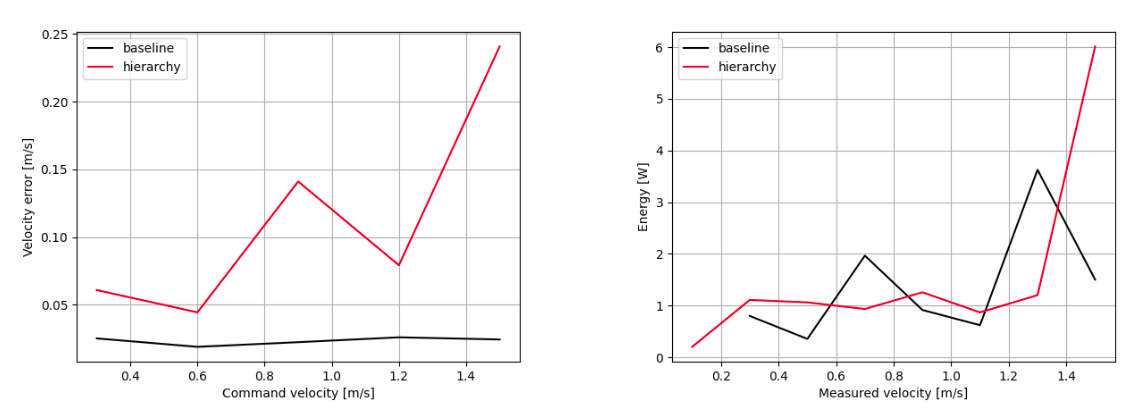
Figure 6: Velocity tracking error (left) and Energy consumption (right) of multiple gait controller and baseline controller.
Conclusions
The hierarchical controller efficiently supports the generation of multiple gaits, aligning with biological insights into energy-efficient locomotive behaviors. Future work should center on refining the transition dynamics between gait patterns to mitigate errors associated with abrupt phase changes in CPG signals. Further exploration might involve integrating analytic models or deeply architectured models to bolster system robustness against diverse environmental conditions, significantly broadening practical applications in robotics.

Figure 7: Contact plot for each gait.
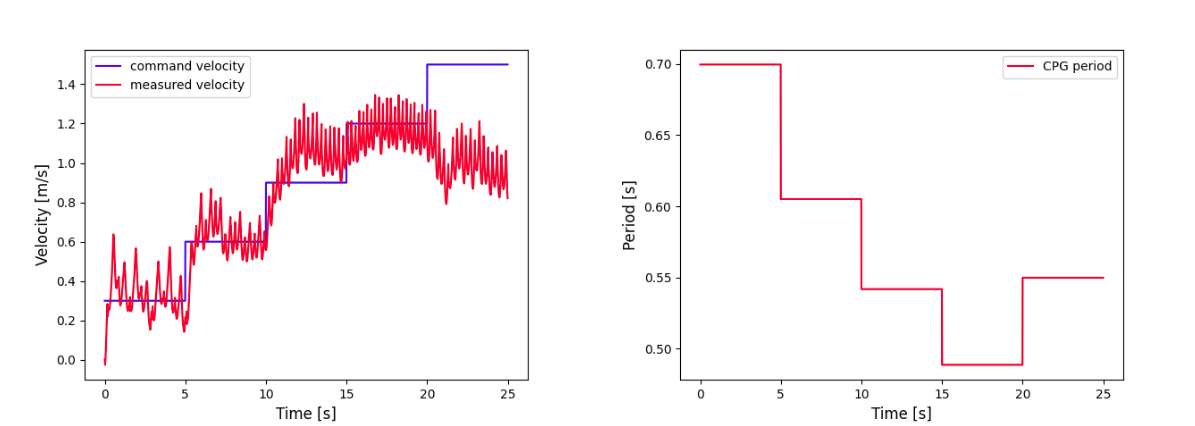
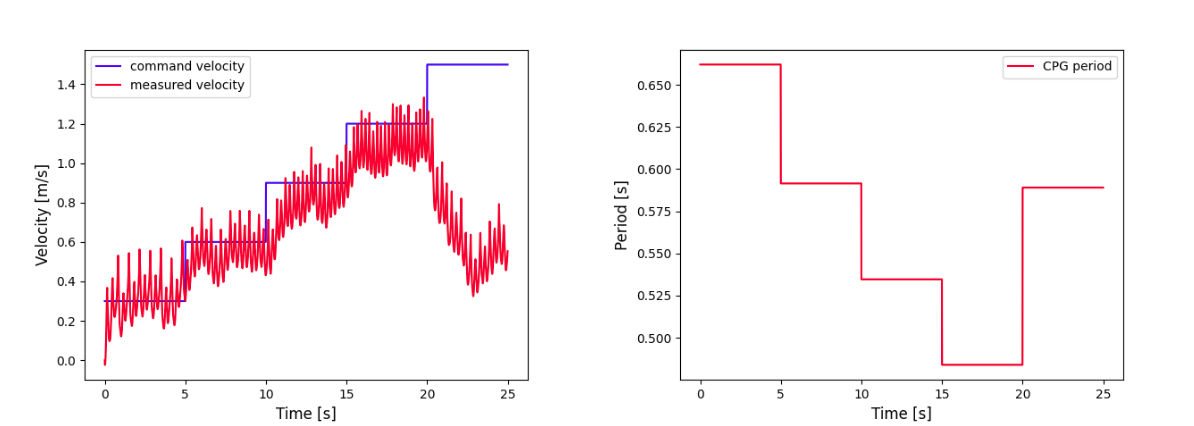
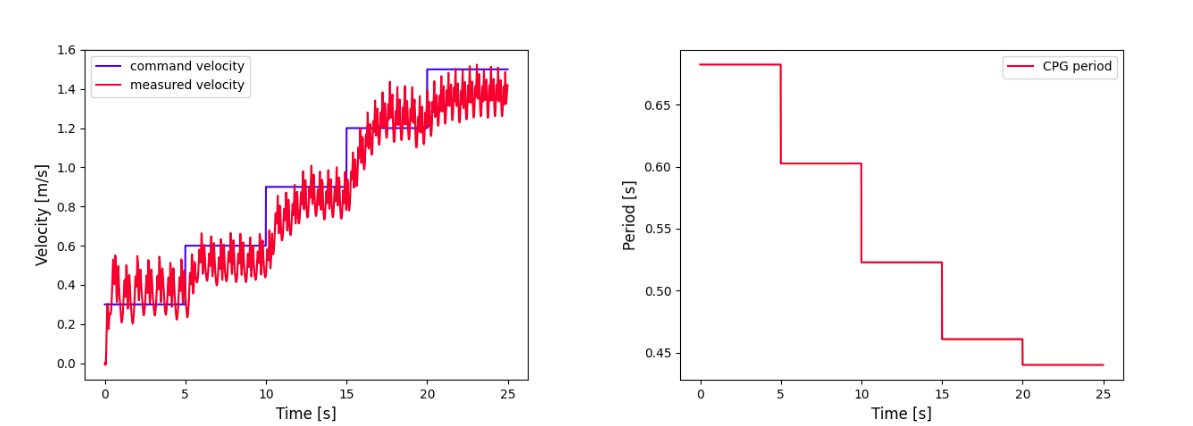
Figure 8: Trot.

