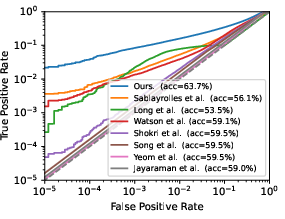
- The paper introduces LiRA, a likelihood ratio attack that boosts true-positive rates by a factor of 10 at low false-positive rates.
- It leverages Gaussian modeling and multiple shadow models to distinguish training data from non-members with high precision.
- The study provides practical insights for privacy auditing and model robustness testing, despite increased computational demands.
Detailed Summary of "Membership Inference Attacks From First Principles" (2112.03570)
Introduction to the Problem
The paper "Membership Inference Attacks From First Principles" (2112.03570) explores the field of membership inference attacks (MIAs), which enable adversaries to determine whether specific data points were part of a model's training dataset. These attacks present significant privacy risks, especially when models are trained on sensitive information. Traditional evaluations use average-case metrics like accuracy; however, this paper argues for a more robust focus on true-positive rates (TPRs) at very low false-positive rates (FPRs), asserting that it's crucial to evaluate the attack's capability to confidently identify members, even in worst-case scenarios.
Contributions and Methodology
The authors introduce a novel Likelihood Ratio Attack (LiRA) that systematically integrates principles from previous research, enhancing efficacy by tenfold at low FPRs, compared to prior art. The attack hinges on several critical ideas:
Implementation Insights
To implement the LiRA, several steps are followed:
- Training Shadow Models: Train multiple shadow models on the dataset to estimate the statistical distribution of losses for training vs. non-training data points. These serve as a reference distribution.
- Gaussian Modeling: The shadows' predictions are modeled as Gaussian distributions, simplifying the formulation and execution of hypothesis testing on whether an example was in the training set.
- Scalable Evaluation: The attack requires training computationally substantial shadow models, thus scalability can be challenging but offers precise control over membership inference accuracy.
Python or other ML frameworks can structure this attack using libraries that handle Gaussian fitting and sophisticated model training pipelines.
Practical Applications
- Privacy Auditing: LiRA can precisely audit models for privacy risks, guiding enhancements to privacy-preserving methods.
- Testing Robustness: Developers can use MIAs to validate the resilience of models against privacy threats, identifying potential vulnerabilities in different configurations.
LiRA achieves remarkable success in low FPR scenarios, but at the expense of computational overhead due to the need for extensive shadow model training.
- Computational Resources: This attack predominantly requires robust computational resources due to the training of multiple shadow models.
- Trade-offs in Accuracy: While the attack maximizes TPR at low FPRs, it may still be necessary to balance computational load versus the evaluated precision of privacy threats.
Conclusion and Future Directions
LiRA emphasizes the need for revisiting previous MIA evaluations, supporting a shift towards low-FPR evaluations that genuinely reflect privacy vulnerabilities. Future work could streamline computational requirements or apply the underlying principles to derivative privacy-based attacks, potentially offering broader applications across privacy-oriented AI applications and systems.
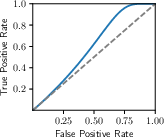
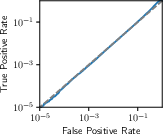
Figure 2: Success rate of our attack across various datasets, illustrating consistency in achieving high TPR at low FPRs.