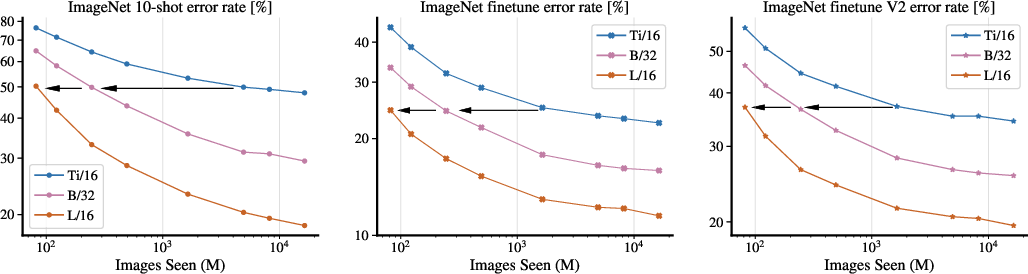
- The paper presents a performance-compute frontier for Vision Transformers by scaling model size, dataset, and computation together.
- It demonstrates that larger models achieve higher sample efficiency, reaching up to 84.86% top-1 accuracy on ImageNet with few-shot evaluation.
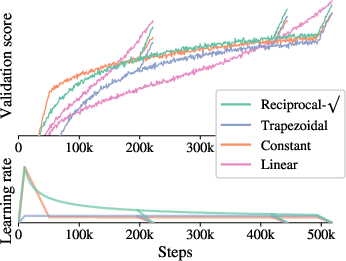
- The study introduces innovations like decoupled weight decay, memory-efficient strategies, and infinite learning-rate schedules to enhance training.
This essay provides an in-depth review of "Scaling Vision Transformers" (2106.04560), focusing on the scaling behaviors and performance improvements of Vision Transformer (ViT) models. This paper explores the scaling of ViTs in terms of model size, dataset size, and computational budget, presenting detailed experimental results and novel methodologies that advance state-of-the-art performance in image classification tasks.
Introduction and Core Contributions
The paper extensively investigates the scaling laws applicable to Vision Transformers, which have shown remarkable performance akin to their success in the NLP domain. Unlike the NLP models, where unsupervised pre-training dominates, ViTs rely more on supervised techniques. The study systematically increases the number of parameters up to two billion and data size to three billion images, demonstrating key insights into the model scaling frontier for visual tasks.
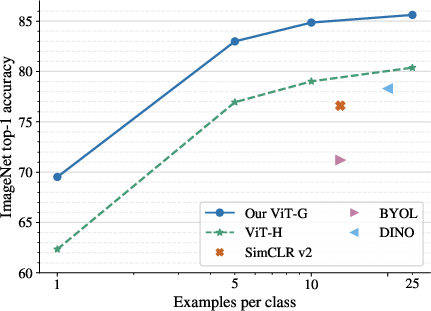
Figure 1: Few-shot transfer results. Our ViT-G model reaches 84.86\% top-1 accuracy on ImageNet with 10-shot linear evaluation.
The paper's primary contribution is the characterization of the performance-compute frontier for ViTs, emphasizing the requirement for simultaneous scaling of compute and model size to optimize performance. Moreover, it refines training techniques and architectural design, significantly boosting memory efficiency and model accuracy.
Scaling Dynamics
Key experiments reveal how compute, model, and data size interact:
- Scaling Up Together: Models display improved representation quality when data size, model complexity, and training compute are simultaneously increased. However, saturation occurs at larger sizes, hinting at diminishing returns despite increased resources.
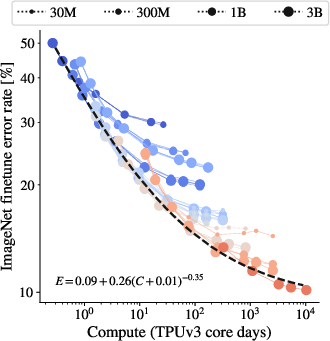
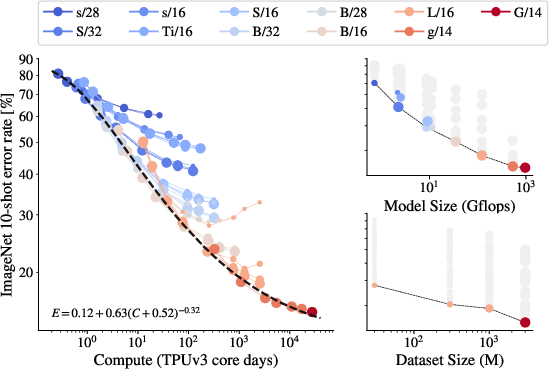
Figure 2: Representation quality as a function of total training compute, illustrating a saturating power-law frontier.
Methodological Improvements
Significant architectural and training procedural refinements include:
- Decoupled Weight Decay: Adjusting weight decay independently for the model's head and body enhances few-shot learning capabilities without compromising pre-training performance.
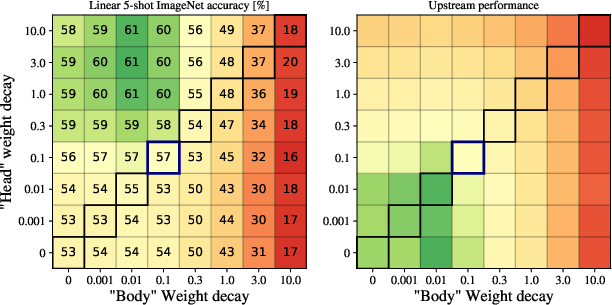
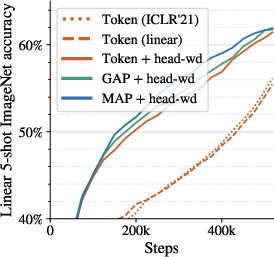
Figure 4: Dependence of few-shot ImageNet accuracy on weight decay strength, showing improvements with decoupled values for head and body.
Implications and Future Directions
The findings hold substantial implications for the application and future research of ViTs in visual recognition tasks. By elucidating the nuances of scaling laws and providing a framework for efficient large-scale model training, this study paves the way for further developments in efficiently deploying massive ViT models in diverse real-world contexts. Future explorations could further generalize these concepts to other visual domains or integrate with hybrid architectures that blend CNNs and Transformers.
Conclusion
The research delineates the critical elements necessary to harness the full potential of Vision Transformers through methodical scaling, innovative training strategies, and comprehensive evaluation. These insights provide a robust foundation for the continued advancement and application of ViT models across increasingly complex visual tasks.